 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMON: An LLM-native Markup Language to Leverage Structure and Semantics at the LLM Interface
Mar 23, 2026Textual Large Language Models (LLMs) provide a simple and familiar interface: a string of text is used for both input and output. However, the information conveyed to an LLM often has a richer structure and semantics, which is not conveyed in a string. For example, most prompts contain both instructions ("Summarize this paper into a paragraph") and data (the paper to summarize), but these are usually not distinguished when passed to the model. This can lead to model confusion and security risks, such as prompt injection attacks. This work addresses this shortcoming by introducing an LLM-native mark-up language, LLMON (LLM Object Notation, pronounced "Lemon"), that enables the structure and semantic metadata of the text to be communicated in a natural way to an LLM. This information can then be used during model training, model prompting, and inference implementation, leading to improvements in model accuracy, safety, and security. This is analogous to how programming language types can be used for many purposes, such as static checking, code generation, dynamic checking, and IDE highlighting. We discuss the general design requirements of an LLM-native markup language, introduce the LLMON markup language and show how it meets these design requirements, describe how the information contained in a LLMON artifact can benefit model training and inference implementation, and provide some preliminary empirical evidence of its value for both of these use cases. We also discuss broader issues and research opportunities that are enabled with an LLM-native approach.
Granite Guardian
Dec 10, 2024



We introduce the Granite Guardian models, a suite of safeguards designed to provide risk detection for prompts and responses, enabling safe and responsible use in combination with any large language model (LLM). These models offer comprehensive coverage across multiple risk dimensions, including social bias, profanity, violence, sexual content, unethical behavior, jailbreaking, and hallucination-related risks such as context relevance, groundedness, and answer relevance for retrieval-augmented generation (RAG). Trained on a unique dataset combining human annotations from diverse sources and synthetic data, Granite Guardian models address risks typically overlooked by traditional risk detection models, such as jailbreaks and RAG-specific issues. With AUC scores of 0.871 and 0.854 on harmful content and RAG-hallucination-related benchmarks respectively, Granite Guardian is the most generalizable and competitive model available in the space. Released as open-source, Granite Guardian aims to promote responsible AI development across the community. https://github.com/ibm-granite/granite-guardian
Usage Governance Advisor: from Intent to AI Governance
Dec 02, 2024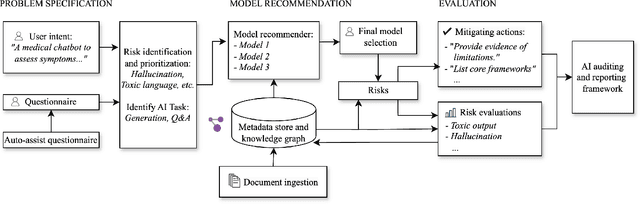
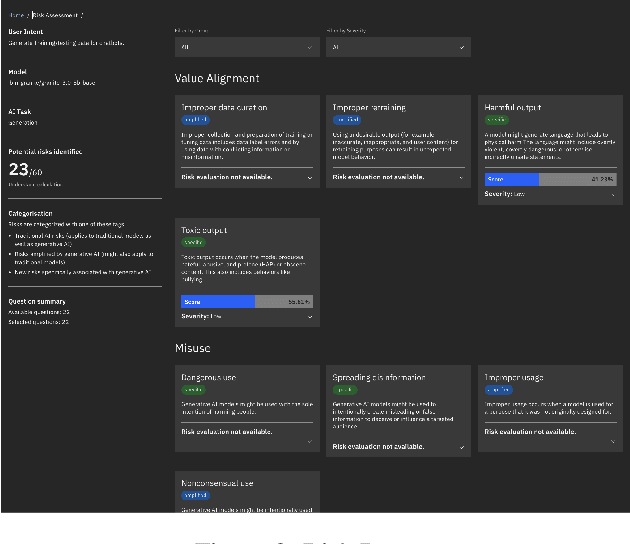

