 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWAXAL: A Large-Scale Multilingual African Language Speech Corpus
Feb 02, 2026The advancement of speech technology has predominantly favored high-resource languages, creating a significant digital divide for speakers of most Sub-Saharan African languages. To address this gap, we introduce WAXAL, a large-scale, openly accessible speech dataset for 21 languages representing over 100 million speakers. The collection consists of two main components: an Automated Speech Recognition (ASR) dataset containing approximately 1,250 hours of transcribed, natural speech from a diverse range of speakers, and a Text-to-Speech (TTS) dataset with over 180 hours of high-quality, single-speaker recordings reading phonetically balanced scripts. This paper details our methodology for data collection, annotation, and quality control, which involved partnerships with four African academic and community organizations. We provide a detailed statistical overview of the dataset and discuss its potential limitations and ethical considerations. The WAXAL datasets are released at https://huggingface.co/datasets/google/WaxalNLP under the permissive CC-BY-4.0 license to catalyze research, enable the development of inclusive technologies, and serve as a vital resource for the digital preservation of these languages.
A Collaborative Approach to the Analysis of the COVID-19 Response in Africa
Oct 04, 2022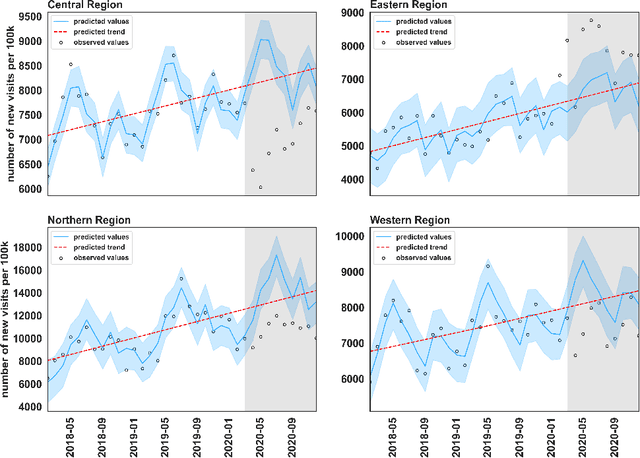

The COVID-19 crisis has emphasized the need for scientific methods such as machine learning to speed up the discovery of solutions to the pandemic. Harnessing machine learning techniques requires quality data, skilled personnel and advanced compute infrastructure. In Africa, however, machine learning competencies and compute infrastructures are limited. This paper demonstrates a cross-border collaborative capacity building approach to the application of machine learning techniques in discovering answers to COVID-19 questions.
Surrogate Ensemble Forecasting for Dynamic Climate Impact Models
Apr 12, 2022
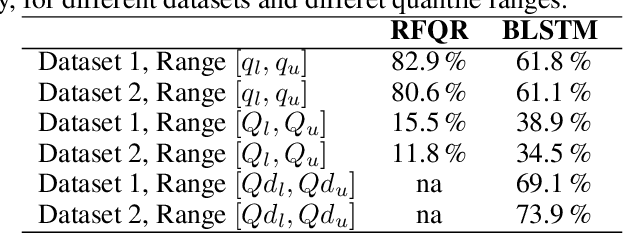


As acute climate change impacts weather and climate variability, there is increased demand for robust climate impact model predictions from which forecasts of the impacts can be derived. The quality of those predictions are limited by the climate drivers for the impact models which are nonlinear and highly variable in nature. One way to estimate the uncertainty of the model drivers is to assess the distribution of ensembles of climate forecasts. To capture the uncertainty in the impact model outputs associated with the distribution of the input climate forecasts, each individual forecast ensemble member has to be propagated through the physical model which can imply high computational costs. It is therefore desirable to train a surrogate model which allows predictions of the uncertainties of the output distribution in ensembles of climate drivers, thus reducing resource demands. This study considers a climate driven disease model, the Liverpool Malaria Model (LMM), which predicts the malaria transmission coefficient R0. Seasonal ensembles forecasts of temperature and precipitation with a 6-month horizon are propagated through the model, predicting the distribution of transmission time series. The input and output data is used to train surrogate models in the form of a Random Forest Quantile Regression (RFQR) model and a Bayesian Long Short-Term Memory (BLSTM) neural network. Comparing the predictive performance, the RFQR better predicts the time series of the individual ensemble member, while the BLSTM offers a direct way to construct a combined distribution for all ensemble members. An important element of the proposed methodology is that accounting for non-normal distributions of climate forecast ensembles can be captured naturally by a Bayesian formulation.
