 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Medication Changes in Clinical Narratives using Pre-trained Language Models
Aug 17, 2022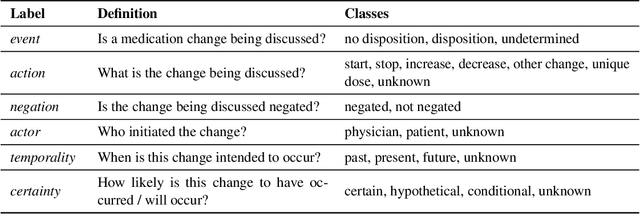
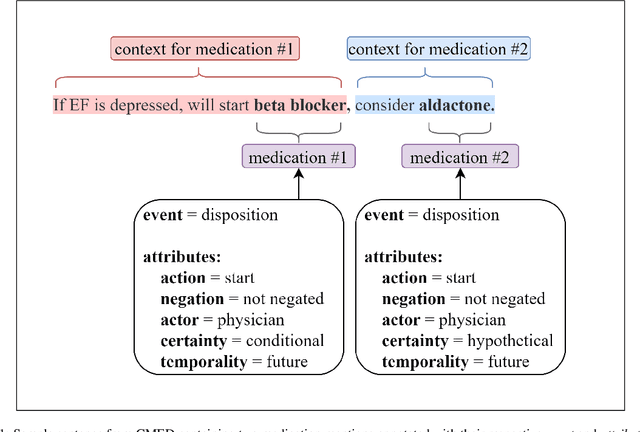
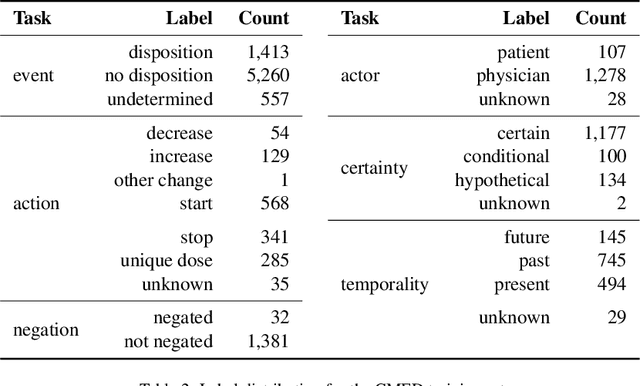
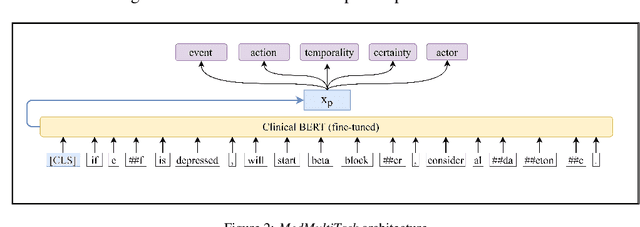
An accurate and detailed account of patient medications, including medication changes within the patient timeline, is essential for healthcare providers to provide appropriate patient care. Healthcare providers or the patients themselves may initiate changes to patient medication. Medication changes take many forms, including prescribed medication and associated dosage modification. These changes provide information about the overall health of the patient and the rationale that led to the current care. Future care can then build on the resulting state of the patient. This work explores the automatic extraction of medication change information from free-text clinical notes. The Contextual Medication Event Dataset (CMED) is a corpus of clinical notes with annotations that characterize medication changes through multiple change-related attributes, including the type of change (start, stop, increase, etc.), initiator of the change, temporality, change likelihood, and negation. Using CMED, we identify medication mentions in clinical text and propose three novel high-performing BERT-based systems that resolve the annotated medication change characteristics. We demonstrate that our proposed architectures improve medication change classification performance over the initial work exploring CMED. We identify medication mentions with high performance at 0.959 F1, and our proposed systems classify medication changes and their attributes at an overall average of 0.827 F1.
