 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioVERSE: Representation Alignment of Biomedical Modalities to LLMs for Multi-Modal Reasoning
Oct 01, 2025



Recent advances in large language models (LLMs) and biomedical foundation models (BioFMs) have achieved strong results in biological text reasoning, molecular modeling, and single-cell analysis, yet they remain siloed in disjoint embedding spaces, limiting cross-modal reasoning. We present BIOVERSE (Biomedical Vector Embedding Realignment for Semantic Engagement), a two-stage approach that adapts pretrained BioFMs as modality encoders and aligns them with LLMs through lightweight, modality-specific projection layers. The approach first aligns each modality to a shared LLM space through independently trained projections, allowing them to interoperate naturally, and then applies standard instruction tuning with multi-modal data to bring them together for downstream reasoning. By unifying raw biomedical data with knowledge embedded in LLMs, the approach enables zero-shot annotation, cross-modal question answering, and interactive, explainable dialogue. Across tasks spanning cell-type annotation, molecular description, and protein function reasoning, compact BIOVERSE configurations surpass larger LLM baselines while enabling richer, generative outputs than existing BioFMs, establishing a foundation for principled multi-modal biomedical reasoning.
BMFM-RNA: An Open Framework for Building and Evaluating Transcriptomic Foundation Models
Jun 17, 2025



Transcriptomic foundation models (TFMs) have recently emerged as powerful tools for analyzing gene expression in cells and tissues, supporting key tasks such as cell-type annotation, batch correction, and perturbation prediction. However, the diversity of model implementations and training strategies across recent TFMs, though promising, makes it challenging to isolate the contribution of individual design choices or evaluate their potential synergies. This hinders the field's ability to converge on best practices and limits the reproducibility of insights across studies. We present BMFM-RNA, an open-source, modular software package that unifies diverse TFM pretraining and fine-tuning objectives within a single framework. Leveraging this capability, we introduce a novel training objective, whole cell expression decoder (WCED), which captures global expression patterns using an autoencoder-like CLS bottleneck representation. In this paper, we describe the framework, supported input representations, and training objectives. We evaluated four model checkpoints pretrained on CELLxGENE using combinations of masked language modeling (MLM), WCED and multitask learning. Using the benchmarking capabilities of BMFM-RNA, we show that WCED-based models achieve performance that matches or exceeds state-of-the-art approaches like scGPT across more than a dozen datasets in both zero-shot and fine-tuning tasks. BMFM-RNA, available as part of the biomed-multi-omics project ( https://github.com/BiomedSciAI/biomed-multi-omic ), offers a reproducible foundation for systematic benchmarking and community-driven exploration of optimal TFM training strategies, enabling the development of more effective tools to leverage the latest advances in AI for understanding cell biology.
