 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Exploration Module VEM: A Cloud-Native Optimization and Validation Tool for Geospatial Modeling and AI Workflows
Nov 26, 2023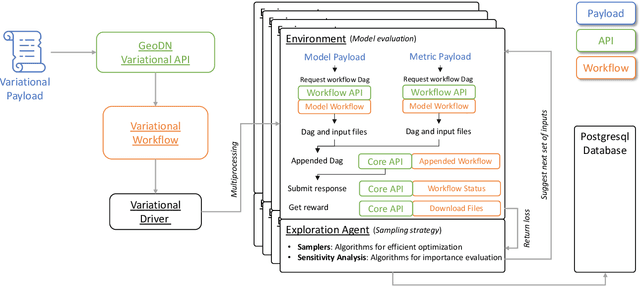
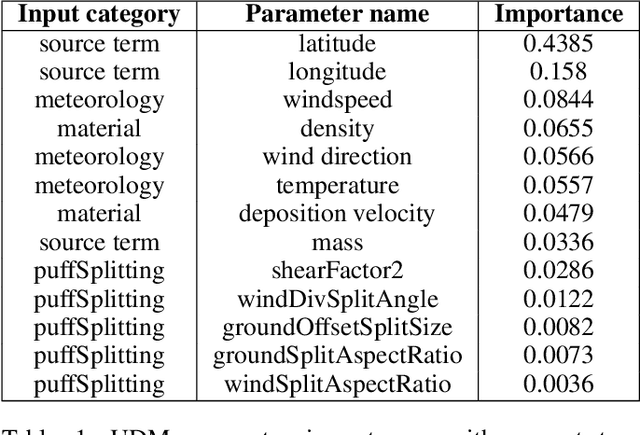

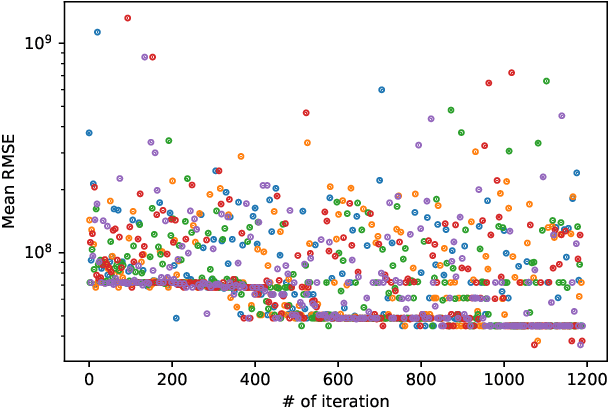
Geospatial observations combined with computational models have become key to understanding the physical systems of our environment and enable the design of best practices to reduce societal harm. Cloud-based deployments help to scale up these modeling and AI workflows. Yet, for practitioners to make robust conclusions, model tuning and testing is crucial, a resource intensive process which involves the variation of model input variables. We have developed the Variational Exploration Module which facilitates the optimization and validation of modeling workflows deployed in the cloud by orchestrating workflow executions and using Bayesian and machine learning-based methods to analyze model behavior. User configurations allow the combination of diverse sampling strategies in multi-agent environments. The flexibility and robustness of the model-agnostic module is demonstrated using real-world applications.
Learning to Act: Novel Integration of Algorithms and Models for Epidemic Preparedness
Oct 05, 2022


In this work we present a framework which may transform research and praxis in epidemic planning. Introduced in the context of the ongoing COVID-19 pandemic, we provide a concrete demonstration of the way algorithms may learn from epidemiological models to scale their value for epidemic preparedness. Our contributions in this work are two fold: 1) a novel platform which makes it easy for decision making stakeholders to interact with epidemiological models and algorithms developed within the Machine learning community, and 2) the release of this work under the Apache-2.0 License. The objective of this paper is not to look closely at any particular models or algorithms, but instead to highlight how they can be coupled and shared to empower evidence-based decision making.
A Collaborative Approach to the Analysis of the COVID-19 Response in Africa
Oct 04, 2022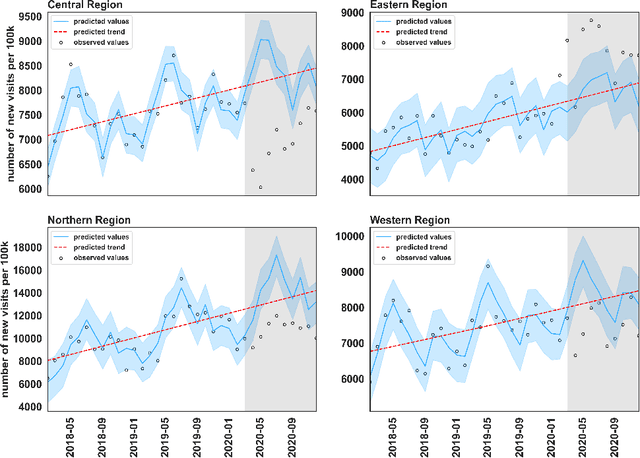

