 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval with Multiple Query Vectors through Anomalous Pattern Detection
May 03, 2026A classical vector retrieval problem typically considers a \emph{single} query embedding vector as input and retrieves the most similar embedding vectors from a vector database. However, complex reasoning and retrieval tasks frequently require \emph{multiple query vectors}, rather than a single one. In this work, we propose a retrieval method that considers multiple query vectors simultaneously and retrieves the most relevant vectors from the database using concepts from anomalous pattern detection. Specifically, our approach leverages a set of query vectors $Q$ (with $|Q|\geq 1$), and identifies the subset of vector dimensions within $Q$ that standout (anomalous) from the rest of dimensions. Next, we scan the vector database to retrieve the set of vectors that are also anomalous across the previously identified vector dimensions and return them as our retrieved set of vectors. We validate our approach on two image datasets, a text dataset, and a tabular dataset. Overall, we observe that, across most datasets, larger query sets lead to improved retrieval performance. The improvement is most pronounced when increasing the query sets from 1 to 8, while the gains become smaller beyond that.
Enabling Precise Topic Alignment in Large Language Models Via Sparse Autoencoders
Jun 14, 2025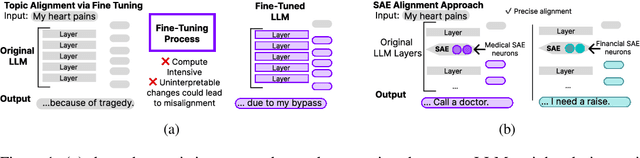



Recent work shows that Sparse Autoencoders (SAE) applied to large language model (LLM) layers have neurons corresponding to interpretable concepts. These SAE neurons can be modified to align generated outputs, but only towards pre-identified topics and with some parameter tuning. Our approach leverages the observational and modification properties of SAEs to enable alignment for any topic. This method 1) scores each SAE neuron by its semantic similarity to an alignment text and uses them to 2) modify SAE-layer-level outputs by emphasizing topic-aligned neurons. We assess the alignment capabilities of this approach on diverse public topic datasets including Amazon reviews, Medicine, and Sycophancy, across the currently available open-source LLMs and SAE pairs (GPT2 and Gemma) with multiple SAEs configurations. Experiments aligning to medical prompts reveal several benefits over fine-tuning, including increased average language acceptability (0.25 vs. 0.5), reduced training time across multiple alignment topics (333.6s vs. 62s), and acceptable inference time for many applications (+0.00092s/token). Our open-source code is available at github.com/IBM/sae-steering.
Localizing Persona Representations in LLMs
May 30, 2025We present a study on how and where personas -- defined by distinct sets of human characteristics, values, and beliefs -- are encoded in the representation space of large language models (LLMs). Using a range of dimension reduction and pattern recognition methods, we first identify the model layers that show the greatest divergence in encoding these representations. We then analyze the activations within a selected layer to examine how specific personas are encoded relative to others, including their shared and distinct embedding spaces. We find that, across multiple pre-trained decoder-only LLMs, the analyzed personas show large differences in representation space only within the final third of the decoder layers. We observe overlapping activations for specific ethical perspectives -- such as moral nihilism and utilitarianism -- suggesting a degree of polysemy. In contrast, political ideologies like conservatism and liberalism appear to be represented in more distinct regions. These findings help to improve our understanding of how LLMs internally represent information and can inform future efforts in refining the modulation of specific human traits in LLM outputs. Warning: This paper includes potentially offensive sample statements.