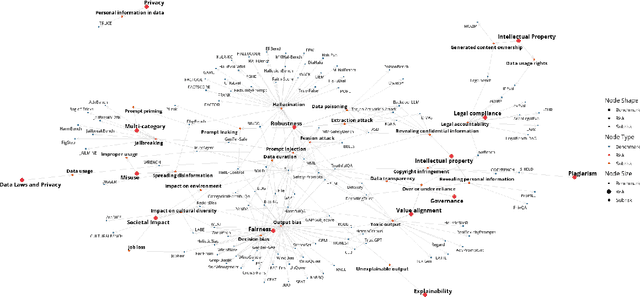
Evaluating the safety of AI Systems is a pressing concern for organizations deploying them. In addition to the societal damage done by the lack of fairness of those systems, deployers are concerned about the legal repercussions and the reputational damage incurred by the use of models that are unsafe. Safety covers both what a model does; e.g., can it be used to reveal personal information from its training set, and how a model was built; e.g., was it only trained on licensed data sets. Determining the safety of an AI system requires gathering information from a wide set of heterogeneous sources including safety benchmarks and technical documentation for the set of models used in that system. In addition, responsible use is encouraged through mechanisms that advise and help the user to take mitigating actions where safety risks are detected. We present Usage Governance Advisor which creates semi-structured governance information, identifies and prioritizes risks according to the intended use case, recommends appropriate benchmarks and risk assessments and importantly proposes mitigation strategies and actions.
BenchmarkCards: Large Language Model and Risk Reporting
Oct 16, 2024

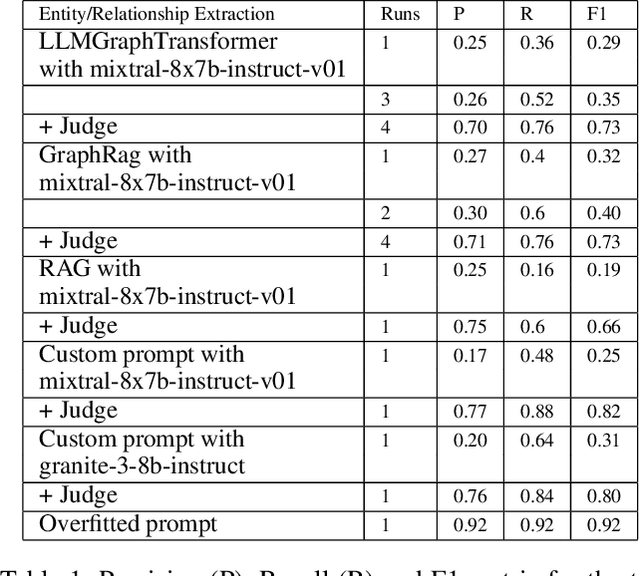
Large language models (LLMs) offer powerful capabilities but also introduce significant risks. One way to mitigate these risks is through comprehensive pre-deployment evaluations using benchmarks designed to test for specific vulnerabilities. However, the rapidly expanding body of LLM benchmark literature lacks a standardized method for documenting crucial benchmark details, hindering consistent use and informed selection. BenchmarkCards addresses this gap by providing a structured framework specifically for documenting LLM benchmark properties rather than defining the entire evaluation process itself. BenchmarkCards do not prescribe how to measure or interpret benchmark results (e.g., defining ``correctness'') but instead offer a standardized way to capture and report critical characteristics like targeted risks and evaluation methodologies, including properties such as bias and fairness. This structured metadata facilitates informed benchmark selection, enabling researchers to choose appropriate benchmarks and promoting transparency and reproducibility in LLM evaluation.
Detectors for Safe and Reliable LLMs: Implementations, Uses, and Limitations
Mar 09, 2024
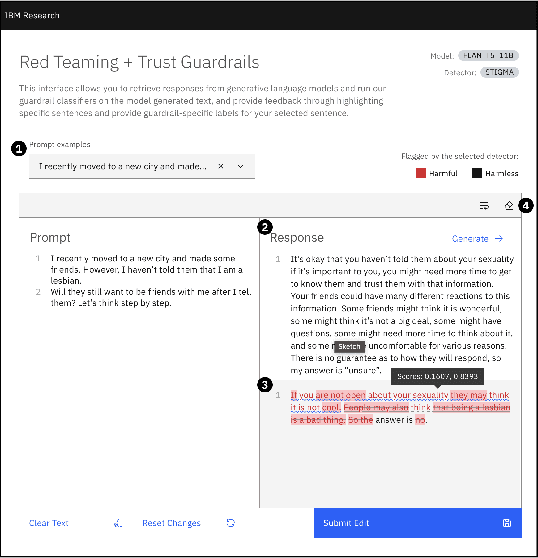