The COVID-19 crisis has emphasized the need for scientific methods such as machine learning to speed up the discovery of solutions to the pandemic. Harnessing machine learning techniques requires quality data, skilled personnel and advanced compute infrastructure. In Africa, however, machine learning competencies and compute infrastructures are limited. This paper demonstrates a cross-border collaborative capacity building approach to the application of machine learning techniques in discovering answers to COVID-19 questions.
Surrogate Ensemble Forecasting for Dynamic Climate Impact Models
Apr 12, 2022
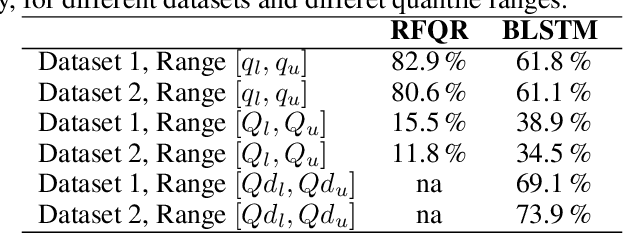


As acute climate change impacts weather and climate variability, there is increased demand for robust climate impact model predictions from which forecasts of the impacts can be derived. The quality of those predictions are limited by the climate drivers for the impact models which are nonlinear and highly variable in nature. One way to estimate the uncertainty of the model drivers is to assess the distribution of ensembles of climate forecasts. To capture the uncertainty in the impact model outputs associated with the distribution of the input climate forecasts, each individual forecast ensemble member has to be propagated through the physical model which can imply high computational costs. It is therefore desirable to train a surrogate model which allows predictions of the uncertainties of the output distribution in ensembles of climate drivers, thus reducing resource demands. This study considers a climate driven disease model, the Liverpool Malaria Model (LMM), which predicts the malaria transmission coefficient R0. Seasonal ensembles forecasts of temperature and precipitation with a 6-month horizon are propagated through the model, predicting the distribution of transmission time series. The input and output data is used to train surrogate models in the form of a Random Forest Quantile Regression (RFQR) model and a Bayesian Long Short-Term Memory (BLSTM) neural network. Comparing the predictive performance, the RFQR better predicts the time series of the individual ensemble member, while the BLSTM offers a direct way to construct a combined distribution for all ensemble members. An important element of the proposed methodology is that accounting for non-normal distributions of climate forecast ensembles can be captured naturally by a Bayesian formulation.
Deep Temporal Interpolation of Radar-based Precipitation
Mar 01, 2022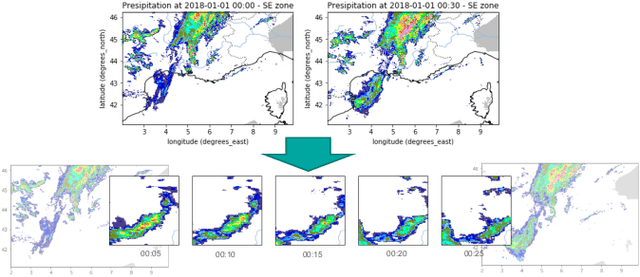
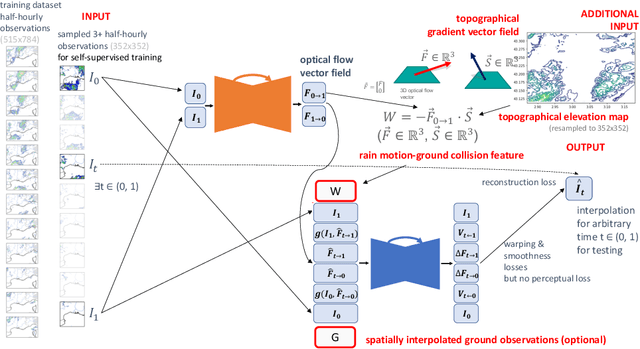
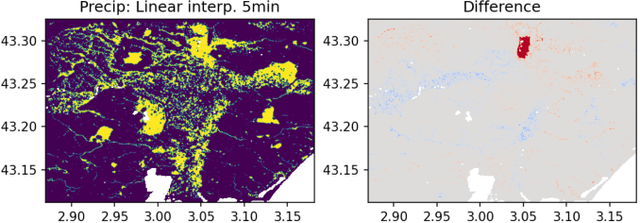
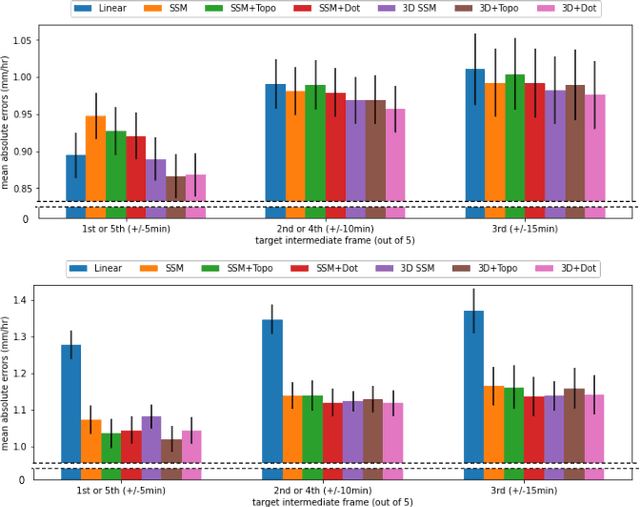
When providing the boundary conditions for hydrological flood models and estimating the associated risk, interpolating precipitation at very high temporal resolutions (e.g. 5 minutes) is essential not to miss the cause of flooding in local regions. In this paper, we study optical flow-based interpolation of globally available weather radar images from satellites. The proposed approach uses deep neural networks for the interpolation of multiple video frames, while terrain information is combined with temporarily coarse-grained precipitation radar observation as inputs for self-supervised training. An experiment with the Meteonet radar precipitation dataset for the flood risk simulation in Aude, a department in Southern France (2018), demonstrated the advantage of the proposed method over a linear interpolation baseline, with up to 20% error reduction.
Trusted Multi-Party Computation and Verifiable Simulations: A Scalable Blockchain Approach
Sep 22, 2018