Efficient Representation of the Activation Space in Deep Neural Networks
Dec 13, 2023
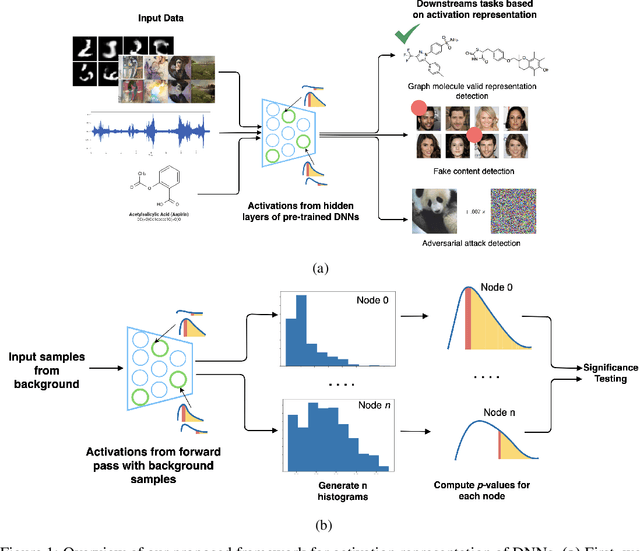

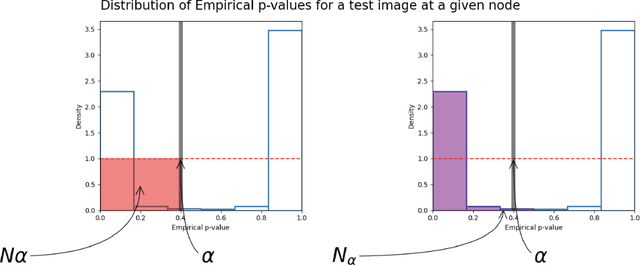
The representations of the activation space of deep neural networks (DNNs) are widely utilized for tasks like natural language processing, anomaly detection and speech recognition. Due to the diverse nature of these tasks and the large size of DNNs, an efficient and task-independent representation of activations becomes crucial. Empirical p-values have been used to quantify the relative strength of an observed node activation compared to activations created by already-known inputs. Nonetheless, keeping raw data for these calculations increases memory resource consumption and raises privacy concerns. To this end, we propose a model-agnostic framework for creating representations of activations in DNNs using node-specific histograms to compute p-values of observed activations without retaining already-known inputs. Our proposed approach demonstrates promising potential when validated with multiple network architectures across various downstream tasks and compared with the kernel density estimates and brute-force empirical baselines. In addition, the framework reduces memory usage by 30% with up to 4 times faster p-value computing time while maintaining state of-the-art detection power in downstream tasks such as the detection of adversarial attacks and synthesized content. Moreover, as we do not persist raw data at inference time, we could potentially reduce susceptibility to attacks and privacy issues.
Weakly Supervised Detection of Hallucinations in LLM Activations
Dec 05, 2023



We propose an auditing method to identify whether a large language model (LLM) encodes patterns such as hallucinations in its internal states, which may propagate to downstream tasks. We introduce a weakly supervised auditing technique using a subset scanning approach to detect anomalous patterns in LLM activations from pre-trained models. Importantly, our method does not need knowledge of the type of patterns a-priori. Instead, it relies on a reference dataset devoid of anomalies during testing. Further, our approach enables the identification of pivotal nodes responsible for encoding these patterns, which may offer crucial insights for fine-tuning specific sub-networks for bias mitigation. We introduce two new scanning methods to handle LLM activations for anomalous sentences that may deviate from the expected distribution in either direction. Our results confirm prior findings of BERT's limited internal capacity for encoding hallucinations, while OPT appears capable of encoding hallucination information internally. Importantly, our scanning approach, without prior exposure to false statements, performs comparably to a fully supervised out-of-distribution classifier.
