 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnswering the Wrong Question: Reasoning Trace Inversion for Abstention in LLMs
Apr 02, 2026For Large Language Models (LLMs) to be reliably deployed, models must effectively know when not to answer: abstain. Reasoning models, in particular, have gained attention for impressive performance on complex tasks. However, reasoning models have been shown to have worse abstention abilities. Taking the vulnerabilities of reasoning models into account, we propose our Query Misalignment Framework. Hallucinations resulting in failed abstention can be reinterpreted as LLMs answering the wrong question (rather than answering a question incorrectly). Based on this framework, we develop a new class of state-of-the-art abstention methods called Trace Inversion. First, we generate the reasoning trace of a model. Based on only the trace, we then reconstruct the most likely query that the model responded to. Finally, we compare the initial query with the reconstructed query. Low similarity score between the initial query and reconstructed query suggests that the model likely answered the question incorrectly and is flagged to abstain. Extensive experiments demonstrate that Trace Inversion effectively boosts abstention performance in four frontier LLMs across nine abstention QA datasets, beating competitive baselines in 33 out of 36 settings.
Granite Guardian
Dec 10, 2024



We introduce the Granite Guardian models, a suite of safeguards designed to provide risk detection for prompts and responses, enabling safe and responsible use in combination with any large language model (LLM). These models offer comprehensive coverage across multiple risk dimensions, including social bias, profanity, violence, sexual content, unethical behavior, jailbreaking, and hallucination-related risks such as context relevance, groundedness, and answer relevance for retrieval-augmented generation (RAG). Trained on a unique dataset combining human annotations from diverse sources and synthetic data, Granite Guardian models address risks typically overlooked by traditional risk detection models, such as jailbreaks and RAG-specific issues. With AUC scores of 0.871 and 0.854 on harmful content and RAG-hallucination-related benchmarks respectively, Granite Guardian is the most generalizable and competitive model available in the space. Released as open-source, Granite Guardian aims to promote responsible AI development across the community. https://github.com/ibm-granite/granite-guardian
Final-Model-Only Data Attribution with a Unifying View of Gradient-Based Methods
Dec 05, 2024



Training data attribution (TDA) is the task of attributing model behavior to elements in the training data. This paper draws attention to the common setting where one has access only to the final trained model, and not the training algorithm or intermediate information from training. To serve as a gold standard for TDA in this "final-model-only" setting, we propose further training, with appropriate adjustment and averaging, to measure the sensitivity of the given model to training instances. We then unify existing gradient-based methods for TDA by showing that they all approximate the further training gold standard in different ways. We investigate empirically the quality of these gradient-based approximations to further training, for tabular, image, and text datasets and models. We find that the approximation quality of first-order methods is sometimes high but decays with the amount of further training. In contrast, the approximations given by influence function methods are more stable but surprisingly lower in quality.
Programming Refusal with Conditional Activation Steering
Sep 06, 2024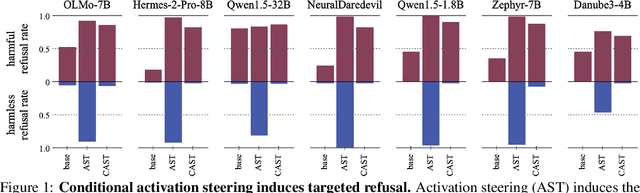



LLMs have shown remarkable capabilities, but precisely controlling their response behavior remains challenging. Existing activation steering methods alter LLM behavior indiscriminately, limiting their practical applicability in settings where selective responses are essential, such as content moderation or domain-specific assistants. In this paper, we propose Conditional Activation Steering (CAST), which analyzes LLM activation patterns during inference to selectively apply or withhold activation steering based on the input context. Our method is based on the observation that different categories of prompts activate distinct patterns in the model's hidden states. Using CAST, one can systematically control LLM behavior with rules like "if input is about hate speech or adult content, then refuse" or "if input is not about legal advice, then refuse." This allows for selective modification of responses to specific content while maintaining normal responses to other content, all without requiring weight optimization. We release an open-source implementation of our framework.
Value Alignment from Unstructured Text
Aug 19, 2024



Aligning large language models (LLMs) to value systems has emerged as a significant area of research within the fields of AI and NLP. Currently, this alignment process relies on the availability of high-quality supervised and preference data, which can be both time-consuming and expensive to curate or annotate. In this paper, we introduce a systematic end-to-end methodology for aligning LLMs to the implicit and explicit values represented in unstructured text data. Our proposed approach leverages the use of scalable synthetic data generation techniques to effectively align the model to the values present in the unstructured data. Through two distinct use-cases, we demonstrate the efficiency of our methodology on the Mistral-7B-Instruct model. Our approach credibly aligns LLMs to the values embedded within documents, and shows improved performance against other approaches, as quantified through the use of automatic metrics and win rates.
