 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSatellite-Based Detection of Looted Archaeological Sites Using Machine Learning
Feb 23, 2026Looting at archaeological sites poses a severe risk to cultural heritage, yet monitoring thousands of remote locations remains operationally difficult. We present a scalable and satellite-based pipeline to detect looted archaeological sites, using PlanetScope monthly mosaics (4.7m/pixel) and a curated dataset of 1,943 archaeological sites in Afghanistan (898 looted, 1,045 preserved) with multi-year imagery (2016--2023) and site-footprint masks. We compare (i) end-to-end CNN classifiers trained on raw RGB patches and (ii) traditional machine learning (ML) trained on handcrafted spectral/texture features and embeddings from recent remote-sensing foundation models. Results indicate that ImageNet-pretrained CNNs combined with spatial masking reach an F1 score of 0.926, clearly surpassing the strongest traditional ML setup, which attains an F1 score of 0.710 using SatCLIP-V+RF+Mean, i.e., location and vision embeddings fed into a Random Forest with mean-based temporal aggregation. Ablation studies demonstrate that ImageNet pretraining (even in the presence of domain shift) and spatial masking enhance performance. In contrast, geospatial foundation model embeddings perform competitively with handcrafted features, suggesting that looting signatures are extremely localized. The repository is available at https://github.com/microsoft/looted_site_detection.
TEMPO: Global Temporal Building Density and Height Estimation from Satellite Imagery
Nov 15, 2025We present TEMPO, a global, temporally resolved dataset of building density and height derived from high-resolution satellite imagery using deep learning models. We pair building footprint and height data from existing datasets with quarterly PlanetScope basemap satellite images to train a multi-task deep learning model that predicts building density and building height at a 37.6-meter per pixel resolution. We apply this model to global PlanetScope basemaps from Q1 2018 through Q2 2025 to create global, temporal maps of building density and height. We validate these maps by comparing against existing building footprint datasets. Our estimates achieve an F1 score between 85% and 88% on different hand-labeled subsets, and are temporally stable, with a 0.96 five-year trend-consistency score. TEMPO captures quarterly changes in built settlements at a fraction of the computational cost of comparable approaches, unlocking large-scale monitoring of development patterns and climate impacts essential for global resilience and adaptation efforts.
Optimizing Cloud-to-GPU Throughput for Deep Learning With Earth Observation Data
Jun 06, 2025



Training deep learning models on petabyte-scale Earth observation (EO) data requires separating compute resources from data storage. However, standard PyTorch data loaders cannot keep modern GPUs utilized when streaming GeoTIFF files directly from cloud storage. In this work, we benchmark GeoTIFF loading throughput from both cloud object storage and local SSD, systematically testing different loader configurations and data parameters. We focus on tile-aligned reads and worker thread pools, using Bayesian optimization to find optimal settings for each storage type. Our optimized configurations increase remote data loading throughput by 20x and local throughput by 4x compared to default settings. On three public EO benchmarks, models trained with optimized remote loading achieve the same accuracy as local training within identical time budgets. We improve validation IoU by 6-15% and maintain 85-95% GPU utilization versus 0-30% with standard configurations. Code is publicly available at https://github.com/microsoft/pytorch-cloud-geotiff-optimization
GeoVision Labeler: Zero-Shot Geospatial Classification with Vision and Language Models
May 30, 2025Classifying geospatial imagery remains a major bottleneck for applications such as disaster response and land-use monitoring-particularly in regions where annotated data is scarce or unavailable. Existing tools (e.g., RS-CLIP) that claim zero-shot classification capabilities for satellite imagery nonetheless rely on task-specific pretraining and adaptation to reach competitive performance. We introduce GeoVision Labeler (GVL), a strictly zero-shot classification framework: a vision Large Language Model (vLLM) generates rich, human-readable image descriptions, which are then mapped to user-defined classes by a conventional Large Language Model (LLM). This modular, and interpretable pipeline enables flexible image classification for a large range of use cases. We evaluated GVL across three benchmarks-SpaceNet v7, UC Merced, and RESISC45. It achieves up to 93.2% zero-shot accuracy on the binary Buildings vs. No Buildings task on SpaceNet v7. For complex multi-class classification tasks (UC Merced, RESISC45), we implemented a recursive LLM-driven clustering to form meta-classes at successive depths, followed by hierarchical classification-first resolving coarse groups, then finer distinctions-to deliver competitive zero-shot performance. GVL is open-sourced at https://github.com/microsoft/geo-vision-labeler to catalyze adoption in real-world geospatial workflows.