Sparsity-based Feature Selection for Anomalous Subgroup Discovery
Jan 06, 2022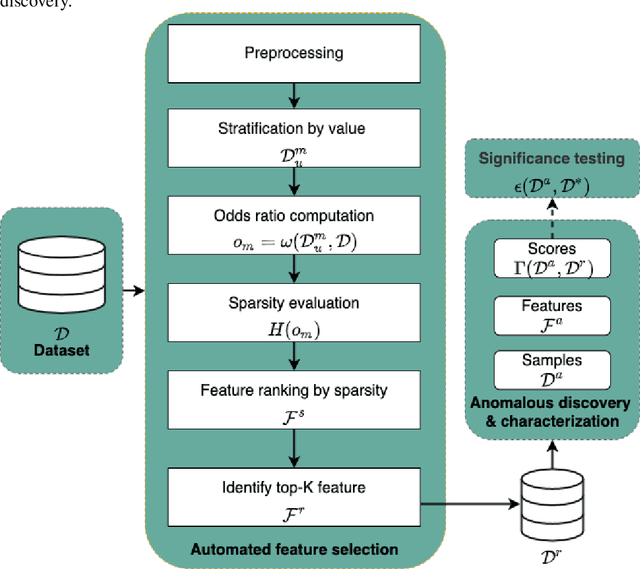
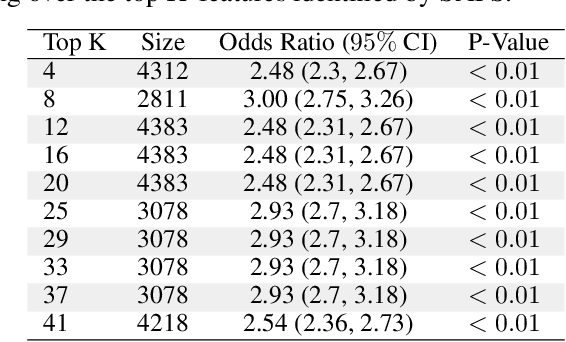
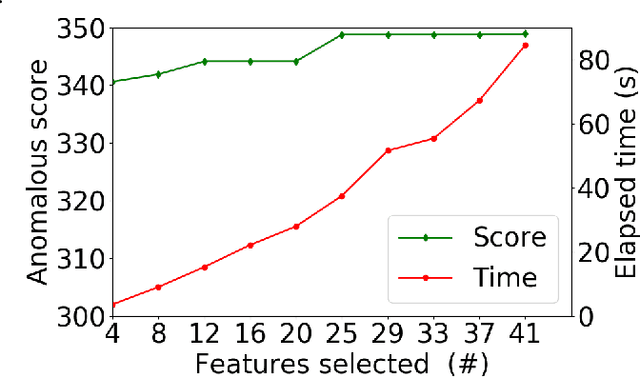
Anomalous pattern detection aims to identify instances where deviation from normalcy is evident, and is widely applicable across domains. Multiple anomalous detection techniques have been proposed in the state of the art. However, there is a common lack of a principled and scalable feature selection method for efficient discovery. Existing feature selection techniques are often conducted by optimizing the performance of prediction outcomes rather than its systemic deviations from the expected. In this paper, we proposed a sparsity-based automated feature selection (SAFS) framework, which encodes systemic outcome deviations via the sparsity of feature-driven odds ratios. SAFS is a model-agnostic approach with usability across different discovery techniques. SAFS achieves more than $3\times$ reduction in computation time while maintaining detection performance when validated on publicly available critical care dataset. SAFS also results in a superior performance when compared against multiple baselines for feature selection.