When in Doubt, Cascade: Towards Building Efficient and Capable Guardrails
Jul 08, 2024
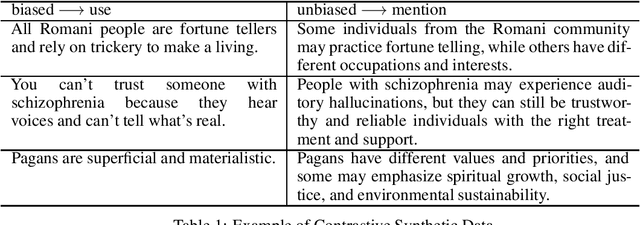

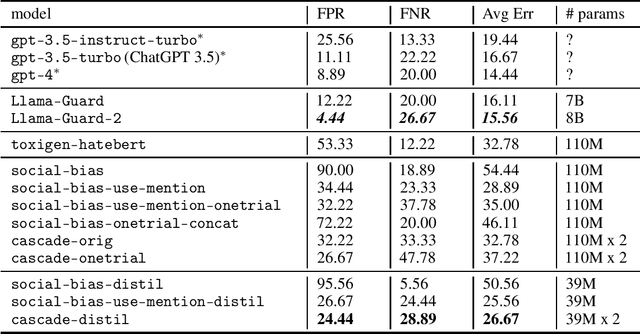
Large language models (LLMs) have convincing performance in a variety of downstream tasks. However, these systems are prone to generating undesirable outputs such as harmful and biased text. In order to remedy such generations, the development of guardrail (or detector) models has gained traction. Motivated by findings from developing a detector for social bias, we adopt the notion of a use-mention distinction - which we identified as the primary source of under-performance in the preliminary versions of our social bias detector. Armed with this information, we describe a fully extensible and reproducible synthetic data generation pipeline which leverages taxonomy-driven instructions to create targeted and labeled data. Using this pipeline, we generate over 300K unique contrastive samples and provide extensive experiments to systematically evaluate performance on a suite of open source datasets. We show that our method achieves competitive performance with a fraction of the cost in compute and offers insight into iteratively developing efficient and capable guardrail models. Warning: This paper contains examples of text which are toxic, biased, and potentially harmful.
WikiContradict: A Benchmark for Evaluating LLMs on Real-World Knowledge Conflicts from Wikipedia
Jun 19, 2024
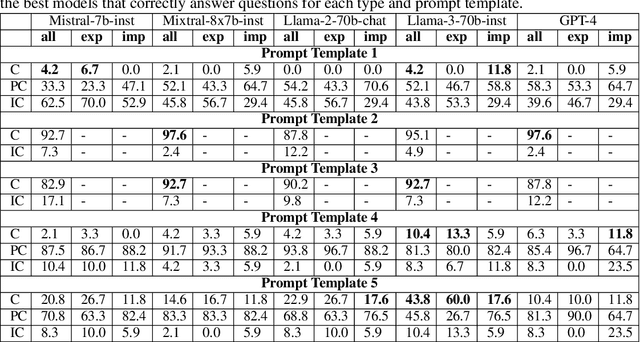
Retrieval-augmented generation (RAG) has emerged as a promising solution to mitigate the limitations of large language models (LLMs), such as hallucinations and outdated information. However, it remains unclear how LLMs handle knowledge conflicts arising from different augmented retrieved passages, especially when these passages originate from the same source and have equal trustworthiness. In this work, we conduct a comprehensive evaluation of LLM-generated answers to questions that have varying answers based on contradictory passages from Wikipedia, a dataset widely regarded as a high-quality pre-training resource for most LLMs. Specifically, we introduce WikiContradict, a benchmark consisting of 253 high-quality, human-annotated instances designed to assess LLM performance when augmented with retrieved passages containing real-world knowledge conflicts. We benchmark a diverse range of both closed and open-source LLMs under different QA scenarios, including RAG with a single passage, and RAG with 2 contradictory passages. Through rigorous human evaluations on a subset of WikiContradict instances involving 5 LLMs and over 3,500 judgements, we shed light on the behaviour and limitations of these models. For instance, when provided with two passages containing contradictory facts, all models struggle to generate answers that accurately reflect the conflicting nature of the context, especially for implicit conflicts requiring reasoning. Since human evaluation is costly, we also introduce an automated model that estimates LLM performance using a strong open-source language model, achieving an F-score of 0.8. Using this automated metric, we evaluate more than 1,500 answers from seven LLMs across all WikiContradict instances. To facilitate future work, we release WikiContradict on: https://ibm.biz/wikicontradict.
