 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWNTRAC: Artificial Intelligence Assisted Tracking of Non-pharmaceutical Interventions Implemented Worldwide for COVID-19
Sep 16, 2020



The Coronavirus disease 2019 (COVID-19) global pandemic has transformed almost every facet of human society throughout the world. Against an emerging, highly transmissible disease with no definitive treatment or vaccine, governments worldwide have implemented non-pharmaceutical intervention (NPI) to slow the spread of the virus. Examples of such interventions include community actions (e.g. school closures, restrictions on mass gatherings), individual actions (e.g. mask wearing, self-quarantine), and environmental actions (e.g. public facility cleaning). We present the Worldwide Non-pharmaceutical Interventions Tracker for COVID-19 (WNTRAC), a comprehensive dataset consisting of over 6,000 NPIs implemented worldwide since the start of the pandemic. WNTRAC covers NPIs implemented across 261 countries and territories, and classifies NPI measures into a taxonomy of sixteen NPI types. NPI measures are automatically extracted daily from Wikipedia articles using natural language processing techniques and manually validated to ensure accuracy and veracity. We hope that the dataset is valuable for policymakers, public health leaders, and researchers in modeling and analysis efforts for controlling the spread of COVID-19.
Training Models to Extract Treatment Plans from Clinical Notes Using Contents of Sections with Headings
Jun 27, 2019
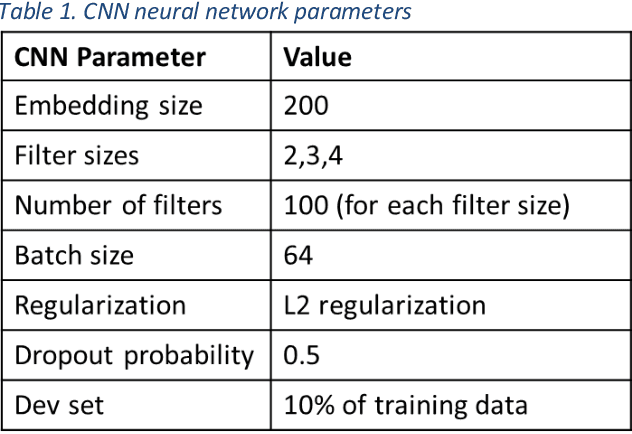
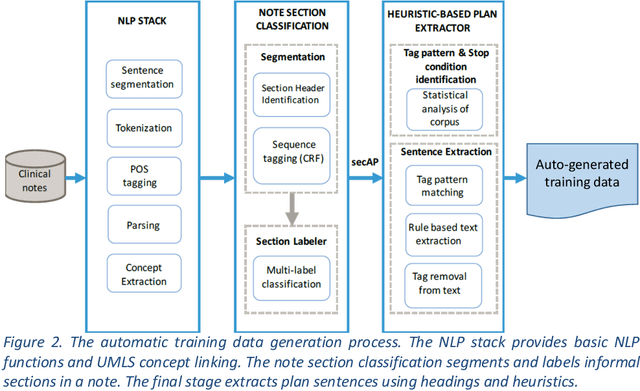
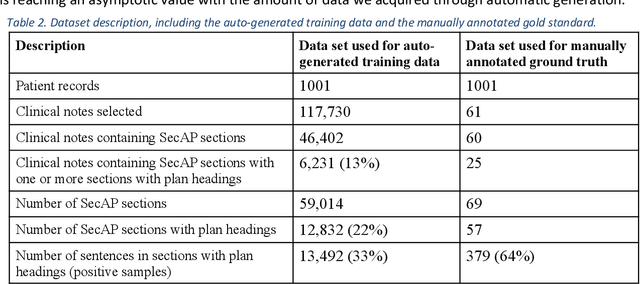
Objective: Using natural language processing (NLP) to find sentences that state treatment plans in a clinical note, would automate plan extraction and would further enable their use in tools that help providers and care managers. However, as in the most NLP tasks on clinical text, creating gold standard to train and test NLP models is tedious and expensive. Fortuitously, sometimes but not always clinical notes contain sections with a heading that identifies the section as a plan. Leveraging contents of such labeled sections as a noisy training data, we assessed accuracy of NLP models trained with the data. Methods: We used common variations of plan headings and rule-based heuristics to find plan sections with headings in clinical notes, and we extracted sentences from them and formed a noisy training data of plan sentences. We trained Support Vector Machine (SVM) and Convolutional Neural Network (CNN) models with the data. We measured accuracy of the trained models on the noisy dataset using ten-fold cross validation and separately on a set-aside manually annotated dataset. Results: About 13% of 117,730 clinical notes contained treatment plans sections with recognizable headings in the 1001 longitudinal patient records that were obtained from Cleveland Clinic under an IRB approval. We were able to extract and create a noisy training data of 13,492 plan sentences from the clinical notes. CNN achieved best F measures, 0.91 and 0.97 in the cross-validation and set-aside evaluation experiments respectively. SVM slightly underperformed with F measures of 0.89 and 0.96 in the same experiments. Conclusion: Our study showed that the training supervised learning models using noisy plan sentences was effective in identifying them in all clinical notes. More broadly, sections with informal headings in clinical notes can be a good source for generating effective training data.