Large-scale computational experiments, often running over weeks and over large datasets, are used extensively in fields such as epidemiology, meteorology, computational biology, and healthcare to understand phenomena, and design high-stakes policies affecting everyday health and economy. For instance, the OpenMalaria framework is a computationally-intensive simulation used by various non-governmental and governmental agencies to understand malarial disease spread and effectiveness of intervention strategies, and subsequently design healthcare policies. Given that such shared results form the basis of inferences drawn, technological solutions designed, and day-to-day policies drafted, it is essential that the computations are validated and trusted. In particular, in a multi-agent environment involving several independent computing agents, a notion of trust in results generated by peers is critical in facilitating transparency, accountability, and collaboration. Using a novel combination of distributed validation of atomic computation blocks and a blockchain-based immutable audits mechanism, this work proposes a universal framework for distributed trust in computations. In particular we address the scalaibility problem by reducing the storage and communication costs using a lossy compression scheme. This framework guarantees not only verifiability of final results, but also the validity of local computations, and its cost-benefit tradeoffs are studied using a synthetic example of training a neural network.
Assessing virtualization effects in simulations of distributed robotics
Dec 16, 2017
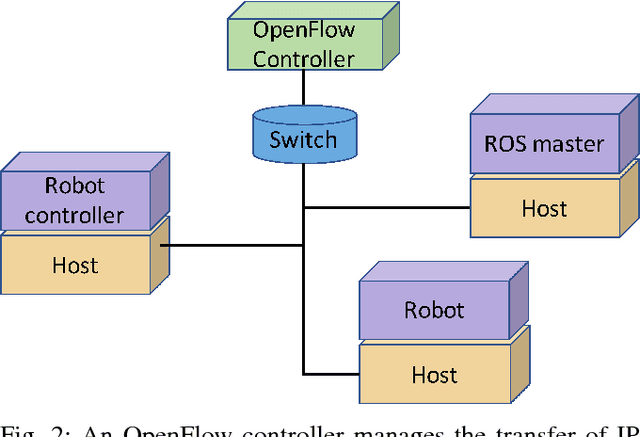


In this work, our aim is to identify whether the choice of virtualization strategy influences the performance of simulations in robotics. Performance is quantified in the error between a reference trajectory and the actual trajectory for the ball moving along the surface of a smooth plate. The two-sample Kolmogorov-Smirnov test is used to assess significance of variations in performance under the different experimental settings. Our results show that the selection of virtualization technology does have a significant effect on simulation, and moreover this effect can be amplified by the use of some operating systems. While these results are a strong cause for caution, they also provide reason for optimism for those considering 'repeatable robotics research' using virtualization.
Characterizing the hyper-parameter space of LSTM language models for mixed context applications
Dec 08, 2017