Distribution Shifts at Scale: Out-of-distribution Detection in Earth Observation
Dec 18, 2024Training robust deep learning models is critical in Earth Observation, where globally deployed models often face distribution shifts that degrade performance, especially in low-data regions. Out-of-distribution (OOD) detection addresses this challenge by identifying inputs that differ from in-distribution (ID) data. However, existing methods either assume access to OOD data or compromise primary task performance, making them unsuitable for real-world deployment. We propose TARDIS, a post-hoc OOD detection method for scalable geospatial deployments. The core novelty lies in generating surrogate labels by integrating information from ID data and unknown distributions, enabling OOD detection at scale. Our method takes a pre-trained model, ID data, and WILD samples, disentangling the latter into surrogate ID and surrogate OOD labels based on internal activations, and fits a binary classifier as an OOD detector. We validate TARDIS on EuroSAT and xBD datasets, across 17 experimental setups covering covariate and semantic shifts, showing that it performs close to the theoretical upper bound in assigning surrogate ID and OOD samples in 13 cases. To demonstrate scalability, we deploy TARDIS on the Fields of the World dataset, offering actionable insights into pre-trained model behavior for large-scale deployments. The code is publicly available at https://github.com/microsoft/geospatial-ood-detection.
Sims: An Interactive Tool for Geospatial Matching and Clustering
Dec 13, 2024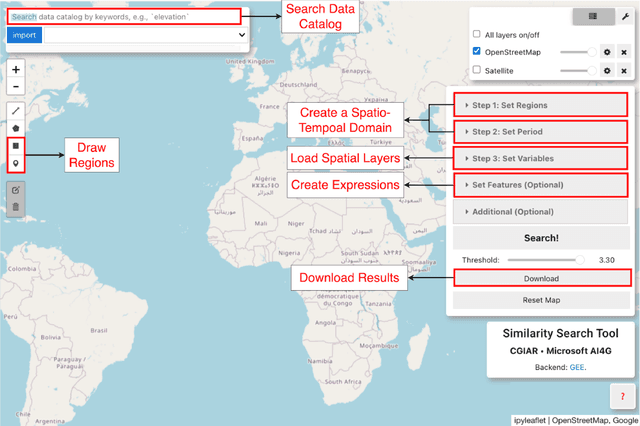
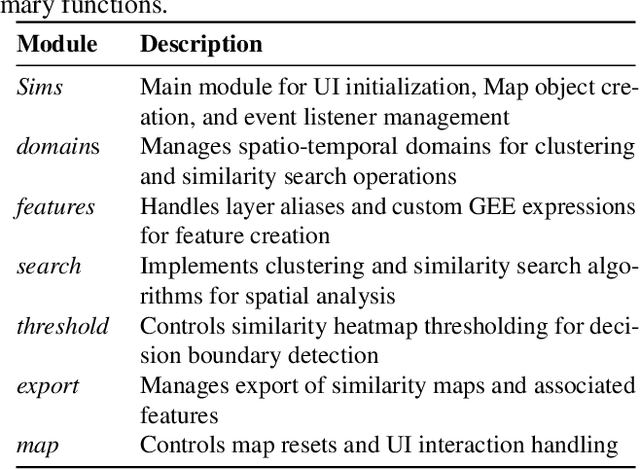
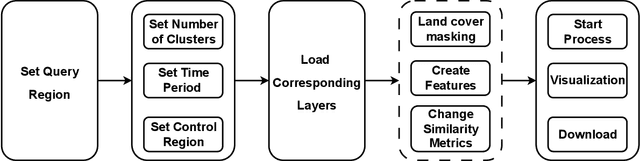
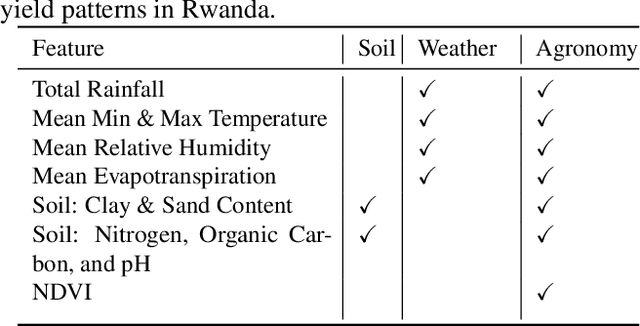
Acquiring, processing, and visualizing geospatial data requires significant computing resources, especially for large spatio-temporal domains. This challenge hinders the rapid discovery of predictive features, which is essential for advancing geospatial modeling. To address this, we developed Similarity Search (Sims), a no-code web tool that allows users to visualize, compare, cluster, and perform similarity search over defined regions of interest using Google Earth Engine as a backend. Sims is designed to complement existing modeling tools by focusing on feature exploration rather than model creation. We demonstrate the utility of Sims through a case study analyzing simulated maize yield data in Rwanda, where we evaluate how different combinations of soil, weather, and agronomic features affect the clustering of yield response zones. Sims is open source and available at https://github.com/microsoft/Sims
