 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Modal AI System for Screening Mammography: Integrating 2D and 3D Imaging to Improve Breast Cancer Detection in a Prospective Clinical Study
Apr 08, 2025
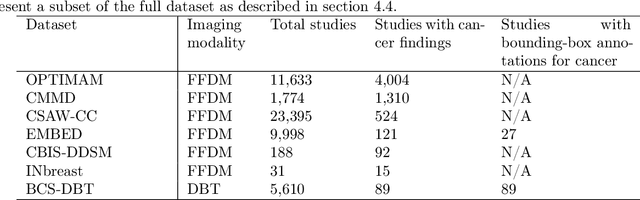
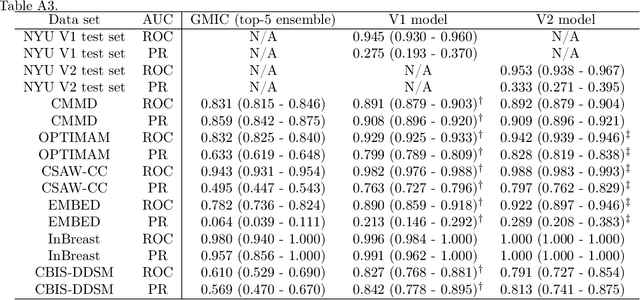
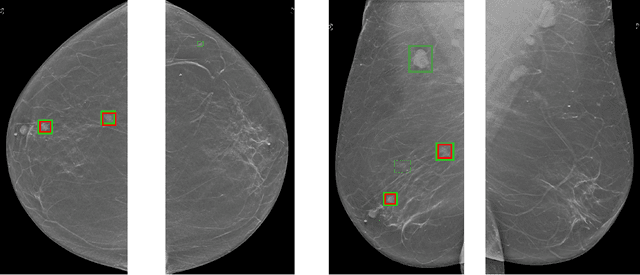
Although digital breast tomosynthesis (DBT) improves diagnostic performance over full-field digital mammography (FFDM), false-positive recalls remain a concern in breast cancer screening. We developed a multi-modal artificial intelligence system integrating FFDM, synthetic mammography, and DBT to provide breast-level predictions and bounding-box localizations of suspicious findings. Our AI system, trained on approximately 500,000 mammography exams, achieved 0.945 AUROC on an internal test set. It demonstrated capacity to reduce recalls by 31.7% and radiologist workload by 43.8% while maintaining 100% sensitivity, underscoring its potential to improve clinical workflows. External validation confirmed strong generalizability, reducing the gap to a perfect AUROC by 35.31%-69.14% relative to strong baselines. In prospective deployment across 18 sites, the system reduced recall rates for low-risk cases. An improved version, trained on over 750,000 exams with additional labels, further reduced the gap by 18.86%-56.62% across large external datasets. Overall, these results underscore the importance of utilizing all available imaging modalities, demonstrate the potential for clinical impact, and indicate feasibility of further reduction of the test error with increased training set when using large-capacity neural networks.
Understanding differences in applying DETR to natural and medical images
May 27, 2024Transformer-based detectors have shown success in computer vision tasks with natural images. These models, exemplified by the Deformable DETR, are optimized through complex engineering strategies tailored to the typical characteristics of natural scenes. However, medical imaging data presents unique challenges such as extremely large image sizes, fewer and smaller regions of interest, and object classes which can be differentiated only through subtle differences. This study evaluates the applicability of these transformer-based design choices when applied to a screening mammography dataset that represents these distinct medical imaging data characteristics. Our analysis reveals that common design choices from the natural image domain, such as complex encoder architectures, multi-scale feature fusion, query initialization, and iterative bounding box refinement, do not improve and sometimes even impair object detection performance in medical imaging. In contrast, simpler and shallower architectures often achieve equal or superior results. This finding suggests that the adaptation of transformer models for medical imaging data requires a reevaluation of standard practices, potentially leading to more efficient and specialized frameworks for medical diagnosis.