Post-discovery Analysis of Anomalous Subsets
Nov 23, 2021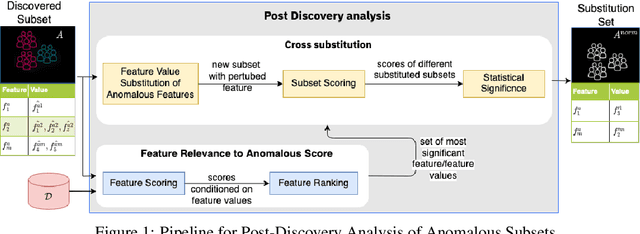


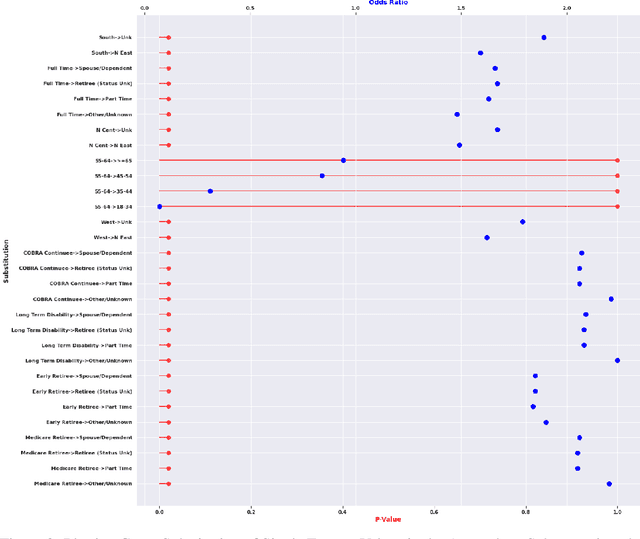
Analyzing the behaviour of a population in response to disease and interventions is critical to unearth variability in healthcare as well as understand sub-populations that require specialized attention, but also to assist in designing future interventions. Two aspects become very essential in such analysis namely: i) Discovery of differentiating patterns exhibited by sub-populations, and ii) Characterization of the identified subpopulations. For the discovery phase, an array of approaches in the anomalous pattern detection literature have been employed to reveal differentiating patterns, especially to identify anomalous subgroups. However, these techniques are limited to describing the anomalous subgroups and offer little in form of insightful characterization, thereby limiting interpretability and understanding of these data-driven techniques in clinical practices. In this work, we propose an analysis of differentiated output (rather than discovery) and quantify anomalousness similarly to the counter-factual setting. To this end we design an approach to perform post-discovery analysis of anomalous subsets, in which we initially identify the most important features on the anomalousness of the subsets, then by perturbation, the approach seeks to identify the least number of changes necessary to lose anomalousness. Our approach is presented and the evaluation results on the 2019 MarketScan Commercial Claims and Medicare data, show that extra insights can be obtained by extrapolated examination of the identified subgroups.
Automated Supervised Feature Selection for Differentiated Patterns of Care
Nov 05, 2021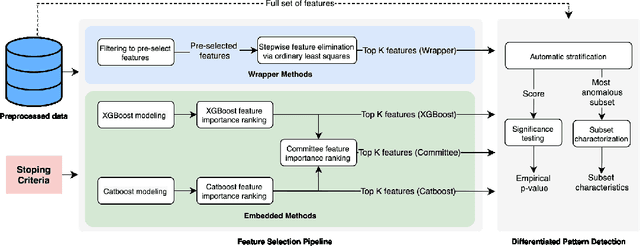

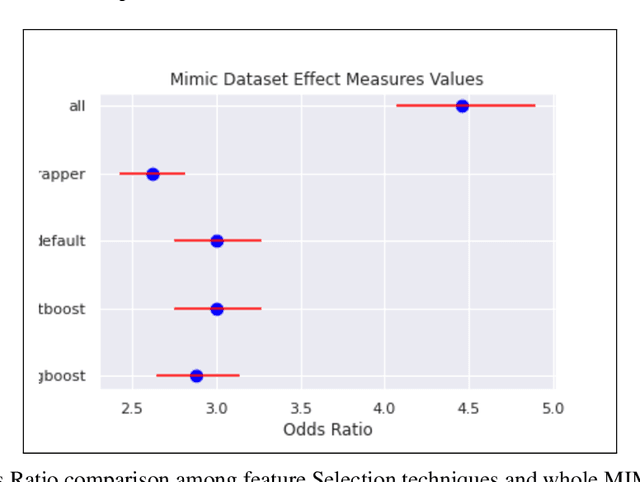
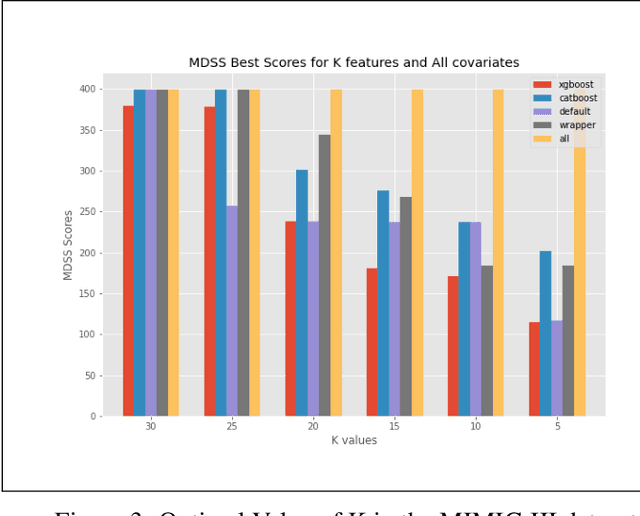
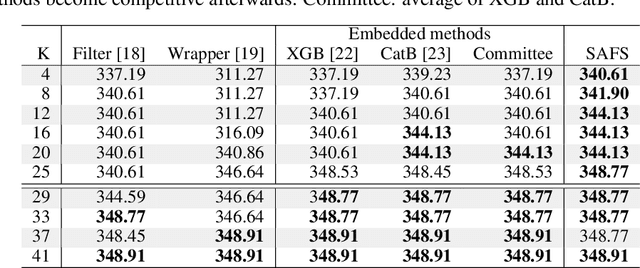