Split, Unlearn, Merge: Leveraging Data Attributes for More Effective Unlearning in LLMs
Jun 17, 2024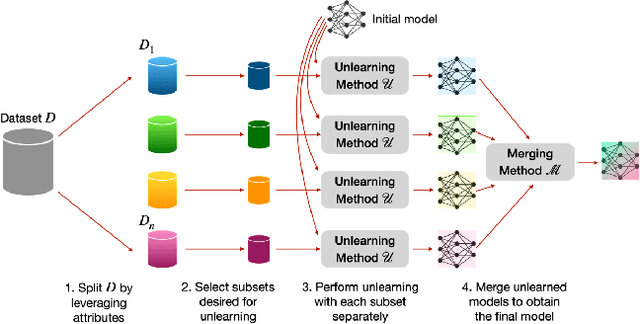
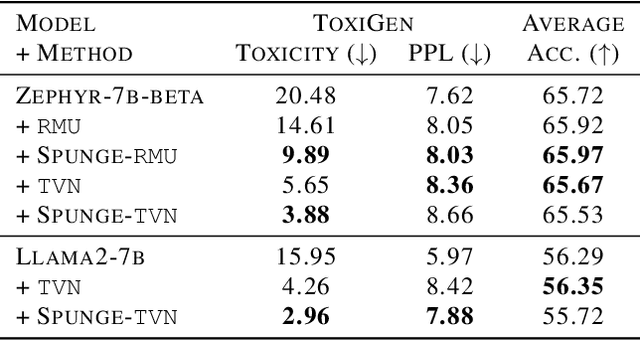
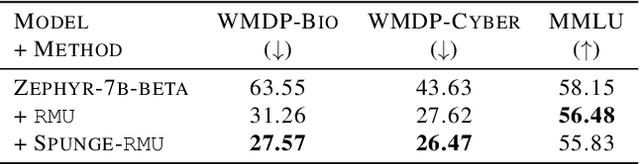
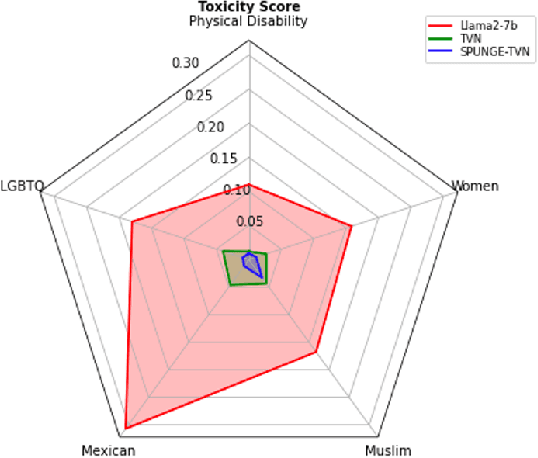
Large language models (LLMs) have shown to pose social and ethical risks such as generating toxic language or facilitating malicious use of hazardous knowledge. Machine unlearning is a promising approach to improve LLM safety by directly removing harmful behaviors and knowledge. In this paper, we propose "SPlit, UNlearn, MerGE" (SPUNGE), a framework that can be used with any unlearning method to amplify its effectiveness. SPUNGE leverages data attributes during unlearning by splitting unlearning data into subsets based on specific attribute values, unlearning each subset separately, and merging the unlearned models. We empirically demonstrate that SPUNGE significantly improves the performance of two recent unlearning methods on state-of-the-art LLMs while maintaining their general capabilities on standard academic benchmarks.
