 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Steerability 360: A Toolkit for Steering Large Language Models
Mar 08, 2026The AI Steerability 360 toolkit is an extensible, open-source Python library for steering LLMs. Steering abstractions are designed around four model control surfaces: input (modification of the prompt), structural (modification of the model's weights or architecture), state (modification of the model's activations and attentions), and output (modification of the decoding or generation process). Steering methods exert control on the model through a common interface, termed a steering pipeline, which additionally allows for the composition of multiple steering methods. Comprehensive evaluation and comparison of steering methods/pipelines is facilitated by use case classes (for defining tasks) and a benchmark class (for performance comparison on a given task). The functionality provided by the toolkit significantly lowers the barrier to developing and comprehensively evaluating steering methods. The toolkit is Hugging Face native and is released under an Apache 2.0 license at https://github.com/IBM/AISteer360.
Auto-BenchmarkCard: Automated Synthesis of Benchmark Documentation
Dec 10, 2025We present Auto-BenchmarkCard, a workflow for generating validated descriptions of AI benchmarks. Benchmark documentation is often incomplete or inconsistent, making it difficult to interpret and compare benchmarks across tasks or domains. Auto-BenchmarkCard addresses this gap by combining multi-agent data extraction from heterogeneous sources (e.g., Hugging Face, Unitxt, academic papers) with LLM-driven synthesis. A validation phase evaluates factual accuracy through atomic entailment scoring using the FactReasoner tool. This workflow has the potential to promote transparency, comparability, and reusability in AI benchmark reporting, enabling researchers and practitioners to better navigate and evaluate benchmark choices.
ICX360: In-Context eXplainability 360 Toolkit
Nov 14, 2025Large Language Models (LLMs) have become ubiquitous in everyday life and are entering higher-stakes applications ranging from summarizing meeting transcripts to answering doctors' questions. As was the case with earlier predictive models, it is crucial that we develop tools for explaining the output of LLMs, be it a summary, list, response to a question, etc. With these needs in mind, we introduce In-Context Explainability 360 (ICX360), an open-source Python toolkit for explaining LLMs with a focus on the user-provided context (or prompts in general) that are fed to the LLMs. ICX360 contains implementations for three recent tools that explain LLMs using both black-box and white-box methods (via perturbations and gradients respectively). The toolkit, available at https://github.com/IBM/ICX360, contains quick-start guidance materials as well as detailed tutorials covering use cases such as retrieval augmented generation, natural language generation, and jailbreaking.
Humble AI in the real-world: the case of algorithmic hiring
May 27, 2025Humble AI (Knowles et al., 2023) argues for cautiousness in AI development and deployments through scepticism (accounting for limitations of statistical learning), curiosity (accounting for unexpected outcomes), and commitment (accounting for multifaceted values beyond performance). We present a real-world case study for humble AI in the domain of algorithmic hiring. Specifically, we evaluate virtual screening algorithms in a widely used hiring platform that matches candidates to job openings. There are several challenges in misrecognition and stereotyping in such contexts that are difficult to assess through standard fairness and trust frameworks; e.g., someone with a non-traditional background is less likely to rank highly. We demonstrate technical feasibility of how humble AI principles can be translated to practice through uncertainty quantification of ranks, entropy estimates, and a user experience that highlights algorithmic unknowns. We describe preliminary discussions with focus groups made up of recruiters. Future user studies seek to evaluate whether the higher cognitive load of a humble AI system fosters a climate of trust in its outcomes.
Granite Guardian
Dec 10, 2024