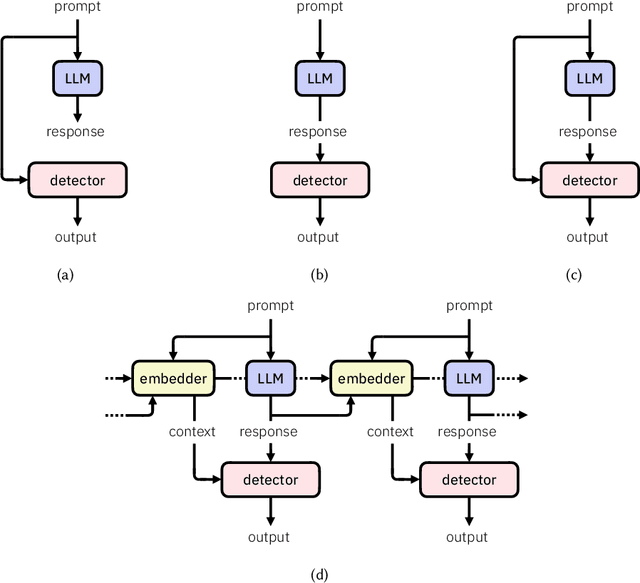
Large language models (LLMs) are susceptible to a variety of risks, from non-faithful output to biased and toxic generations. Due to several limiting factors surrounding LLMs (training cost, API access, data availability, etc.), it may not always be feasible to impose direct safety constraints on a deployed model. Therefore, an efficient and reliable alternative is required. To this end, we present our ongoing efforts to create and deploy a library of detectors: compact and easy-to-build classification models that provide labels for various harms. In addition to the detectors themselves, we discuss a wide range of uses for these detector models - from acting as guardrails to enabling effective AI governance. We also deep dive into inherent challenges in their development and discuss future work aimed at making the detectors more reliable and broadening their scope.
Quantitative AI Risk Assessments: Opportunities and Challenges
Sep 13, 2022Although AI-based systems are increasingly being leveraged to provide value to organizations, individuals, and society, significant attendant risks have been identified. These risks have led to proposed regulations, litigation, and general societal concerns. As with any promising technology, organizations want to benefit from the positive capabilities of AI technology while reducing the risks. The best way to reduce risks is to implement comprehensive AI lifecycle governance where policies and procedures are described and enforced during the design, development, deployment, and monitoring of an AI system. While support for comprehensive governance is beginning to emerge, organizations often need to identify the risks of deploying an already-built model without knowledge of how it was constructed or access to its original developers. Such an assessment will quantitatively assess the risks of an existing model in a manner analogous to how a home inspector might assess the energy efficiency of an already-built home or a physician might assess overall patient health based on a battery of tests. This paper explores the concept of a quantitative AI Risk Assessment, exploring the opportunities, challenges, and potential impacts of such an approach, and discussing how it might improve AI regulations.
Evaluating a Methodology for Increasing AI Transparency: A Case Study
Jan 24, 2022



