 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Examiner: Evaluating Consistency of Large Language Model-Generated Explanations
Mar 11, 2025Large Language Models (LLMs) are often asked to explain their outputs to enhance accuracy and transparency. However, evidence suggests that these explanations can misrepresent the models' true reasoning processes. One effective way to identify inaccuracies or omissions in these explanations is through consistency checking, which typically involves asking follow-up questions. This paper introduces, cross-examiner, a new method for generating follow-up questions based on a model's explanation of an initial question. Our method combines symbolic information extraction with language model-driven question generation, resulting in better follow-up questions than those produced by LLMs alone. Additionally, this approach is more flexible than other methods and can generate a wider variety of follow-up questions.
Few-shot Policy (de)composition in Conversational Question Answering
Jan 20, 2025



The task of policy compliance detection (PCD) is to determine if a scenario is in compliance with respect to a set of written policies. In a conversational setting, the results of PCD can indicate if clarifying questions must be asked to determine compliance status. Existing approaches usually claim to have reasoning capabilities that are latent or require a large amount of annotated data. In this work, we propose logical decomposition for policy compliance (LDPC): a neuro-symbolic framework to detect policy compliance using large language models (LLMs) in a few-shot setting. By selecting only a few exemplars alongside recently developed prompting techniques, we demonstrate that our approach soundly reasons about policy compliance conversations by extracting sub-questions to be answered, assigning truth values from contextual information, and explicitly producing a set of logic statements from the given policies. The formulation of explicit logic graphs can in turn help answer PCDrelated questions with increased transparency and explainability. We apply this approach to the popular PCD and conversational machine reading benchmark, ShARC, and show competitive performance with no task-specific finetuning. We also leverage the inherently interpretable architecture of LDPC to understand where errors occur, revealing ambiguities in the ShARC dataset and highlighting the challenges involved with reasoning for conversational question answering.
Final-Model-Only Data Attribution with a Unifying View of Gradient-Based Methods
Dec 05, 2024



