 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-BenchmarkCard: Automated Synthesis of Benchmark Documentation
Dec 10, 2025We present Auto-BenchmarkCard, a workflow for generating validated descriptions of AI benchmarks. Benchmark documentation is often incomplete or inconsistent, making it difficult to interpret and compare benchmarks across tasks or domains. Auto-BenchmarkCard addresses this gap by combining multi-agent data extraction from heterogeneous sources (e.g., Hugging Face, Unitxt, academic papers) with LLM-driven synthesis. A validation phase evaluates factual accuracy through atomic entailment scoring using the FactReasoner tool. This workflow has the potential to promote transparency, comparability, and reusability in AI benchmark reporting, enabling researchers and practitioners to better navigate and evaluate benchmark choices.
Forging Time Series with Language: A Large Language Model Approach to Synthetic Data Generation
May 21, 2025



SDForger is a flexible and efficient framework for generating high-quality multivariate time series using LLMs. Leveraging a compact data representation, SDForger provides synthetic time series generation from a few samples and low-computation fine-tuning of any autoregressive LLM. Specifically, the framework transforms univariate and multivariate signals into tabular embeddings, which are then encoded into text and used to fine-tune the LLM. At inference, new textual embeddings are sampled and decoded into synthetic time series that retain the original data's statistical properties and temporal dynamics. Across a diverse range of datasets, SDForger outperforms existing generative models in many scenarios, both in similarity-based evaluations and downstream forecasting tasks. By enabling textual conditioning in the generation process, SDForger paves the way for multimodal modeling and the streamlined integration of time series with textual information. SDForger source code will be open-sourced soon.
Usage Governance Advisor: from Intent to AI Governance
Dec 02, 2024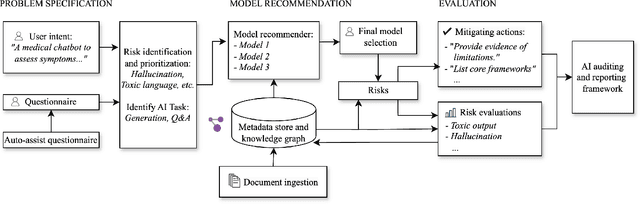
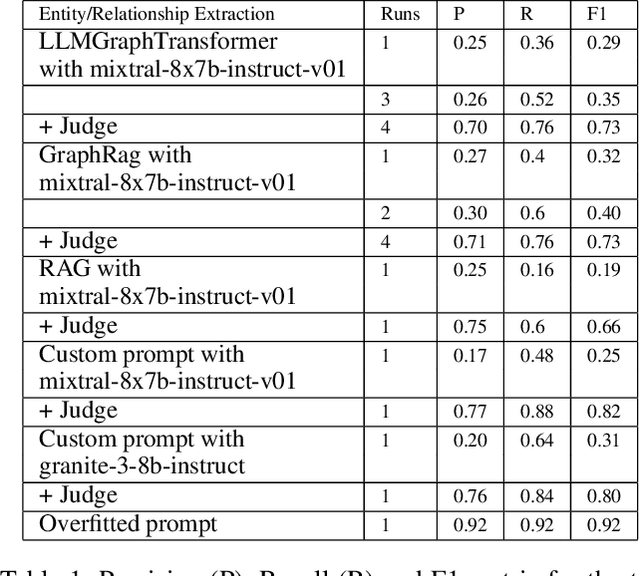
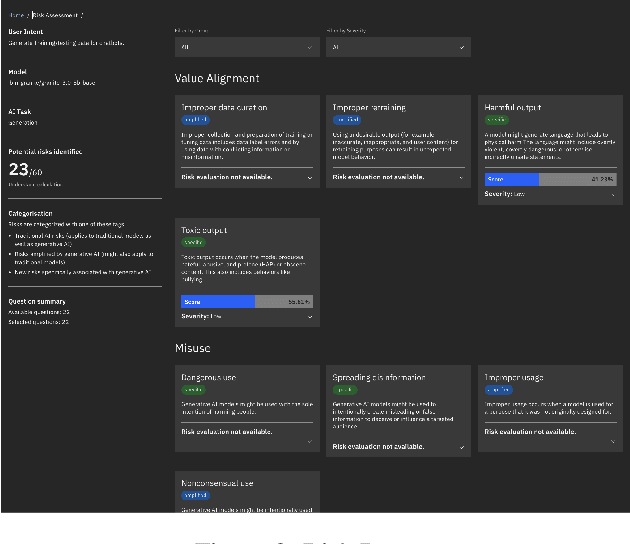

Evaluating the safety of AI Systems is a pressing concern for organizations deploying them. In addition to the societal damage done by the lack of fairness of those systems, deployers are concerned about the legal repercussions and the reputational damage incurred by the use of models that are unsafe. Safety covers both what a model does; e.g., can it be used to reveal personal information from its training set, and how a model was built; e.g., was it only trained on licensed data sets. Determining the safety of an AI system requires gathering information from a wide set of heterogeneous sources including safety benchmarks and technical documentation for the set of models used in that system. In addition, responsible use is encouraged through mechanisms that advise and help the user to take mitigating actions where safety risks are detected. We present Usage Governance Advisor which creates semi-structured governance information, identifies and prioritizes risks according to the intended use case, recommends appropriate benchmarks and risk assessments and importantly proposes mitigation strategies and actions.