Extracting Medication Changes in Clinical Narratives using Pre-trained Language Models
Aug 17, 2022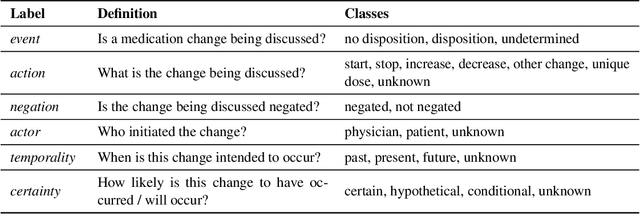
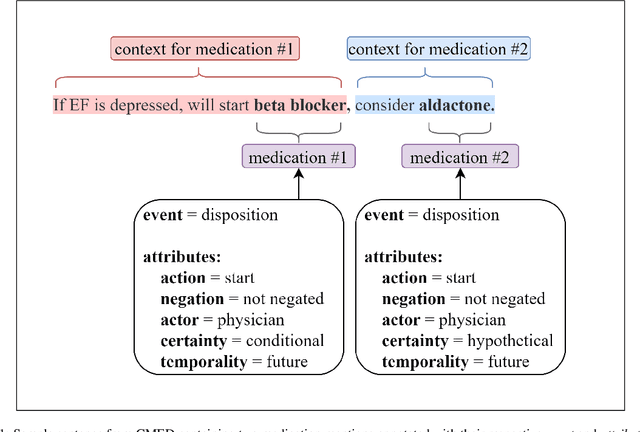
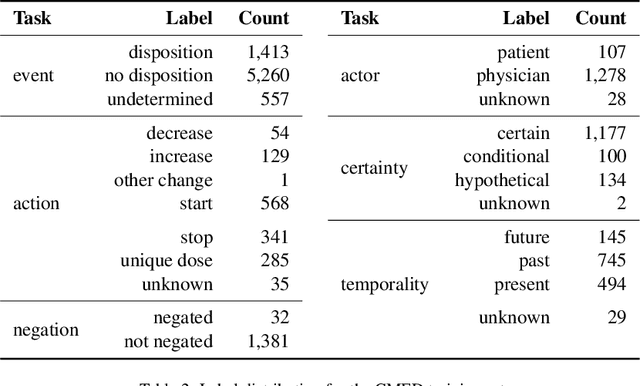
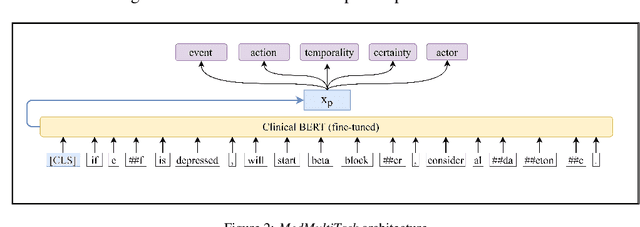
An accurate and detailed account of patient medications, including medication changes within the patient timeline, is essential for healthcare providers to provide appropriate patient care. Healthcare providers or the patients themselves may initiate changes to patient medication. Medication changes take many forms, including prescribed medication and associated dosage modification. These changes provide information about the overall health of the patient and the rationale that led to the current care. Future care can then build on the resulting state of the patient. This work explores the automatic extraction of medication change information from free-text clinical notes. The Contextual Medication Event Dataset (CMED) is a corpus of clinical notes with annotations that characterize medication changes through multiple change-related attributes, including the type of change (start, stop, increase, etc.), initiator of the change, temporality, change likelihood, and negation. Using CMED, we identify medication mentions in clinical text and propose three novel high-performing BERT-based systems that resolve the annotated medication change characteristics. We demonstrate that our proposed architectures improve medication change classification performance over the initial work exploring CMED. We identify medication mentions with high performance at 0.959 F1, and our proposed systems classify medication changes and their attributes at an overall average of 0.827 F1.
Toward Understanding Clinical Context of Medication Change Events in Clinical Narratives
Nov 17, 2020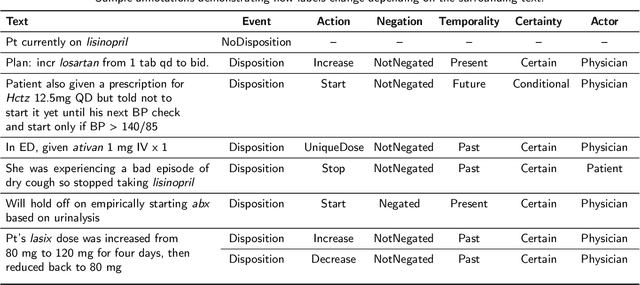
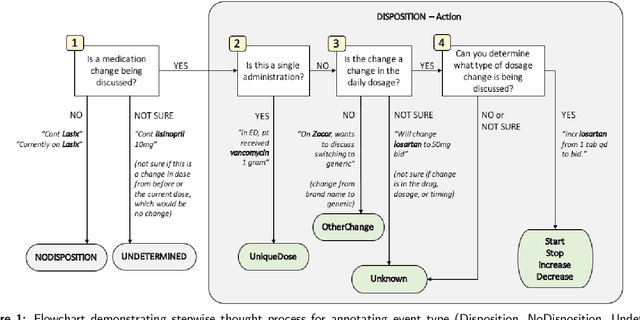
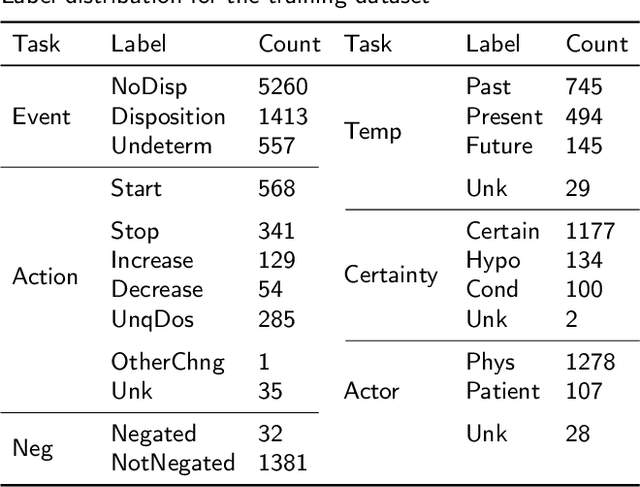
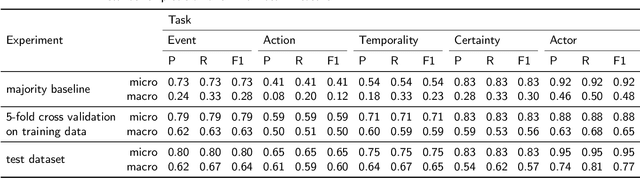
Understanding medication events in clinical narratives is essential to achieving a complete picture of a patient's medication history. While prior research has explored identification of medication changes in clinical notes, due to the longitudinal and narrative nature of clinical documentation, extraction of medication change alone without the necessary clinical context is insufficient for use in real-world applications, such as medication timeline generation and medication reconciliation. In this paper, we present the Contextualized Medication Event Dataset (CMED), a dataset for capturing relevant context of medication changes documented in clinical notes, which was developed using a novel conceptual framework that organizes context for clinical events into various orthogonal dimensions. In this process, we define specific contextual aspects pertinent to medication change events (i.e. Action, Negation, Temporality, Certainty, and Actor), describe the annotation process and challenges encountered, and report the results of preliminary experiments. The resulting dataset, CMED, consists of 9,013 medication mentions annotated over 500 clinical notes. To encourage development of methods for improved understanding of medications in clinical narratives, CMED will be released to the community as a shared task in 2021.