Training data attribution (TDA) is the task of attributing model behavior to elements in the training data. This paper draws attention to the common setting where one has access only to the final trained model, and not the training algorithm or intermediate information from training. To serve as a gold standard for TDA in this "final-model-only" setting, we propose further training, with appropriate adjustment and averaging, to measure the sensitivity of the given model to training instances. We then unify existing gradient-based methods for TDA by showing that they all approximate the further training gold standard in different ways. We investigate empirically the quality of these gradient-based approximations to further training, for tabular, image, and text datasets and models. We find that the approximation quality of first-order methods is sometimes high but decays with the amount of further training. In contrast, the approximations given by influence function methods are more stable but surprisingly lower in quality.
Reasoning about concepts with LLMs: Inconsistencies abound
May 30, 2024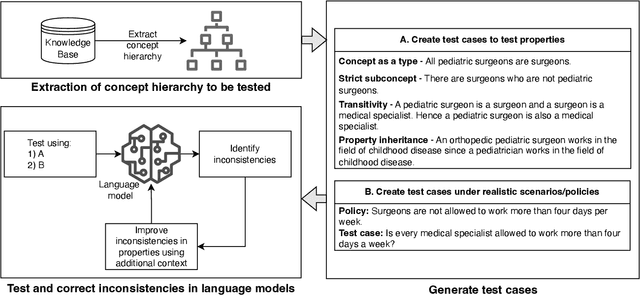
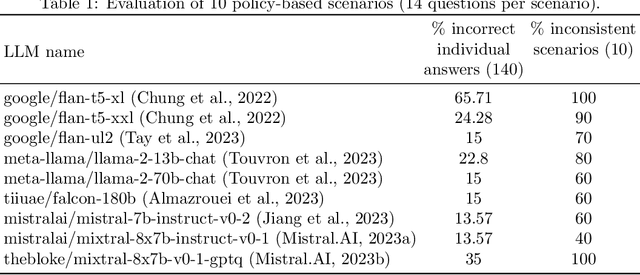
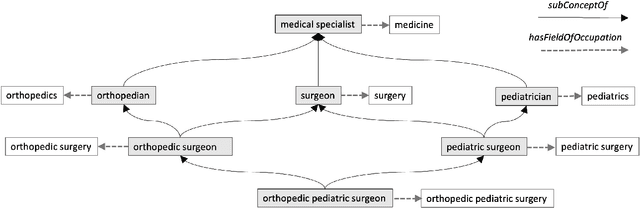
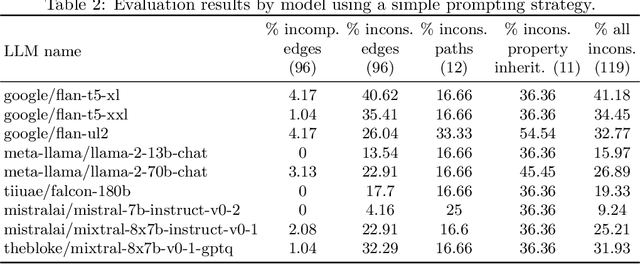
The ability to summarize and organize knowledge into abstract concepts is key to learning and reasoning. Many industrial applications rely on the consistent and systematic use of concepts, especially when dealing with decision-critical knowledge. However, we demonstrate that, when methodically questioned, large language models (LLMs) often display and demonstrate significant inconsistencies in their knowledge. Computationally, the basic aspects of the conceptualization of a given domain can be represented as Is-A hierarchies in a knowledge graph (KG) or ontology, together with a few properties or axioms that enable straightforward reasoning. We show that even simple ontologies can be used to reveal conceptual inconsistencies across several LLMs. We also propose strategies that domain experts can use to evaluate and improve the coverage of key domain concepts in LLMs of various sizes. In particular, we have been able to significantly enhance the performance of LLMs of various sizes with openly available weights using simple knowledge-graph (KG) based prompting strategies.
Alignment Studio: Aligning Large Language Models to Particular Contextual Regulations
Mar 08, 2024The alignment of large language models is usually done by model providers to add or control behaviors that are common or universally understood across use cases and contexts. In contrast, in this article, we present an approach and architecture that empowers application developers to tune a model to their particular values, social norms, laws and other regulations, and orchestrate between potentially conflicting requirements in context. We lay out three main components of such an Alignment Studio architecture: Framers, Instructors, and Auditors that work in concert to control the behavior of a language model. We illustrate this approach with a running example of aligning a company's internal-facing enterprise chatbot to its business conduct guidelines.