VID-WIN: Fast Video Event Matching with Query-Aware Windowing at the Edge for the Internet of Multimedia Things
Apr 27, 2021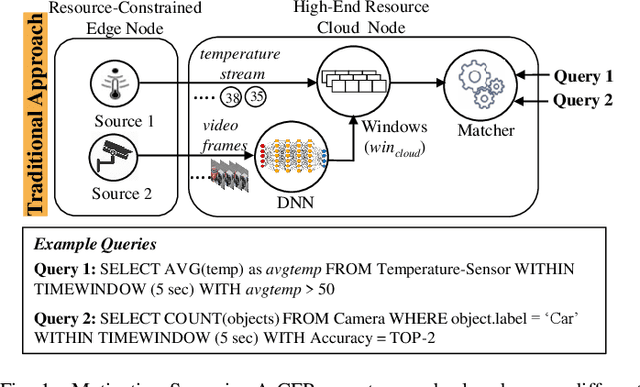
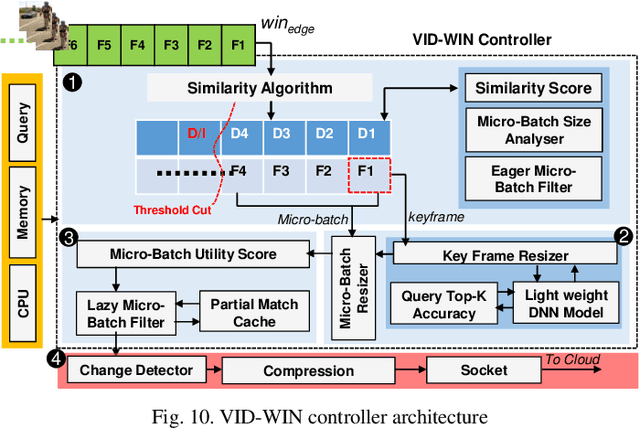
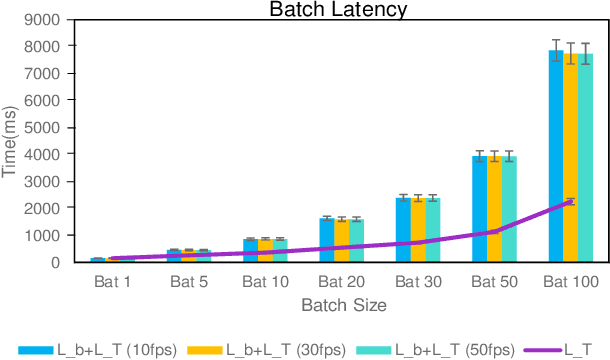
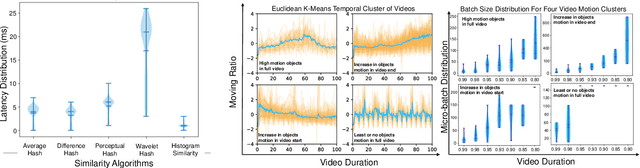
Efficient video processing is a critical component in many IoMT applications to detect events of interest. Presently, many window optimization techniques have been proposed in event processing with an underlying assumption that the incoming stream has a structured data model. Videos are highly complex due to the lack of any underlying structured data model. Video stream sources such as CCTV cameras and smartphones are resource-constrained edge nodes. At the same time, video content extraction is expensive and requires computationally intensive Deep Neural Network (DNN) models that are primarily deployed at high-end (or cloud) nodes. This paper presents VID-WIN, an adaptive 2-stage allied windowing approach to accelerate video event analytics in an edge-cloud paradigm. VID-WIN runs parallelly across edge and cloud nodes and performs the query and resource-aware optimization for state-based complex event matching. VID-WIN exploits the video content and DNN input knobs to accelerate the video inference process across nodes. The paper proposes a novel content-driven micro-batch resizing, queryaware caching and micro-batch based utility filtering strategy of video frames under resource-constrained edge nodes to improve the overall system throughput, latency, and network usage. Extensive evaluations are performed over five real-world datasets. The experimental results show that VID-WIN video event matching achieves ~2.3X higher throughput with minimal latency and ~99% bandwidth reduction compared to other baselines while maintaining query-level accuracy and resource bounds.
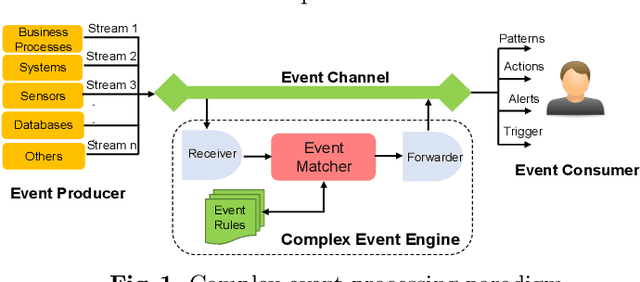