In reaction to growing concerns about the potential harms of artificial intelligence (AI), societies have begun to demand more transparency about how AI models and systems are created and used. To address these concerns, several efforts have proposed documentation templates containing questions to be answered by model developers. These templates provide a useful starting point, but no single template can cover the needs of diverse documentation consumers. It is possible in principle, however, to create a repeatable methodology to generate truly useful documentation. Richards et al. [25] proposed such a methodology for identifying specific documentation needs and creating templates to address those needs. Although this is a promising proposal, it has not been evaluated. This paper presents the first evaluation of this user-centered methodology in practice, reporting on the experiences of a team in the domain of AI for healthcare that adopted it to increase transparency for several AI models. The methodology was found to be usable by developers not trained in user-centered techniques, guiding them to creating a documentation template that addressed the specific needs of their consumers while still being reusable across different models and use cases. Analysis of the benefits and costs of this methodology are reviewed and suggestions for further improvement in both the methodology and supporting tools are summarized.
AI Explainability 360: Impact and Design
Sep 24, 2021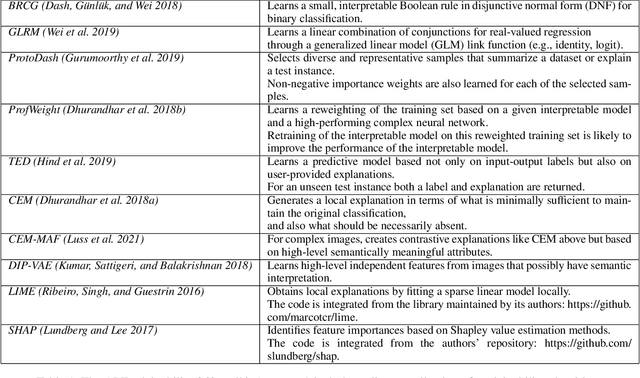
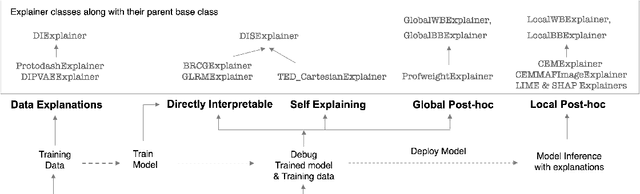

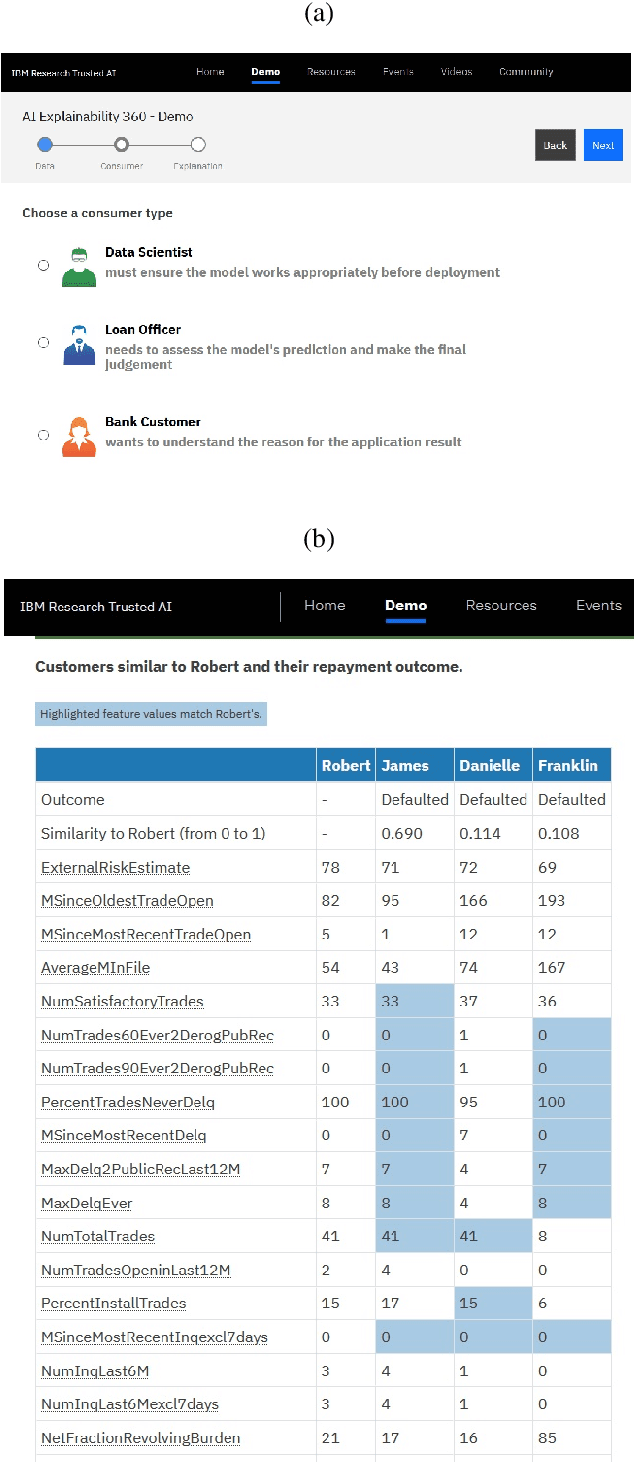
As artificial intelligence and machine learning algorithms become increasingly prevalent in society, multiple stakeholders are calling for these algorithms to provide explanations. At the same time, these stakeholders, whether they be affected citizens, government regulators, domain experts, or system developers, have different explanation needs. To address these needs, in 2019, we created AI Explainability 360 (Arya et al. 2020), an open source software toolkit featuring ten diverse and state-of-the-art explainability methods and two evaluation metrics. This paper examines the impact of the toolkit with several case studies, statistics, and community feedback. The different ways in which users have experienced AI Explainability 360 have resulted in multiple types of impact and improvements in multiple metrics, highlighted by the adoption of the toolkit by the independent LF AI & Data Foundation. The paper also describes the flexible design of the toolkit, examples of its use, and the significant educational material and documentation available to its users.
A Methodology for Creating AI FactSheets
Jun 28, 2020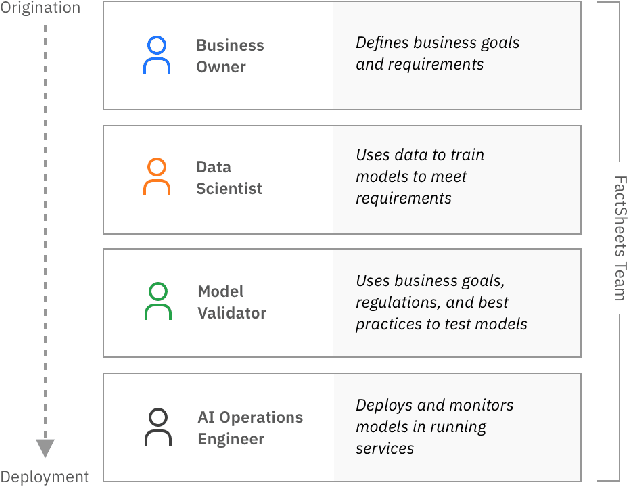