An automated feature selection pipeline was developed using several state-of-the-art feature selection techniques to select optimal features for Differentiating Patterns of Care (DPOC). The pipeline included three types of feature selection techniques; Filters, Wrappers and Embedded methods to select the top K features. Five different datasets with binary dependent variables were used and their different top K optimal features selected. The selected features were tested in the existing multi-dimensional subset scanning (MDSS) where the most anomalous subpopulations, most anomalous subsets, propensity scores, and effect of measures were recorded to test their performance. This performance was compared with four similar metrics gained after using all covariates in the dataset in the MDSS pipeline. We found out that despite the different feature selection techniques used, the data distribution is key to note when determining the technique to use.
Overcoming Digital Gravity when using AI in Public Health Decisions
Nov 05, 2021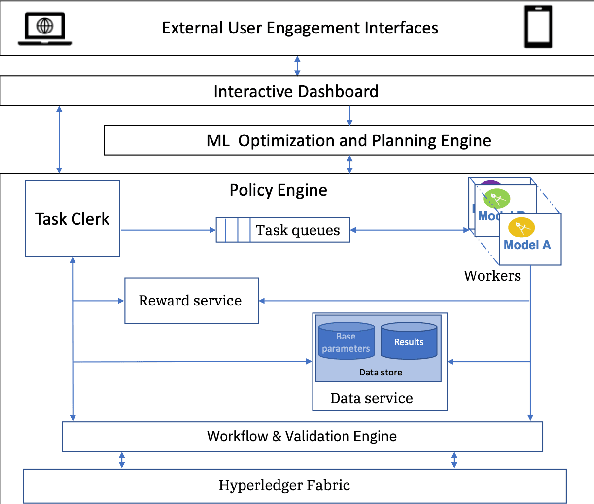
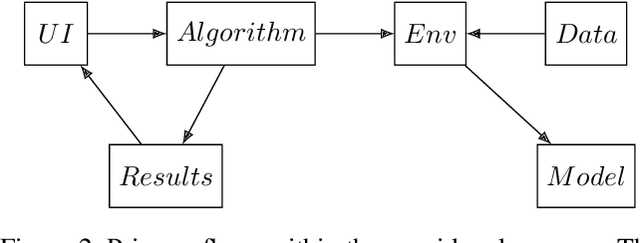
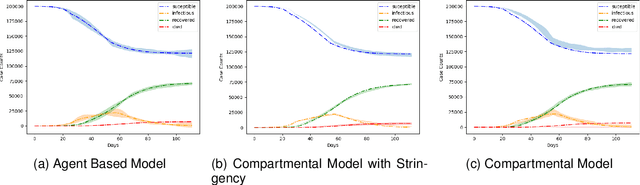
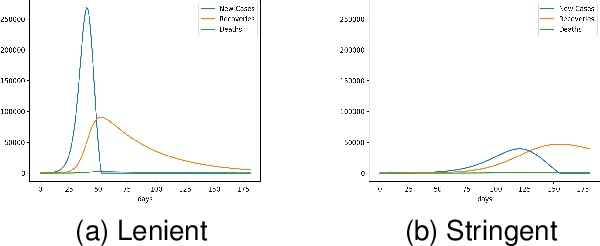
In popular usage, Data Gravity refers to the ability of a body of data to attract applications, services and other data. In this work we introduce a broader concept, "Digital Gravity" which includes not just data, but other elements of the AI/ML workflow. This concept is born out of our recent experiences in developing and deploying an AI-based decision support platform intended for use in a public health context. In addition to data, examples of additional considerations are compute (infrastructure and software), DevSecOps (personnel and practices), algorithms/programs, control planes, middleware (considered separately from programs), and even companies/service providers. We discuss the impact of Digital Gravity on the pathway to adoption and suggest preliminary approaches to conceptualize and mitigate the friction caused by it.
