 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Learning of Latent Language Structure With Logical Offline Cycle Consistency
May 31, 2023



We introduce Logical Offline Cycle Consistency Optimization (LOCCO), a scalable, semi-supervised method for training a neural semantic parser. Conceptually, LOCCO can be viewed as a form of self-learning where the semantic parser being trained is used to generate annotations for unlabeled text that are then used as new supervision. To increase the quality of annotations, our method utilizes a count-based prior over valid formal meaning representations and a cycle-consistency score produced by a neural text generation model as additional signals. Both the prior and semantic parser are updated in an alternate fashion from full passes over the training data, which can be seen as approximating the marginalization of latent structures through stochastic variational inference. The use of a count-based prior, frozen text generation model, and offline annotation process yields an approach with negligible complexity and latency increases as compared to conventional self-learning. As an added bonus, the annotations produced by LOCCO can be trivially repurposed to train a neural text generation model. We demonstrate the utility of LOCCO on the well-known WebNLG benchmark where we obtain an improvement of 2 points against a self-learning parser under equivalent conditions, an improvement of 1.3 points against the previous state-of-the-art parser, and competitive text generation performance in terms of BLEU score.
Laziness Is a Virtue When It Comes to Compositionality in Neural Semantic Parsing
May 07, 2023
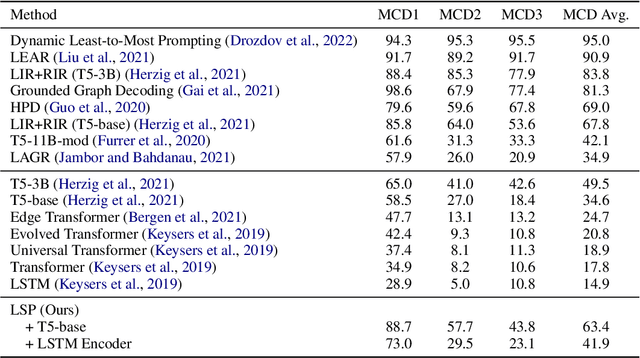


Nearly all general-purpose neural semantic parsers generate logical forms in a strictly top-down autoregressive fashion. Though such systems have achieved impressive results across a variety of datasets and domains, recent works have called into question whether they are ultimately limited in their ability to compositionally generalize. In this work, we approach semantic parsing from, quite literally, the opposite direction; that is, we introduce a neural semantic parsing generation method that constructs logical forms from the bottom up, beginning from the logical form's leaves. The system we introduce is lazy in that it incrementally builds up a set of potential semantic parses, but only expands and processes the most promising candidate parses at each generation step. Such a parsimonious expansion scheme allows the system to maintain an arbitrarily large set of parse hypotheses that are never realized and thus incur minimal computational overhead. We evaluate our approach on compositional generalization; specifically, on the challenging CFQ dataset and three Text-to-SQL datasets where we show that our novel, bottom-up semantic parsing technique outperforms general-purpose semantic parsers while also being competitive with comparable neural parsers that have been designed for each task.
Question Answering over Knowledge Bases by Leveraging Semantic Parsing and Neuro-Symbolic Reasoning
Dec 03, 2020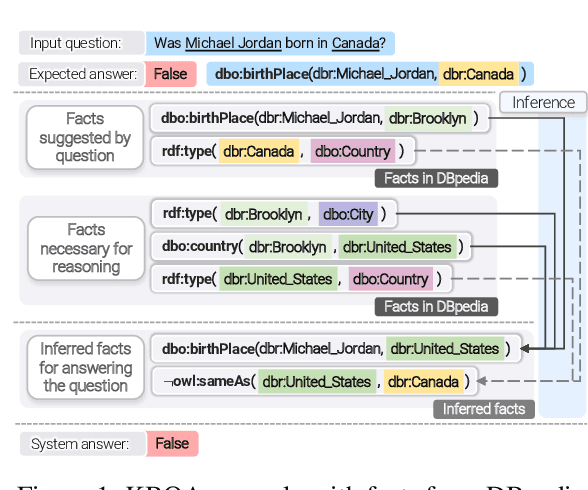
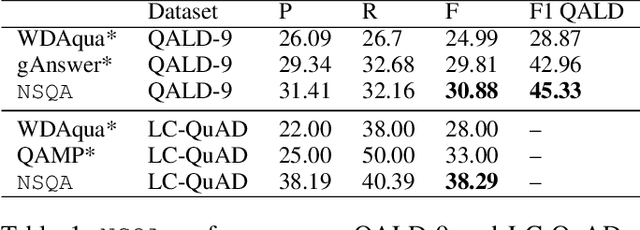
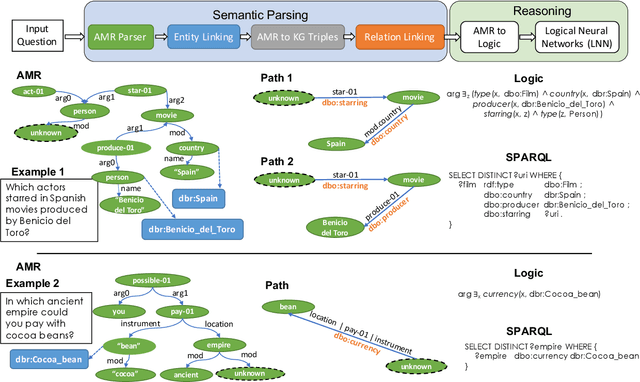