Model-free feature selection to facilitate automatic discovery of divergent subgroups in tabular data
Mar 08, 2022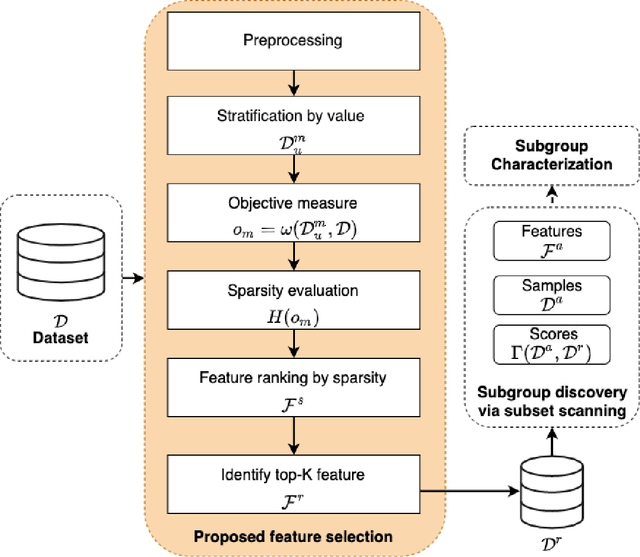
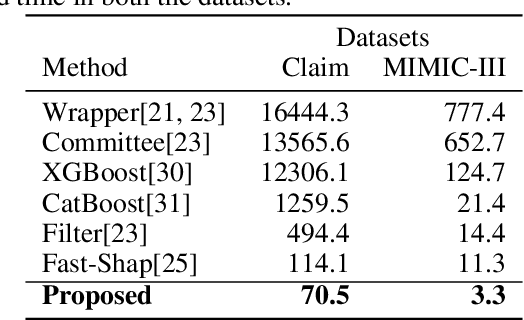
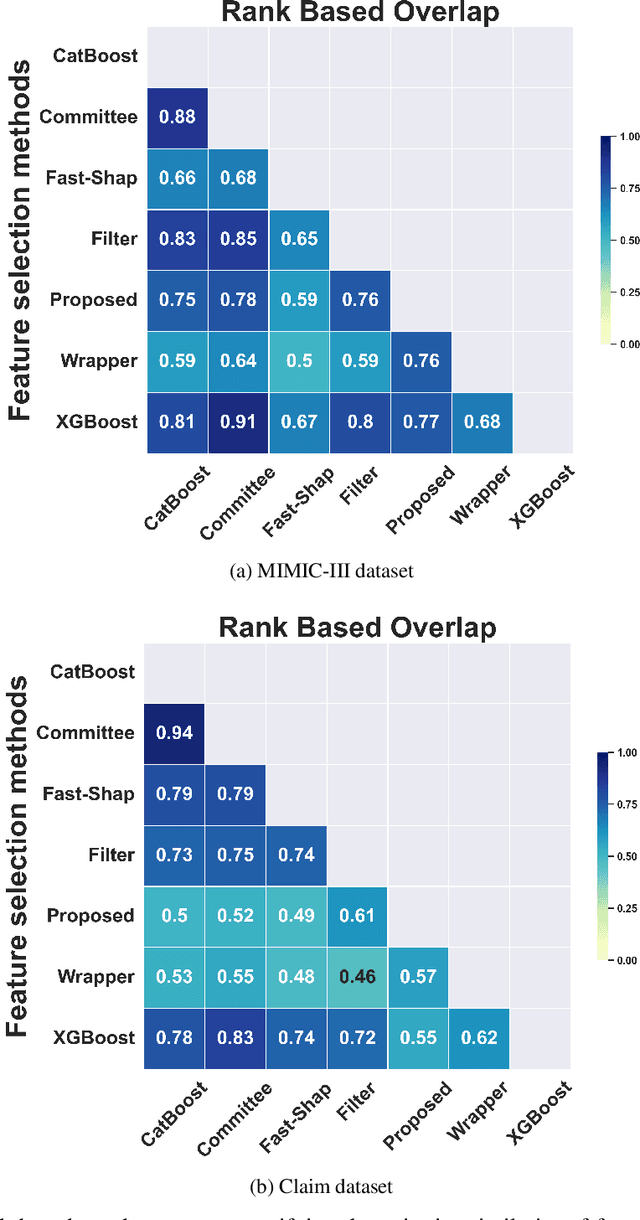
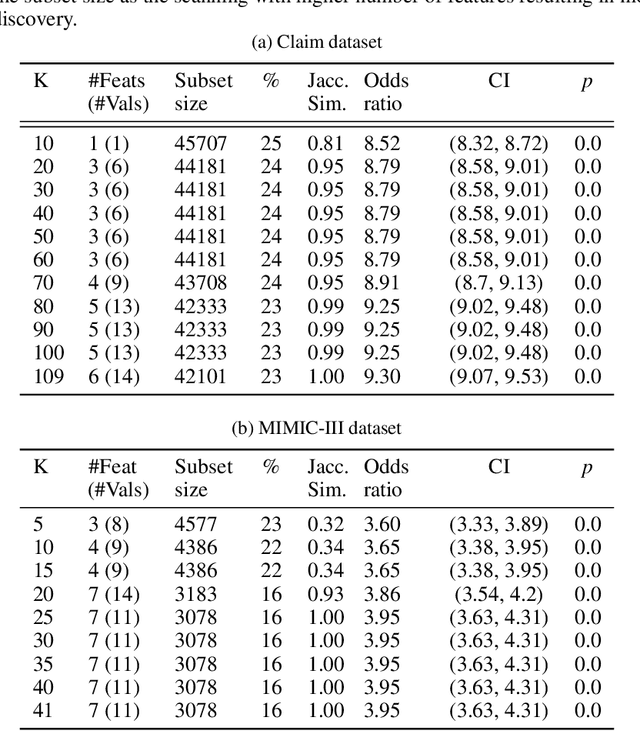
Data-centric AI encourages the need of cleaning and understanding of data in order to achieve trustworthy AI. Existing technologies, such as AutoML, make it easier to design and train models automatically, but there is a lack of a similar level of capabilities to extract data-centric insights. Manual stratification of tabular data per a feature (e.g., gender) is limited to scale up for higher feature dimension, which could be addressed using automatic discovery of divergent subgroups. Nonetheless, these automatic discovery techniques often search across potentially exponential combinations of features that could be simplified using a preceding feature selection step. Existing feature selection techniques for tabular data often involve fitting a particular model in order to select important features. However, such model-based selection is prone to model-bias and spurious correlations in addition to requiring extra resource to design, fine-tune and train a model. In this paper, we propose a model-free and sparsity-based automatic feature selection (SAFS) framework to facilitate automatic discovery of divergent subgroups. Different from filter-based selection techniques, we exploit the sparsity of objective measures among feature values to rank and select features. We validated SAFS across two publicly available datasets (MIMIC-III and Allstate Claims) and compared it with six existing feature selection methods. SAFS achieves