Applying state of the art deep learning models to novel real world datasets gives a practical evaluation of the generalizability of these models. Of importance in this process is how sensitive the hyper parameters of such models are to novel datasets as this would affect the reproducibility of a model. We present work to characterize the hyper parameter space of an LSTM for language modeling on a code-mixed corpus. We observe that the evaluated model shows minimal sensitivity to our novel dataset bar a few hyper parameters.
Novel Exploration Techniques (NETs) for Malaria Policy Interventions
Dec 01, 2017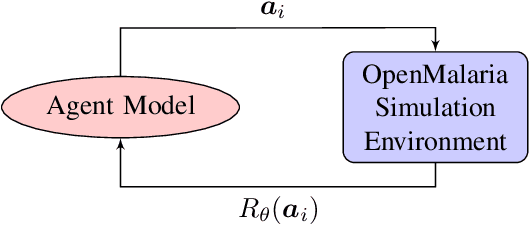
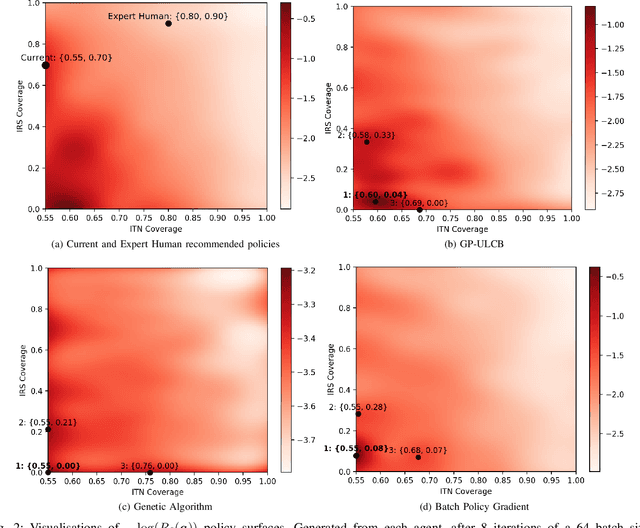

The task of decision-making under uncertainty is daunting, especially for problems which have significant complexity. Healthcare policy makers across the globe are facing problems under challenging constraints, with limited tools to help them make data driven decisions. In this work we frame the process of finding an optimal malaria policy as a stochastic multi-armed bandit problem, and implement three agent based strategies to explore the policy space. We apply a Gaussian Process regression to the findings of each agent, both for comparison and to account for stochastic results from simulating the spread of malaria in a fixed population. The generated policy spaces are compared with published results to give a direct reference with human expert decisions for the same simulated population. Our novel approach provides a powerful resource for policy makers, and a platform which can be readily extended to capture future more nuanced policy spaces.
Using Genetic Algorithms to Benchmark the Cloud
Aug 27, 2015


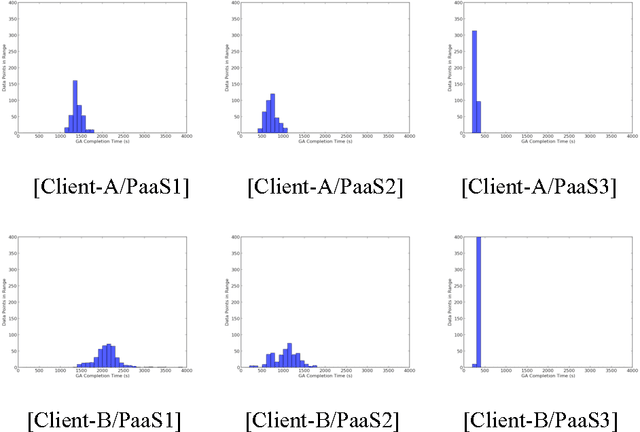
This paper presents a novel application of Genetic Algorithms(GAs) to quantify the performance of Platform as a Service (PaaS), a cloud service model that plays a critical role in both industry and academia. While Cloud benchmarks are not new, in this novel concept, the authors use a GA to take advantage of the elasticity in Cloud services in a graceful manner that was not previously possible. Using Google App Engine, Heroku, and Python Anywhere with three distinct classes of client computers running our GA codebase, we quantified the completion time for application of the GA to search for the parameters of controllers for dynamical systems. Our results show statistically significant differences in PaaS performance by vendor, and also that the performance of the PaaS performance is dependent upon the client that uses it. Results also show the effectiveness of our GA in determining the level of service of PaaS providers, and for determining if the level of service of one PaaS vendor is repeatable with another. Such a concept could then increase the appeal of PaaS Cloud services by making them more financially appealing.