Local vs. Global: Local Land-Use and Land-Cover Models Deliver Higher Quality Maps
Dec 01, 2024



Approximately 20% of Africa's population suffered from undernourishment, and 868 million people experienced moderate to severe food insecurity in 2022. Land-use and land-cover maps provide crucial insights for addressing food insecurity, e.g., by mapping croplands. The development of global land-cover maps has been facilitated by the increasing availability of earth observation data and advancements in geospatial machine learning. However, these global maps exhibit lower accuracy and inconsistencies in Africa, partly due to the lack of representative training data. To address this issue, we propose a data-centric framework with a teacher-student model setup, which uses diverse data sources of satellite images and label examples to produce local land-cover maps. Our method trains a high-resolution teacher model on images with a resolution of 0.331 m/pixel and a low-resolution student model on publicly available images with a resolution of 10 m/pixel. The student model also utilizes the teacher model's output as its weak label examples through knowledge distillation. We evaluated our framework using Murang'a County, Kenya, as a use case and achieved significant improvements, i.e., 0.14 in the F1 score and 0.21 in Intersection-over-Union, compared to the best global map. Our evaluation also revealed inconsistencies in existing global maps, with a maximum agreement rate of 0.30 among themselves. Insights obtained from our cross-collaborative work can provide valuable guidance to local and national policymakers in making informed decisions to improve resource utilization and food security.
AI and the Future of Work in Africa White Paper
Nov 15, 2024
This white paper is the output of a multidisciplinary workshop in Nairobi (Nov 2023). Led by a cross-organisational team including Microsoft Research, NEPAD, Lelapa AI, and University of Oxford. The workshop brought together diverse thought-leaders from various sectors and backgrounds to discuss the implications of Generative AI for the future of work in Africa. Discussions centred around four key themes: Macroeconomic Impacts; Jobs, Skills and Labour Markets; Workers' Perspectives and Africa-Centris AI Platforms. The white paper provides an overview of the current state and trends of generative AI and its applications in different domains, as well as the challenges and risks associated with its adoption and regulation. It represents a diverse set of perspectives to create a set of insights and recommendations which aim to encourage debate and collaborative action towards creating a dignified future of work for everyone across Africa.