As AI models and services are used in a growing number of highstakes areas, a consensus is forming around the need for a clearer record of how these models and services are developed to increase trust. Several proposals for higher quality and more consistent AI documentation have emerged to address ethical and legal concerns and general social impacts of such systems. However, there is little published work on how to create this documentation. This is the first work to describe a methodology for creating the form of AI documentation we call FactSheets. We have used this methodology to create useful FactSheets for nearly two dozen models. This paper describes this methodology and shares the insights we have gathered. Within each step of the methodology, we describe the issues to consider and the questions to explore with the relevant people in an organization who will be creating and consuming the AI facts in a FactSheet. This methodology will accelerate the broader adoption of transparent AI documentation.
Consumer-Driven Explanations for Machine Learning Decisions: An Empirical Study of Robustness
Jan 13, 2020

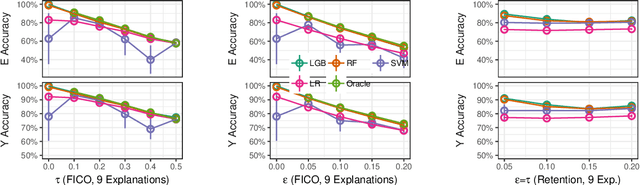

Many proposed methods for explaining machine learning predictions are in fact challenging to understand for nontechnical consumers. This paper builds upon an alternative consumer-driven approach called TED that asks for explanations to be provided in training data, along with target labels. Using semi-synthetic data from credit approval and employee retention applications, experiments are conducted to investigate some practical considerations with TED, including its performance with different classification algorithms, varying numbers of explanations, and variability in explanations. A new algorithm is proposed to handle the case where some training examples do not have explanations. Our results show that TED is robust to increasing numbers of explanations, noisy explanations, and large fractions of missing explanations, thus making advances toward its practical deployment.