Knowledge Graph Driven Approach to Represent Video Streams for Spatiotemporal Event Pattern Matching in Complex Event Processing
Jul 13, 2020

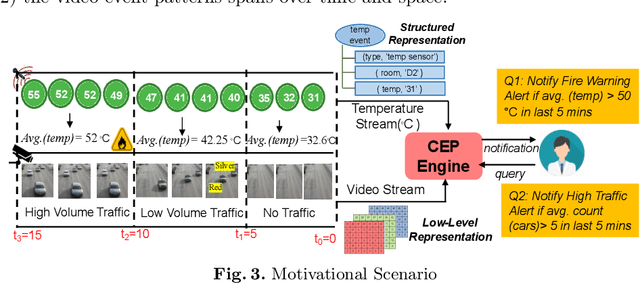
Complex Event Processing (CEP) is an event processing paradigm to perform real-time analytics over streaming data and match high-level event patterns. Presently, CEP is limited to process structured data stream. Video streams are complicated due to their unstructured data model and limit CEP systems to perform matching over them. This work introduces a graph-based structure for continuous evolving video streams, which enables the CEP system to query complex video event patterns. We propose the Video Event Knowledge Graph (VEKG), a graph driven representation of video data. VEKG models video objects as nodes and their relationship interaction as edges over time and space. It creates a semantic knowledge representation of video data derived from the detection of high-level semantic concepts from the video using an ensemble of deep learning models. A CEP-based state optimization - VEKG-Time Aggregated Graph (VEKG-TAG) is proposed over VEKG representation for faster event detection. VEKG-TAG is a spatiotemporal graph aggregation method that provides a summarized view of the VEKG graph over a given time length. We defined a set of nine event pattern rules for two domains (Activity Recognition and Traffic Management), which act as a query and applied over VEKG graphs to discover complex event patterns. To show the efficacy of our approach, we performed extensive experiments over 801 video clips across 10 datasets. The proposed VEKG approach was compared with other state-of-the-art methods and was able to detect complex event patterns over videos with F-Score ranging from 0.44 to 0.90. In the given experiments, the optimized VEKG-TAG was able to reduce 99% and 93% of VEKG nodes and edges, respectively, with 5.19X faster search time, achieving sub-second median latency of 4-20 milliseconds.