Neuro-symbolic Models for Interpretable Time Series Classification using Temporal Logic Description
Sep 15, 2022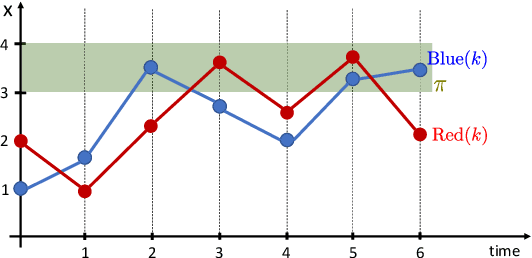
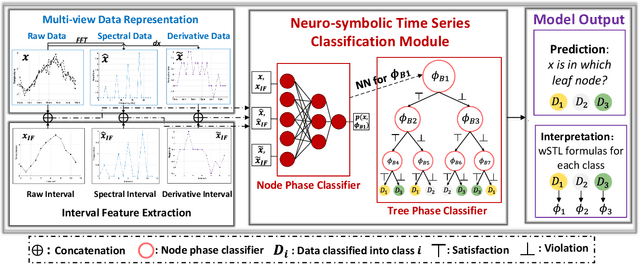
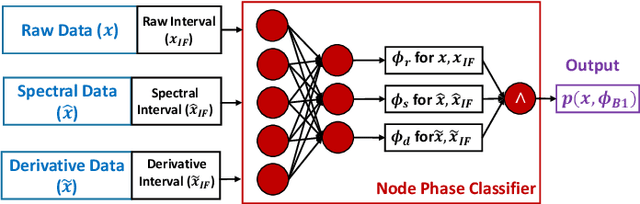
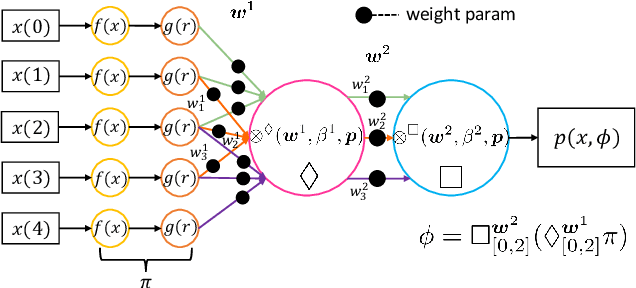
Most existing Time series classification (TSC) models lack interpretability and are difficult to inspect. Interpretable machine learning models can aid in discovering patterns in data as well as give easy-to-understand insights to domain specialists. In this study, we present Neuro-Symbolic Time Series Classification (NSTSC), a neuro-symbolic model that leverages signal temporal logic (STL) and neural network (NN) to accomplish TSC tasks using multi-view data representation and expresses the model as a human-readable, interpretable formula. In NSTSC, each neuron is linked to a symbolic expression, i.e., an STL (sub)formula. The output of NSTSC is thus interpretable as an STL formula akin to natural language, describing temporal and logical relations hidden in the data. We propose an NSTSC-based classifier that adopts a decision-tree approach to learn formula structures and accomplish a multiclass TSC task. The proposed smooth activation functions for wSTL allow the model to be learned in an end-to-end fashion. We test NSTSC on a real-world wound healing dataset from mice and benchmark datasets from the UCR time-series repository, demonstrating that NSTSC achieves comparable performance with the state-of-the-art models. Furthermore, NSTSC can generate interpretable formulas that match with domain knowledge.
A Benchmark for Generalizable and Interpretable Temporal Question Answering over Knowledge Bases
Jan 15, 2022
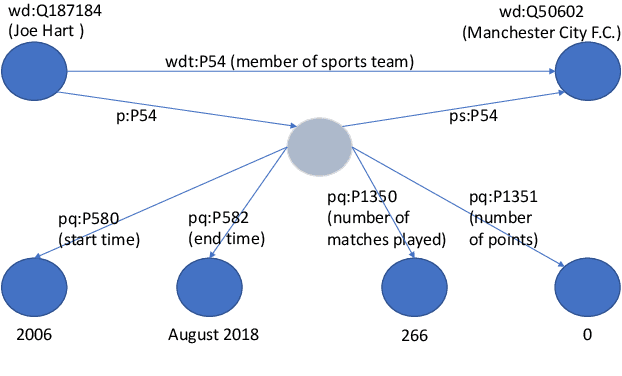


Knowledge Base Question Answering (KBQA) tasks that involve complex reasoning are emerging as an important research direction. However, most existing KBQA datasets focus primarily on generic multi-hop reasoning over explicit facts, largely ignoring other reasoning types such as temporal, spatial, and taxonomic reasoning. In this paper, we present a benchmark dataset for temporal reasoning, TempQA-WD, to encourage research in extending the present approaches to target a more challenging set of complex reasoning tasks. Specifically, our benchmark is a temporal question answering dataset with the following advantages: (a) it is based on Wikidata, which is the most frequently curated, openly available knowledge base, (b) it includes intermediate sparql queries to facilitate the evaluation of semantic parsing based approaches for KBQA, and (c) it generalizes to multiple knowledge bases: Freebase and Wikidata. The TempQA-WD dataset is available at https://github.com/IBM/tempqa-wd.