We introduce the Granite Guardian models, a suite of safeguards designed to provide risk detection for prompts and responses, enabling safe and responsible use in combination with any large language model (LLM). These models offer comprehensive coverage across multiple risk dimensions, including social bias, profanity, violence, sexual content, unethical behavior, jailbreaking, and hallucination-related risks such as context relevance, groundedness, and answer relevance for retrieval-augmented generation (RAG). Trained on a unique dataset combining human annotations from diverse sources and synthetic data, Granite Guardian models address risks typically overlooked by traditional risk detection models, such as jailbreaks and RAG-specific issues. With AUC scores of 0.871 and 0.854 on harmful content and RAG-hallucination-related benchmarks respectively, Granite Guardian is the most generalizable and competitive model available in the space. Released as open-source, Granite Guardian aims to promote responsible AI development across the community. https://github.com/ibm-granite/granite-guardian
Usage Governance Advisor: from Intent to AI Governance
Dec 02, 2024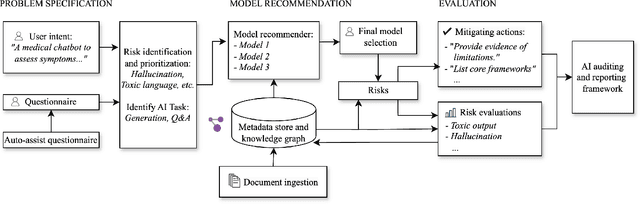
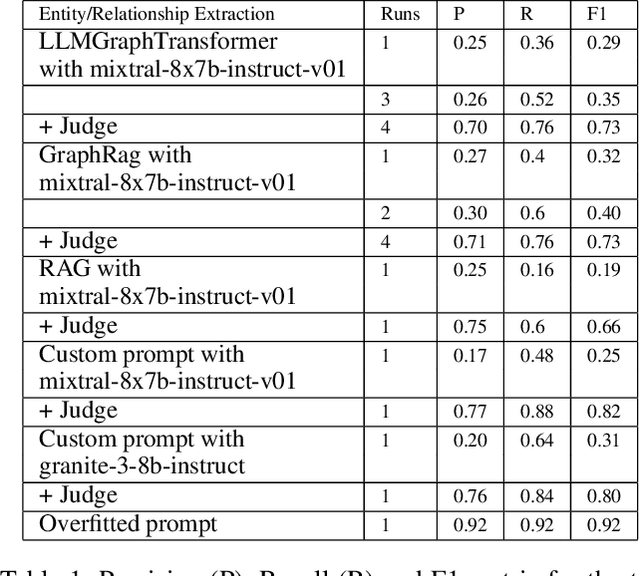
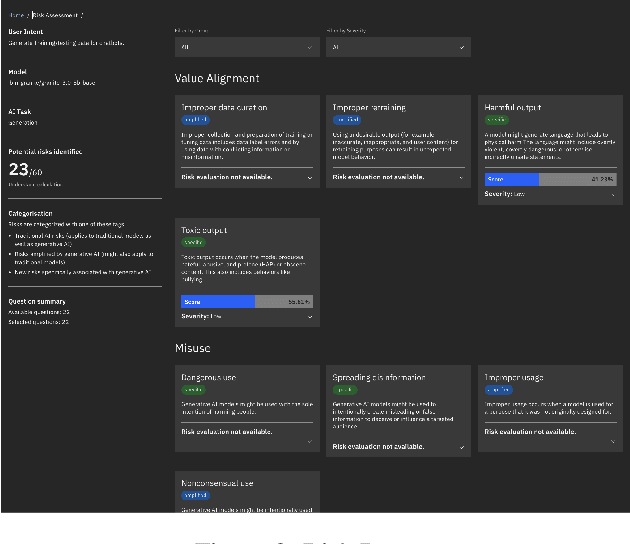

Evaluating the safety of AI Systems is a pressing concern for organizations deploying them. In addition to the societal damage done by the lack of fairness of those systems, deployers are concerned about the legal repercussions and the reputational damage incurred by the use of models that are unsafe. Safety covers both what a model does; e.g., can it be used to reveal personal information from its training set, and how a model was built; e.g., was it only trained on licensed data sets. Determining the safety of an AI system requires gathering information from a wide set of heterogeneous sources including safety benchmarks and technical documentation for the set of models used in that system. In addition, responsible use is encouraged through mechanisms that advise and help the user to take mitigating actions where safety risks are detected. We present Usage Governance Advisor which creates semi-structured governance information, identifies and prioritizes risks according to the intended use case, recommends appropriate benchmarks and risk assessments and importantly proposes mitigation strategies and actions.
AutoDOViz: Human-Centered Automation for Decision Optimization
Feb 19, 2023



We present AutoDOViz, an interactive user interface for automated decision optimization (AutoDO) using reinforcement learning (RL). Decision optimization (DO) has classically being practiced by dedicated DO researchers where experts need to spend long periods of time fine tuning a solution through trial-and-error. AutoML pipeline search has sought to make it easier for a data scientist to find the best machine learning pipeline by leveraging automation to search and tune the solution. More recently, these advances have been applied to the domain of AutoDO, with a similar goal to find the best reinforcement learning pipeline through algorithm selection and parameter tuning. However, Decision Optimization requires significantly more complex problem specification when compared to an ML problem. AutoDOViz seeks to lower the barrier of entry for data scientists in problem specification for reinforcement learning problems, leverage the benefits of AutoDO algorithms for RL pipeline search and finally, create visualizations and policy insights in order to facilitate the typical interactive nature when communicating problem formulation and solution proposals between DO experts and domain experts. In this paper, we report our findings from semi-structured expert interviews with DO practitioners as well as business consultants, leading to design requirements for human-centered automation for DO with RL. We evaluate a system implementation with data scientists and find that they are significantly more open to engage in DO after using our proposed solution. AutoDOViz further increases trust in RL agent models and makes the automated training and evaluation process more comprehensible. As shown for other automation in ML tasks, we also conclude automation of RL for DO can benefit from user and vice-versa when the interface promotes human-in-the-loop.