Analyzing Decades-Long Environmental Changes in Namibia Using Archival Aerial Photography and Deep Learning
Apr 12, 2024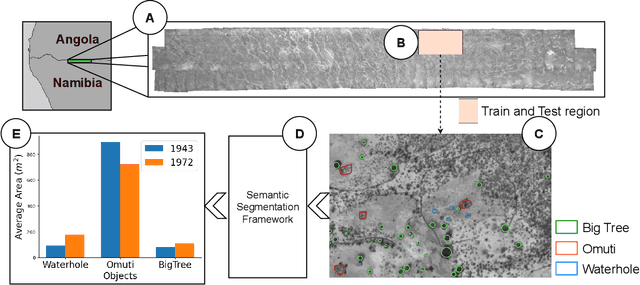

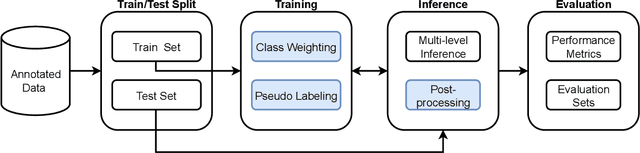
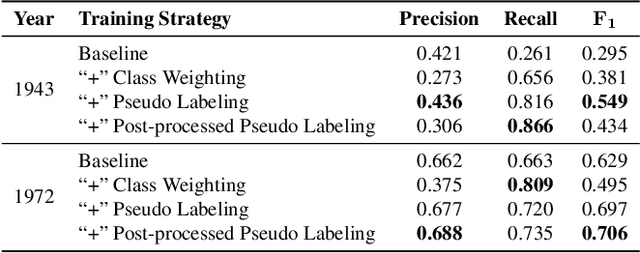
This study explores object detection in historical aerial photographs of Namibia to identify long-term environmental changes. Specifically, we aim to identify key objects -- \textit{Waterholes}, \textit{Omuti homesteads}, and \textit{Big trees} -- around Oshikango in Namibia using sub-meter gray-scale aerial imagery from 1943 and 1972. In this work, we propose a workflow for analyzing historical aerial imagery using a deep semantic segmentation model on sparse hand-labels. To this end, we employ a number of strategies including class-weighting, pseudo-labeling and empirical p-value-based filtering to balance skewed and sparse representations of objects in the ground truth data. Results demonstrate the benefits of these different training strategies resulting in an average $F_1=0.661$ and $F_1=0.755$ over the three objects of interest for the 1943 and 1972 imagery, respectively. We also identified that the average size of Waterhole and Big trees increased while the average size of Omutis decreased between 1943 and 1972 reflecting some of the local effects of the massive post-Second World War economic, agricultural, demographic, and environmental changes. This work also highlights the untapped potential of historical aerial photographs in understanding long-term environmental changes beyond Namibia (and Africa). With the lack of adequate satellite technology in the past, archival aerial photography offers a great alternative to uncover decades-long environmental changes.
Weak Labeling for Cropland Mapping in Africa
Jan 13, 2024

Cropland mapping can play a vital role in addressing environmental, agricultural, and food security challenges. However, in the context of Africa, practical applications are often hindered by the limited availability of high-resolution cropland maps. Such maps typically require extensive human labeling, thereby creating a scalability bottleneck. To address this, we propose an approach that utilizes unsupervised object clustering to refine existing weak labels, such as those obtained from global cropland maps. The refined labels, in conjunction with sparse human annotations, serve as training data for a semantic segmentation network designed to identify cropland areas. We conduct experiments to demonstrate the benefits of the improved weak labels generated by our method. In a scenario where we train our model with only 33 human-annotated labels, the F_1 score for the cropland category increases from 0.53 to 0.84 when we add the mined negative labels.