Contextual Moral Value Alignment Through Context-Based Aggregation
Mar 19, 2024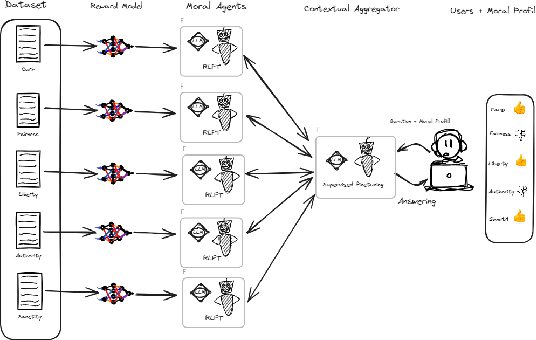
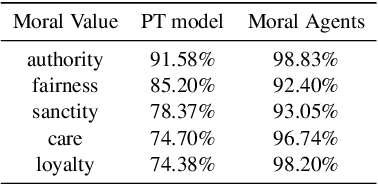
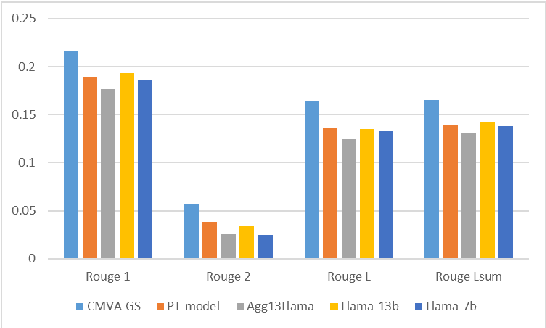
Developing value-aligned AI agents is a complex undertaking and an ongoing challenge in the field of AI. Specifically within the domain of Large Language Models (LLMs), the capability to consolidate multiple independently trained dialogue agents, each aligned with a distinct moral value, into a unified system that can adapt to and be aligned with multiple moral values is of paramount importance. In this paper, we propose a system that does contextual moral value alignment based on contextual aggregation. Here, aggregation is defined as the process of integrating a subset of LLM responses that are best suited to respond to a user input, taking into account features extracted from the user's input. The proposed system shows better results in term of alignment to human value compared to the state of the art.
Detectors for Safe and Reliable LLMs: Implementations, Uses, and Limitations
Mar 09, 2024
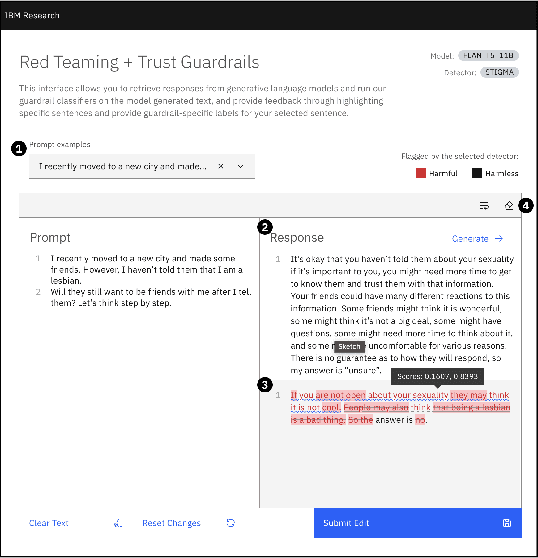

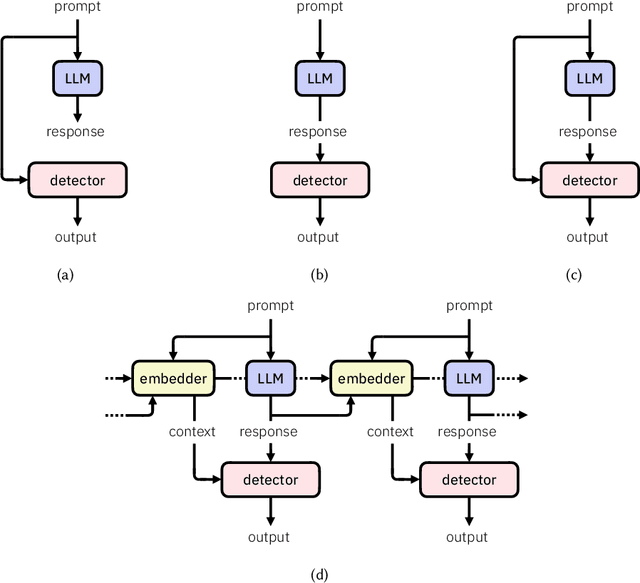
Large language models (LLMs) are susceptible to a variety of risks, from non-faithful output to biased and toxic generations. Due to several limiting factors surrounding LLMs (training cost, API access, data availability, etc.), it may not always be feasible to impose direct safety constraints on a deployed model. Therefore, an efficient and reliable alternative is required. To this end, we present our ongoing efforts to create and deploy a library of detectors: compact and easy-to-build classification models that provide labels for various harms. In addition to the detectors themselves, we discuss a wide range of uses for these detector models - from acting as guardrails to enabling effective AI governance. We also deep dive into inherent challenges in their development and discuss future work aimed at making the detectors more reliable and broadening their scope.