 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Task Aggregation for Generalizable Ultrasound Foundation Models
Mar 18, 2026Foundation models promise to unify multiple clinical tasks within a single framework, but recent ultrasound studies report that unified models can underperform task-specific baselines. We hypothesize that this degradation arises not from model capacity limitations, but from task aggregation strategies that ignore interactions between task heterogeneity and available training data scale. In this work, we systematically analyze when heterogeneous ultrasound tasks can be jointly learned without performance loss, establishing practical criteria for task aggregation in unified clinical imaging models. We introduce M2DINO, a multi-organ, multi-task framework built on DINOv3 with task-conditioned Mixture-of-Experts blocks for adaptive capacity allocation. We systematically evaluate 27 ultrasound tasks spanning segmentation, classification, detection, and regression under three paradigms: task-specific, clinically-grouped, and all-task unified training. Our results show that aggregation effectiveness depends strongly on training data scale. While clinically-grouped training can improve performance in data-rich settings, it may induce substantial negative transfer in low-data settings. In contrast, all-task unified training exhibits more consistent performance across clinical groups. We further observe that task sensitivity varies by task type in our experiments: segmentation shows the largest performance drops compared with regression and classification. These findings provide practical guidance for ultrasound foundation models, emphasizing that aggregation strategies should jointly consider training data availability and task characteristics rather than relying on clinical taxonomy alone.
Efficient Representation of the Activation Space in Deep Neural Networks
Dec 13, 2023
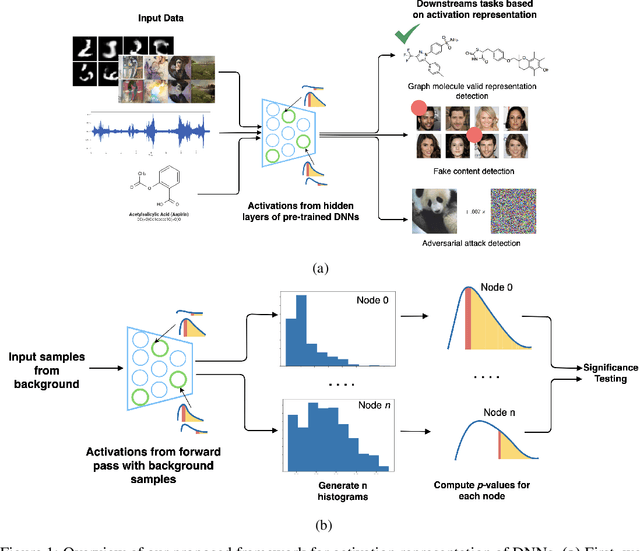

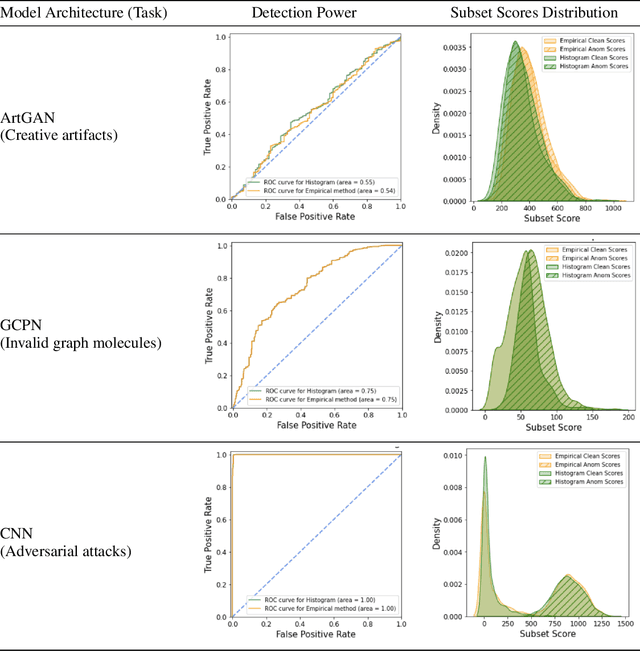
The representations of the activation space of deep neural networks (DNNs) are widely utilized for tasks like natural language processing, anomaly detection and speech recognition. Due to the diverse nature of these tasks and the large size of DNNs, an efficient and task-independent representation of activations becomes crucial. Empirical p-values have been used to quantify the relative strength of an observed node activation compared to activations created by already-known inputs. Nonetheless, keeping raw data for these calculations increases memory resource consumption and raises privacy concerns. To this end, we propose a model-agnostic framework for creating representations of activations in DNNs using node-specific histograms to compute p-values of observed activations without retaining already-known inputs. Our proposed approach demonstrates promising potential when validated with multiple network architectures across various downstream tasks and compared with the kernel density estimates and brute-force empirical baselines. In addition, the framework reduces memory usage by 30% with up to 4 times faster p-value computing time while maintaining state of-the-art detection power in downstream tasks such as the detection of adversarial attacks and synthesized content. Moreover, as we do not persist raw data at inference time, we could potentially reduce susceptibility to attacks and privacy issues.
Weakly Supervised Detection of Hallucinations in LLM Activations
Dec 05, 2023



We propose an auditing method to identify whether a large language model (LLM) encodes patterns such as hallucinations in its internal states, which may propagate to downstream tasks. We introduce a weakly supervised auditing technique using a subset scanning approach to detect anomalous patterns in LLM activations from pre-trained models. Importantly, our method does not need knowledge of the type of patterns a-priori. Instead, it relies on a reference dataset devoid of anomalies during testing. Further, our approach enables the identification of pivotal nodes responsible for encoding these patterns, which may offer crucial insights for fine-tuning specific sub-networks for bias mitigation. We introduce two new scanning methods to handle LLM activations for anomalous sentences that may deviate from the expected distribution in either direction. Our results confirm prior findings of BERT's limited internal capacity for encoding hallucinations, while OPT appears capable of encoding hallucination information internally. Importantly, our scanning approach, without prior exposure to false statements, performs comparably to a fully supervised out-of-distribution classifier.