SYGMA: System for Generalizable Modular Question Answering OverKnowledge Bases
Sep 28, 2021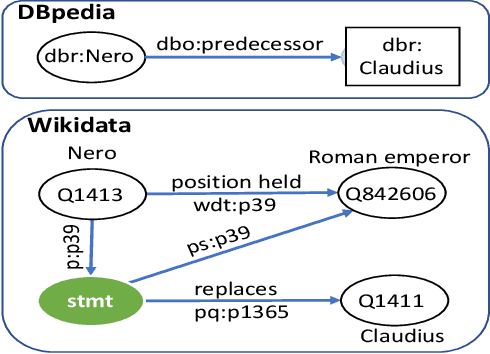


Knowledge Base Question Answering (KBQA) tasks that in-volve complex reasoning are emerging as an important re-search direction. However, most KBQA systems struggle withgeneralizability, particularly on two dimensions: (a) acrossmultiple reasoning types where both datasets and systems haveprimarily focused on multi-hop reasoning, and (b) across mul-tiple knowledge bases, where KBQA approaches are specif-ically tuned to a single knowledge base. In this paper, wepresent SYGMA, a modular approach facilitating general-izability across multiple knowledge bases and multiple rea-soning types. Specifically, SYGMA contains three high levelmodules: 1) KB-agnostic question understanding module thatis common across KBs 2) Rules to support additional reason-ing types and 3) KB-specific question mapping and answeringmodule to address the KB-specific aspects of the answer ex-traction. We demonstrate effectiveness of our system by evalu-ating on datasets belonging to two distinct knowledge bases,DBpedia and Wikidata. In addition, to demonstrate extensi-bility to additional reasoning types we evaluate on multi-hopreasoning datasets and a new Temporal KBQA benchmarkdataset on Wikidata, namedTempQA-WD1, introduced in thispaper. We show that our generalizable approach has bettercompetetive performance on multiple datasets on DBpediaand Wikidata that requires both multi-hop and temporal rea-soning
Question Answering over Knowledge Bases by Leveraging Semantic Parsing and Neuro-Symbolic Reasoning
Dec 03, 2020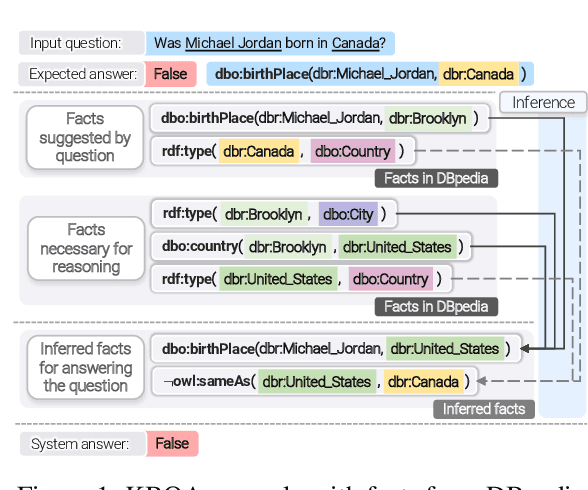
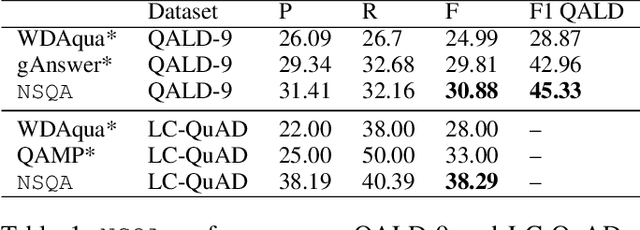
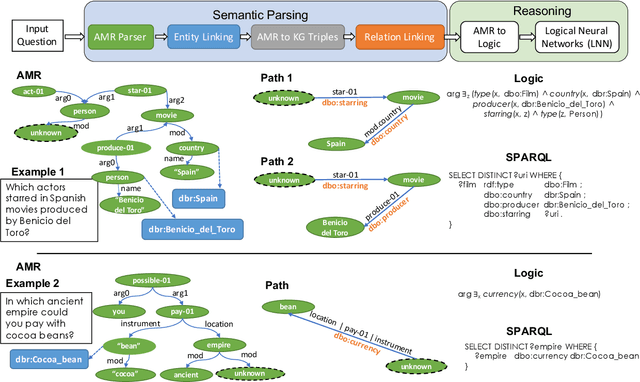

Knowledge base question answering (KBQA) is an important task in Natural Language Processing. Existing approaches face significant challenges including complex question understanding, necessity for reasoning, and lack of large training datasets. In this work, we propose a semantic parsing and reasoning-based Neuro-Symbolic Question Answering(NSQA) system, that leverages (1) Abstract Meaning Representation (AMR) parses for task-independent question under-standing; (2) a novel path-based approach to transform AMR parses into candidate logical queries that are aligned to the KB; (3) a neuro-symbolic reasoner called Logical Neural Net-work (LNN) that executes logical queries and reasons over KB facts to provide an answer; (4) system of systems approach,which integrates multiple, reusable modules that are trained specifically for their individual tasks (e.g. semantic parsing,entity linking, and relationship linking) and do not require end-to-end training data. NSQA achieves state-of-the-art performance on QALD-9 and LC-QuAD 1.0. NSQA's novelty lies in its modular neuro-symbolic architecture and its task-general approach to interpreting natural language questions.