a reduction of feature selection time by a factor of 81x and 104x, averaged cross the existing methods in the MIMIC-III and Claims datasets respectively. SAFS-selected features are also shown to achieve competitive detection performance, e.g., 18.3% of features selected by SAFS in the Claims dataset detected divergent samples similar to those detected by using the whole features with a Jaccard similarity of 0.95 but with a 16x reduction in detection time.
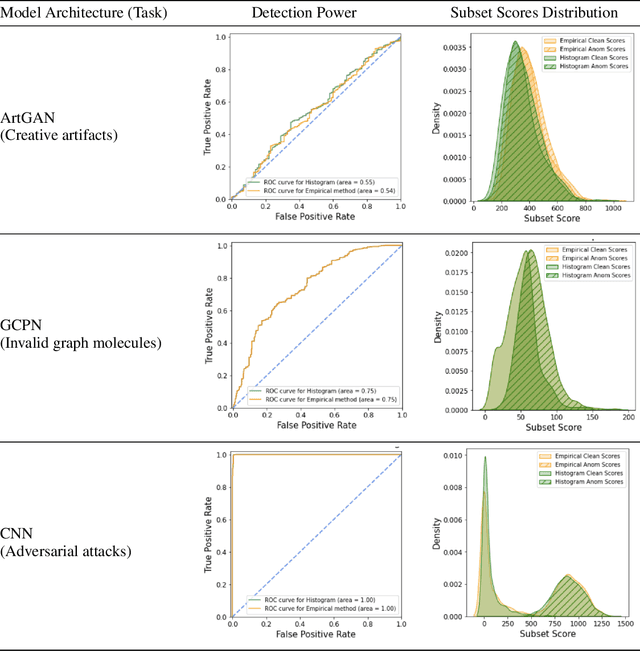
Towards Creativity Characterization of Generative Models via Group-based Subset Scanning
Mar 03, 2022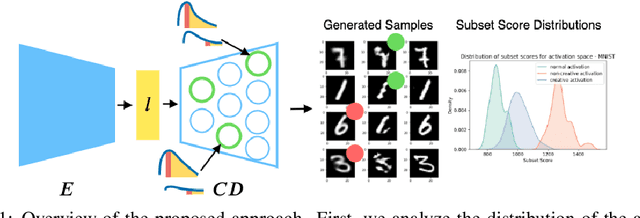
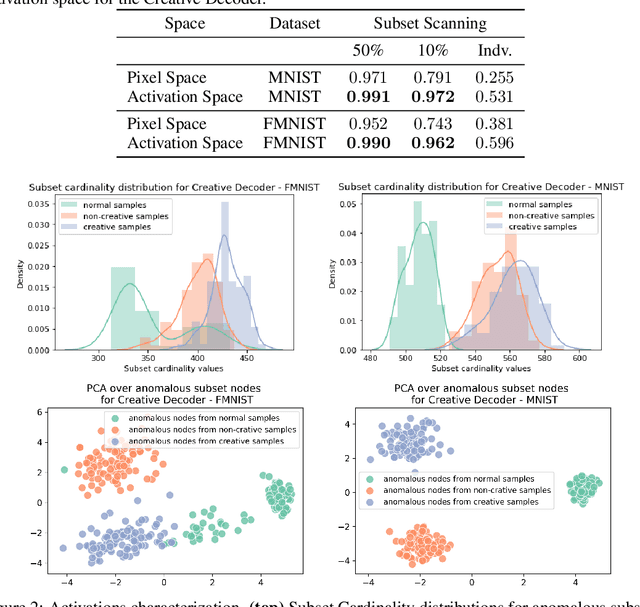
Deep generative models, such as Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs), have been employed widely in computational creativity research. However, such models discourage out-of-distribution generation to avoid spurious sample generation, thereby limiting their creativity. Thus, incorporating research on human creativity into generative deep learning techniques presents an opportunity to make their outputs more compelling and human-like. As we see the emergence of generative models directed toward creativity research, a need for machine learning-based surrogate metrics to characterize creative output from these models is imperative. We propose group-based subset scanning to identify, quantify, and characterize creative processes by detecting a subset of anomalous node-activations in the hidden layers of the generative models. Our experiments on the standard image benchmarks, and their "creatively generated" variants, reveal that the proposed subset scores distribution is more useful for detecting creative processes