Extracting Daily Dosage from Medication Instructions in EHRs: An Automated Approach and Lessons Learned
May 21, 2020
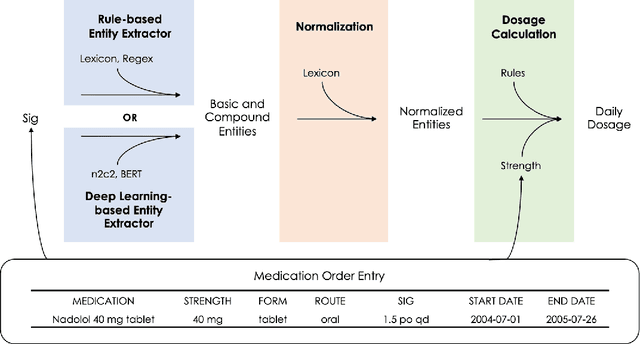

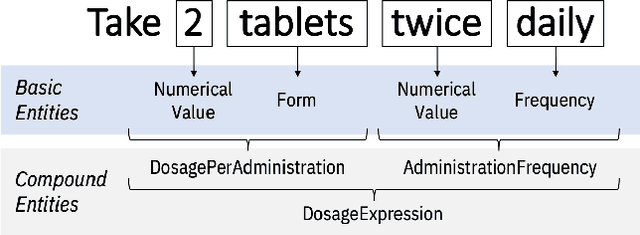
Understanding a patient's medication history is essential for physicians to provide appropriate treatment recommendations. A medication's prescribed daily dosage is a key element of the medication history; however, it is generally not provided as a discrete quantity and needs to be derived from free text medication instructions (Sigs) in the structured electronic health record (EHR). Existing works in daily dosage extraction are narrow in scope, dealing with dosage extraction for a single drug from clinical notes. Here, we present an automated approach to calculate daily dosage for all medications in EHR structured data. We describe and characterize the variable language used in Sigs, and present our hybrid system for calculating daily dosage combining deep learning-based named entity extractor with lexicon dictionaries and regular expressions. Our system achieves 0.98 precision and 0.95 recall on an expert-generated dataset of 1000 Sigs, demonstrating its effectiveness on the general purpose daily dosage calculation task.
Annotating Electronic Medical Records for Question Answering
May 17, 2018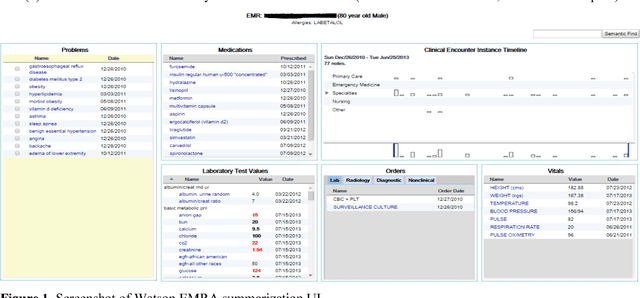
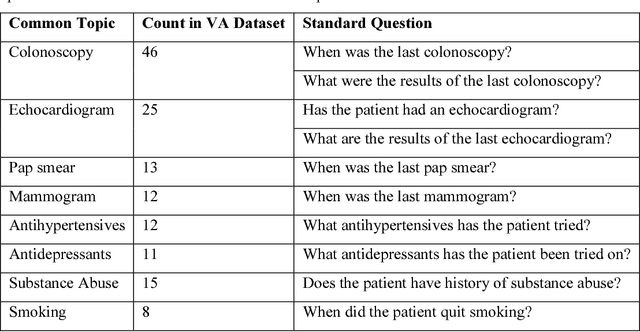
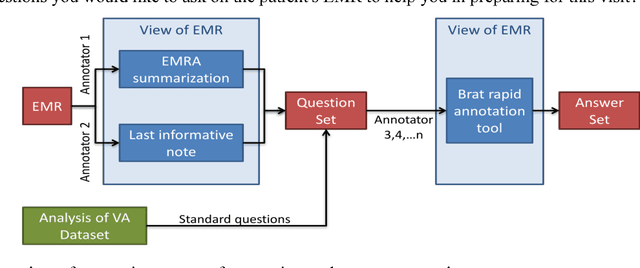
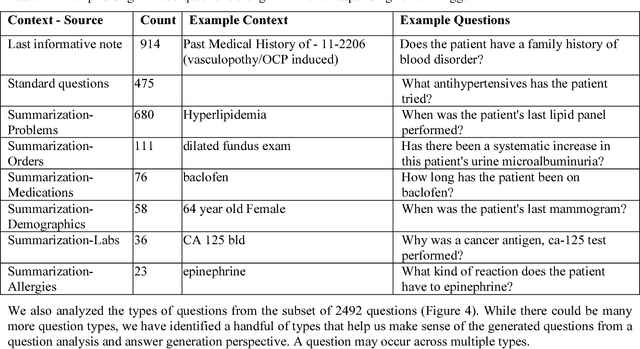
Our research is in the relatively unexplored area of question answering technologies for patient-specific questions over their electronic health records. A large dataset of human expert curated question and answer pairs is an important pre-requisite for developing, training and evaluating any question answering system that is powered by machine learning. In this paper, we describe a process for creating such a dataset of questions and answers. Our methodology is replicable, can be conducted by medical students as annotators, and results in high inter-annotator agreement (0.71 Cohen's kappa). Over the course of 11 months, 11 medical students followed our annotation methodology, resulting in a question answering dataset of 5696 questions over 71 patient records, of which 1747 questions have corresponding answers generated by the medical students.