Infusing Knowledge into the Textual Entailment Task Using Graph Convolutional Networks
Nov 22, 2019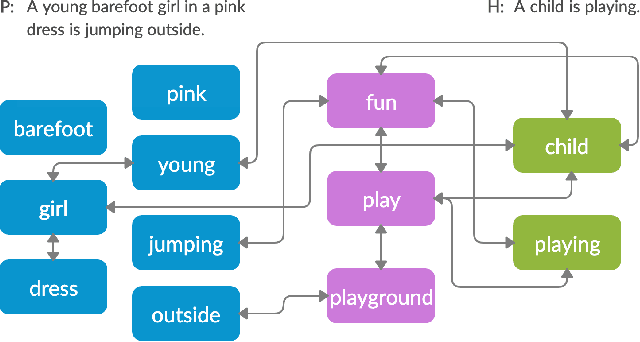

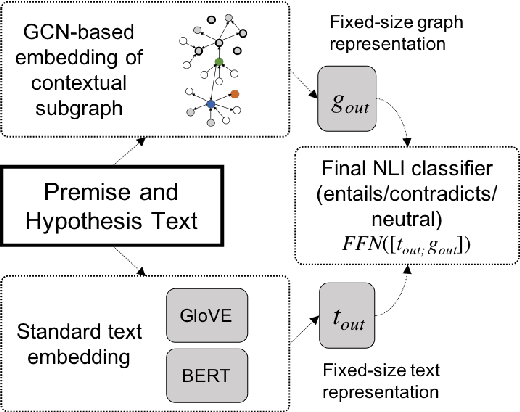
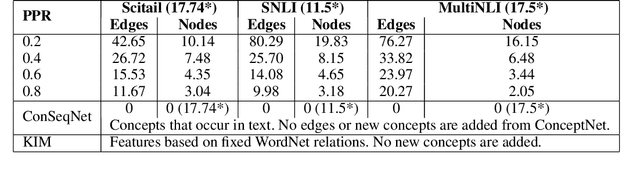
Textual entailment is a fundamental task in natural language processing. Most approaches for solving the problem use only the textual content present in training data. A few approaches have shown that information from external knowledge sources like knowledge graphs (KGs) can add value, in addition to the textual content, by providing background knowledge that may be critical for a task. However, the proposed models do not fully exploit the information in the usually large and noisy KGs, and it is not clear how it can be effectively encoded to be useful for entailment. We present an approach that complements text-based entailment models with information from KGs by (1) using Personalized PageR- ank to generate contextual subgraphs with reduced noise and (2) encoding these subgraphs using graph convolutional networks to capture KG structure. Our technique extends the capability of text models exploiting structural and semantic information found in KGs. We evaluate our approach on multiple textual entailment datasets and show that the use of external knowledge helps improve prediction accuracy. This is particularly evident in the challenging BreakingNLI dataset, where we see an absolute improvement of 5-20% over multiple text-based entailment models.