in the activation space rather than the pixel space. Further, we found that creative samples generate larger subsets of anomalies than normal or non-creative samples across datasets. The node activations highlighted during the creative decoding process are different from those responsible for the normal sample generation. Lastly, we assess if the images from the subsets selected by our method were also found creative by human evaluators, presenting a link between creativity perception in humans and node activations within deep neural nets.
Sparsity-based Feature Selection for Anomalous Subgroup Discovery
Jan 06, 2022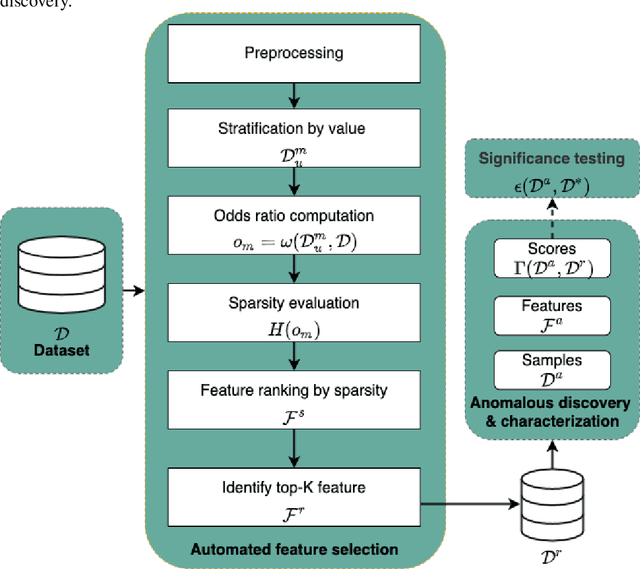
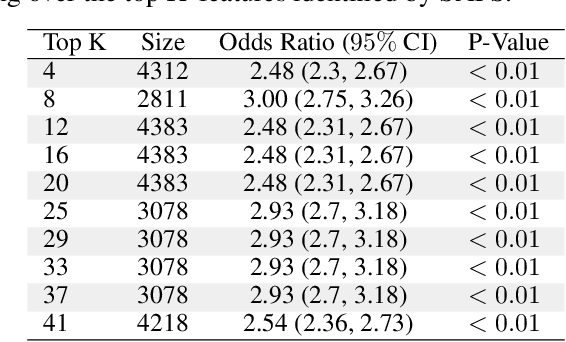
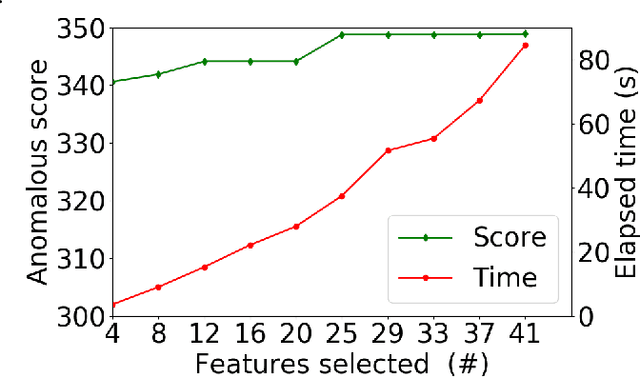
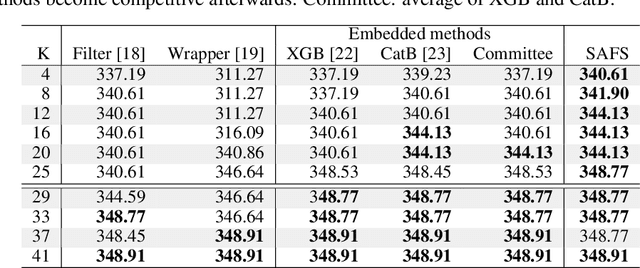
Anomalous pattern detection aims to identify instances where deviation from normalcy is evident, and is widely applicable across domains. Multiple anomalous detection techniques have been proposed in the state of the art. However, there is a common lack of a principled and scalable feature selection method for efficient discovery. Existing feature selection techniques are often conducted by optimizing the performance of prediction outcomes rather than its systemic deviations from the expected. In this paper, we proposed a sparsity-based automated feature selection (SAFS) framework, which encodes systemic outcome deviations via the sparsity of feature-driven odds ratios. SAFS is a model-agnostic approach with usability across different discovery techniques. SAFS achieves more than $3\times$ reduction in computation time while maintaining detection performance when validated on publicly available critical care dataset. SAFS also results in a superior performance when compared against multiple baselines for feature selection.