WNTRAC: Artificial Intelligence Assisted Tracking of Non-pharmaceutical Interventions Implemented Worldwide for COVID-19
Sep 16, 2020



The Coronavirus disease 2019 (COVID-19) global pandemic has transformed almost every facet of human society throughout the world. Against an emerging, highly transmissible disease with no definitive treatment or vaccine, governments worldwide have implemented non-pharmaceutical intervention (NPI) to slow the spread of the virus. Examples of such interventions include community actions (e.g. school closures, restrictions on mass gatherings), individual actions (e.g. mask wearing, self-quarantine), and environmental actions (e.g. public facility cleaning). We present the Worldwide Non-pharmaceutical Interventions Tracker for COVID-19 (WNTRAC), a comprehensive dataset consisting of over 6,000 NPIs implemented worldwide since the start of the pandemic. WNTRAC covers NPIs implemented across 261 countries and territories, and classifies NPI measures into a taxonomy of sixteen NPI types. NPI measures are automatically extracted daily from Wikipedia articles using natural language processing techniques and manually validated to ensure accuracy and veracity. We hope that the dataset is valuable for policymakers, public health leaders, and researchers in modeling and analysis efforts for controlling the spread of COVID-19.
Extracting Daily Dosage from Medication Instructions in EHRs: An Automated Approach and Lessons Learned
May 21, 2020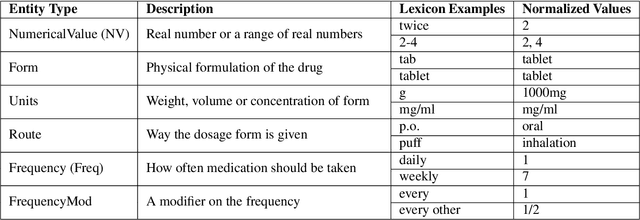
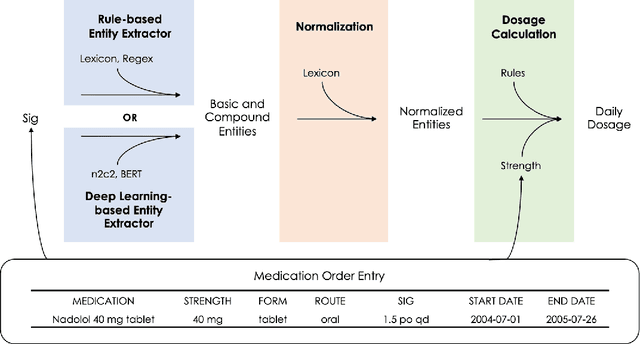

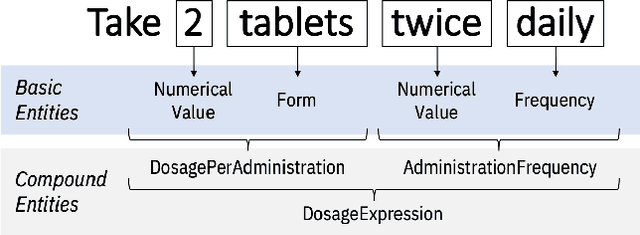
Understanding a patient's medication history is essential for physicians to provide appropriate treatment recommendations. A medication's prescribed daily dosage is a key element of the medication history; however, it is generally not provided as a discrete quantity and needs to be derived from free text medication instructions (Sigs) in the structured electronic health record (EHR). Existing works in daily dosage extraction are narrow in scope, dealing with dosage extraction for a single drug from clinical notes. Here, we present an automated approach to calculate daily dosage for all medications in EHR structured data. We describe and characterize the variable language used in Sigs, and present our hybrid system for calculating daily dosage combining deep learning-based named entity extractor with lexicon dictionaries and regular expressions. Our system achieves 0.98 precision and 0.95 recall on an expert-generated dataset of 1000 Sigs, demonstrating its effectiveness on the general purpose daily dosage calculation task.