3D-GMIC: an efficient deep neural network to find small objects in large 3D images
Oct 16, 2022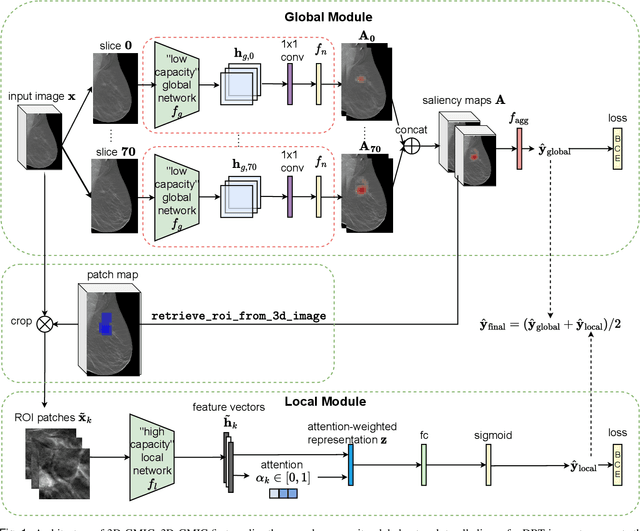
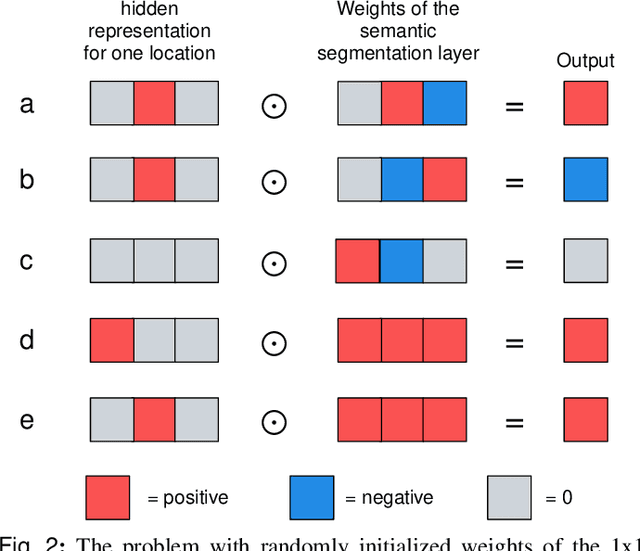
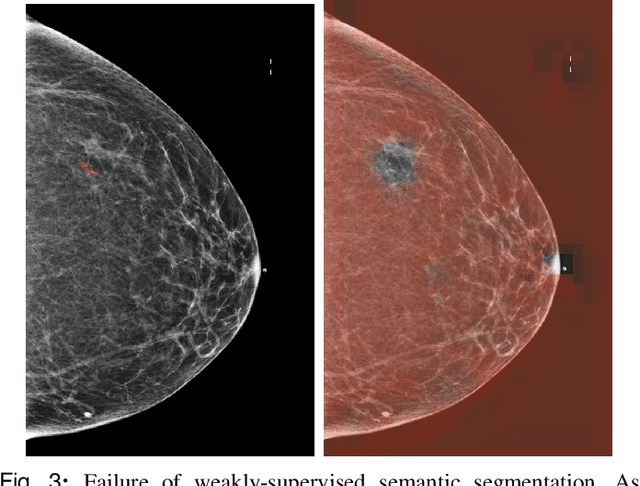
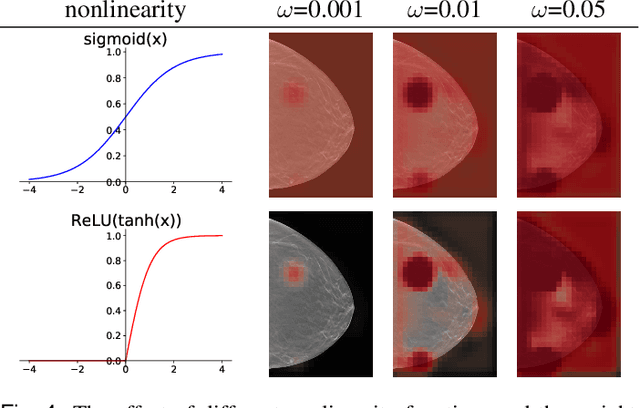
3D imaging enables a more accurate diagnosis by providing spatial information about organ anatomy. However, using 3D images to train AI models is computationally challenging because they consist of tens or hundreds of times more pixels than their 2D counterparts. To train with high-resolution 3D images, convolutional neural networks typically resort to downsampling them or projecting them to two dimensions. In this work, we propose an effective alternative, a novel neural network architecture that enables computationally efficient classification of 3D medical images in their full resolution. Compared to off-the-shelf convolutional neural networks, 3D-GMIC uses 77.98%-90.05% less GPU memory and 91.23%-96.02% less computation. While our network is trained only with image-level labels, without segmentation labels, it explains its classification predictions by providing pixel-level saliency maps. On a dataset collected at NYU Langone Health, including 85,526 patients with full-field 2D mammography (FFDM), synthetic 2D mammography, and 3D mammography (DBT), our model, the 3D Globally-Aware Multiple Instance Classifier (3D-GMIC), achieves a breast-wise AUC of 0.831 (95% CI: 0.769-0.887) in classifying breasts with malignant findings using DBT images. As DBT and 2D mammography capture different information, averaging predictions on 2D and 3D mammography together leads to a diverse ensemble with an improved breast-wise AUC of 0.841 (95% CI: 0.768-0.895). Our model generalizes well to an external dataset from Duke University Hospital, achieving an image-wise AUC of 0.848 (95% CI: 0.798-0.896) in classifying DBT images with malignant findings.