WNTRAC: Artificial Intelligence Assisted Tracking of Non-pharmaceutical Interventions Implemented Worldwide for COVID-19
Sep 16, 2020



The Coronavirus disease 2019 (COVID-19) global pandemic has transformed almost every facet of human society throughout the world. Against an emerging, highly transmissible disease with no definitive treatment or vaccine, governments worldwide have implemented non-pharmaceutical intervention (NPI) to slow the spread of the virus. Examples of such interventions include community actions (e.g. school closures, restrictions on mass gatherings), individual actions (e.g. mask wearing, self-quarantine), and environmental actions (e.g. public facility cleaning). We present the Worldwide Non-pharmaceutical Interventions Tracker for COVID-19 (WNTRAC), a comprehensive dataset consisting of over 6,000 NPIs implemented worldwide since the start of the pandemic. WNTRAC covers NPIs implemented across 261 countries and territories, and classifies NPI measures into a taxonomy of sixteen NPI types. NPI measures are automatically extracted daily from Wikipedia articles using natural language processing techniques and manually validated to ensure accuracy and veracity. We hope that the dataset is valuable for policymakers, public health leaders, and researchers in modeling and analysis efforts for controlling the spread of COVID-19.
Novel Exploration Techniques (NETs) for Malaria Policy Interventions
Dec 01, 2017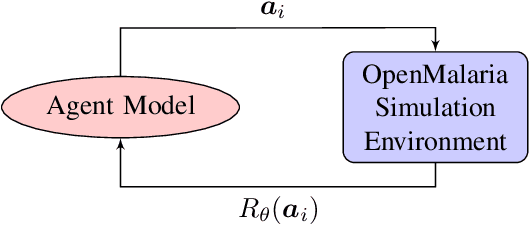
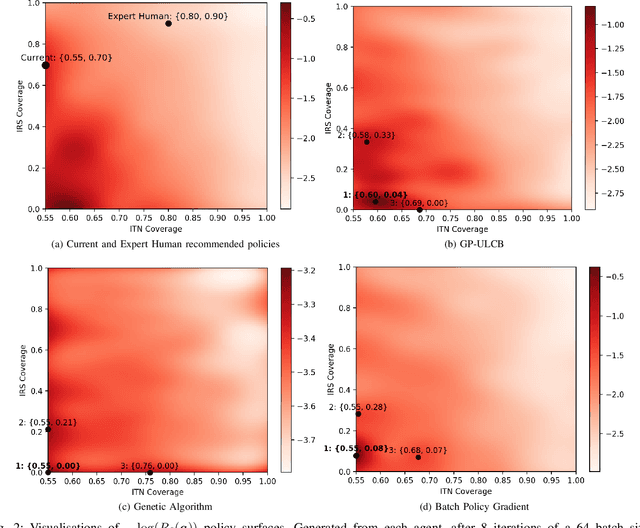

The task of decision-making under uncertainty is daunting, especially for problems which have significant complexity. Healthcare policy makers across the globe are facing problems under challenging constraints, with limited tools to help them make data driven decisions. In this work we frame the process of finding an optimal malaria policy as a stochastic multi-armed bandit problem, and implement three agent based strategies to explore the policy space. We apply a Gaussian Process regression to the findings of each agent, both for comparison and to account for stochastic results from simulating the spread of malaria in a fixed population. The generated policy spaces are compared with published results to give a direct reference with human expert decisions for the same simulated population. Our novel approach provides a powerful resource for policy makers, and a platform which can be readily extended to capture future more nuanced policy spaces.