Out-of-Distribution Detection in Dermatology using Input Perturbation and Subset Scanning
Jun 02, 2021
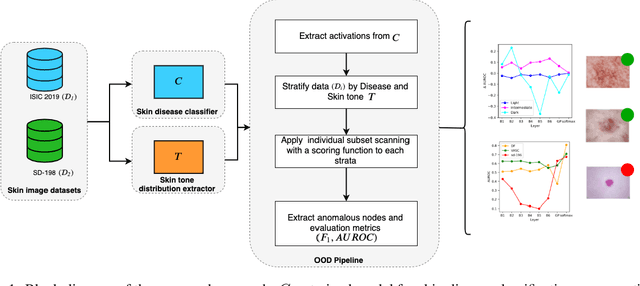
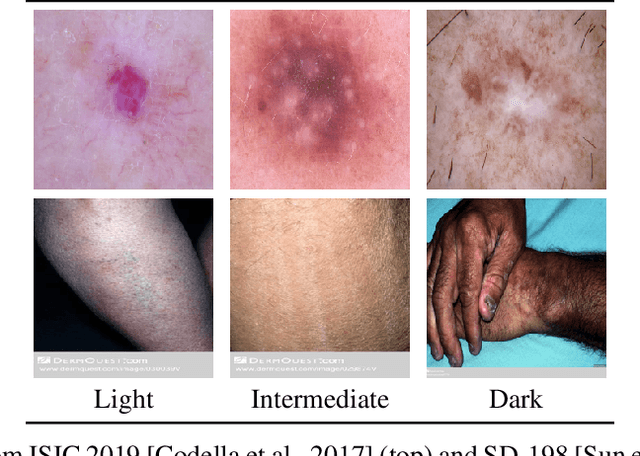
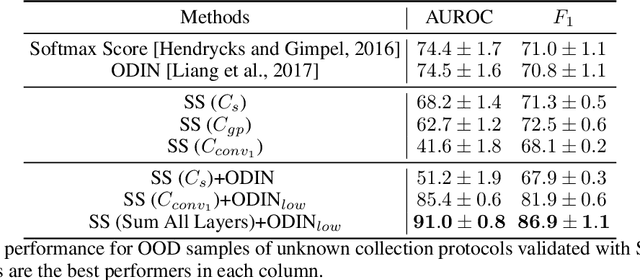
Recent advances in deep learning have led to breakthroughs in the development of automated skin disease classification. As we observe an increasing interest in these models in the dermatology space, it is crucial to address aspects such as the robustness towards input data distribution shifts. Current skin disease models could make incorrect inferences for test samples from different hardware devices and clinical settings or unknown disease samples, which are out-of-distribution (OOD) from the training samples. To this end, we propose a simple yet effective approach that detect these OOD samples prior to making any decision. The detection is performed via scanning in the latent space representation (e.g., activations of the inner layers of any pre-trained skin disease classifier). The input samples could also perturbed to maximise divergence of OOD samples. We validate our ODD detection approach in two use cases: 1) identify samples collected from different protocols, and 2) detect samples from unknown disease classes. Additionally, we evaluate the performance of the proposed approach and compare it with other state-of-the-art methods. Furthermore, data-driven dermatology applications may deepen the disparity in clinical care across racial and ethnic groups since most datasets are reported to suffer from bias in skin tone distribution. Therefore, we also evaluate the fairness of these OOD detection methods across different skin tones. Our experiments resulted in competitive performance across multiple datasets in detecting OOD samples, which could be used (in the future) to design more effective transfer learning techniques prior to inferring on these samples.
Pattern Detection in the Activation Space for Identifying Synthesized Content
May 27, 2021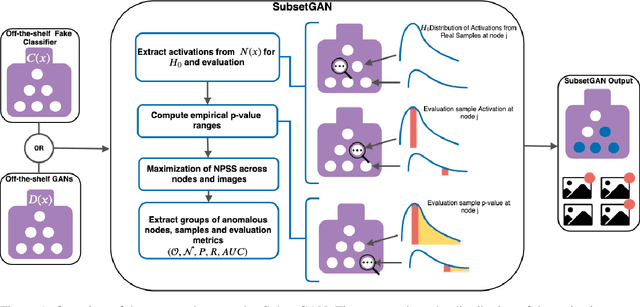
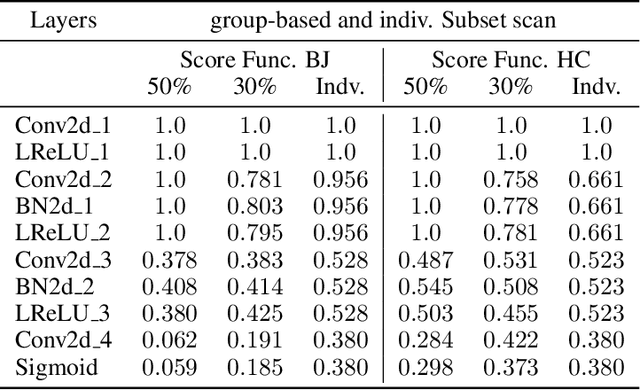

Generative Adversarial Networks (GANs) have recently achieved unprecedented success in photo-realistic image synthesis from low-dimensional random noise. The ability to synthesize high-quality content at a large scale brings potential risks as the generated samples may lead to misinformation that can create severe social, political, health, and business hazards. We propose SubsetGAN to identify generated content by detecting a subset of anomalous node-activations in the inner layers of pre-trained neural networks. These nodes, as a group, maximize a non-parametric measure of divergence away from the expected distribution of activations created from real data. This enable us to identify synthesised images without prior knowledge of their distribution. SubsetGAN efficiently scores subsets of nodes and returns the group of nodes within the pre-trained classifier that contributed to the maximum score. The classifier can be a general fake classifier trained over samples from multiple sources or the discriminator network from different GANs. Our approach shows consistently higher detection power than existing detection methods across several state-of-the-art GANs (PGGAN, StarGAN, and CycleGAN) and over different proportions of generated content.