Knowledge base question answering (KBQA) is an important task in Natural Language Processing. Existing approaches face significant challenges including complex question understanding, necessity for reasoning, and lack of large training datasets. In this work, we propose a semantic parsing and reasoning-based Neuro-Symbolic Question Answering(NSQA) system, that leverages (1) Abstract Meaning Representation (AMR) parses for task-independent question under-standing; (2) a novel path-based approach to transform AMR parses into candidate logical queries that are aligned to the KB; (3) a neuro-symbolic reasoner called Logical Neural Net-work (LNN) that executes logical queries and reasons over KB facts to provide an answer; (4) system of systems approach,which integrates multiple, reusable modules that are trained specifically for their individual tasks (e.g. semantic parsing,entity linking, and relationship linking) and do not require end-to-end training data. NSQA achieves state-of-the-art performance on QALD-9 and LC-QuAD 1.0. NSQA's novelty lies in its modular neuro-symbolic architecture and its task-general approach to interpreting natural language questions.
Self-supervised Sequence-to-sequence ASR using Unpaired Speech and Text
Apr 30, 2019

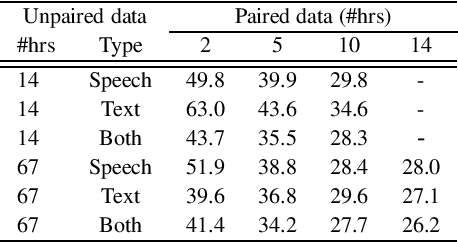
Sequence-to-sequence ASR models require large quantities of data to attain high performance. For this reason, there has been a recent surge in interest for self-supervised and supervised training in such models. This work builds upon recent results showing notable improvements in self-supervised training using cycle-consistency and related techniques. Such techniques derive training procedures and losses able to leverage unpaired speech and/or text data by combining ASR with text-to-speech (TTS) models. In particular, this work proposes a new self-supervised loss combining an end-to-end differentiable ASR$\rightarrow$TTS loss with a point estimate TTS$\rightarrow$ASR loss. The method is able to leverage both unpaired speech and text data to outperform recently proposed related techniques in terms of \%WER. We provide extensive results analyzing the impact of data quantity and speech and text modalities and show consistent gains across WSJ and Librispeech corpora. Our code is provided to reproduce the experiments.
Cycle-consistency training for end-to-end speech recognition
Nov 02, 2018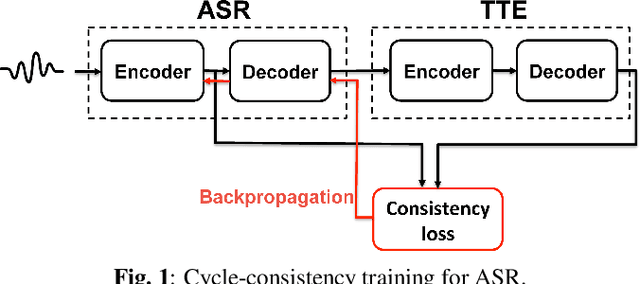
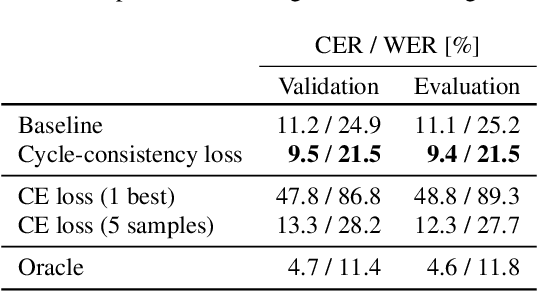

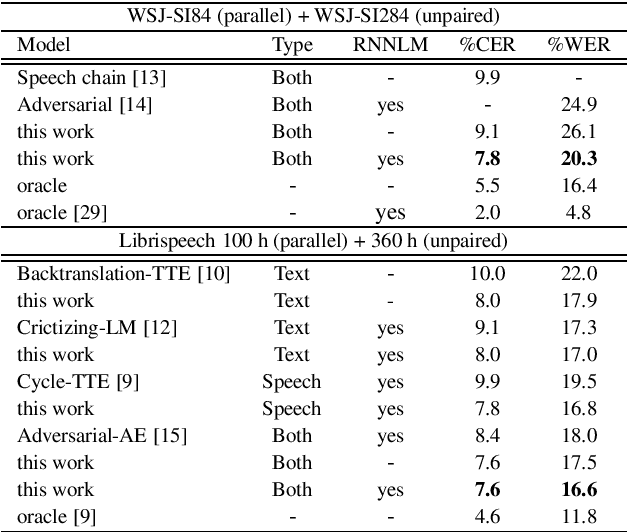
This paper presents a method to train end-to-end automatic speech recognition (ASR) models using unpaired data. Although the end-to-end approach can eliminate the need for expert knowledge such as pronunciation dictionaries to build ASR systems, it still requires a large amount of paired data, i.e., speech utterances and their transcriptions. Cycle-consistency losses have been recently proposed as a way to mitigate the problem of limited paired data. These approaches compose a reverse operation with a given transformation, e.g., text-to-speech (TTS) with ASR, to build a loss that only requires unsupervised data, speech in this example. Applying cycle consistency to ASR models is not trivial since fundamental information, such as speaker traits, are lost in the intermediate text bottleneck. To solve this problem, this work presents a loss that is based on the speech encoder state sequence instead of the raw speech signal. This is achieved by training a Text-To-Encoder model and defining a loss based on the encoder reconstruction error. Experimental results on the LibriSpeech corpus show that the proposed cycle-consistency training reduced the word error rate by 14.7% from an initial model trained with 100-hour paired data, using an additional 360 hours of audio data without transcriptions. We also investigate the use of text-only data mainly for language modeling to further improve the performance in the unpaired data training scenario.
Back-Translation-Style Data Augmentation for End-to-End ASR
Jul 28, 2018
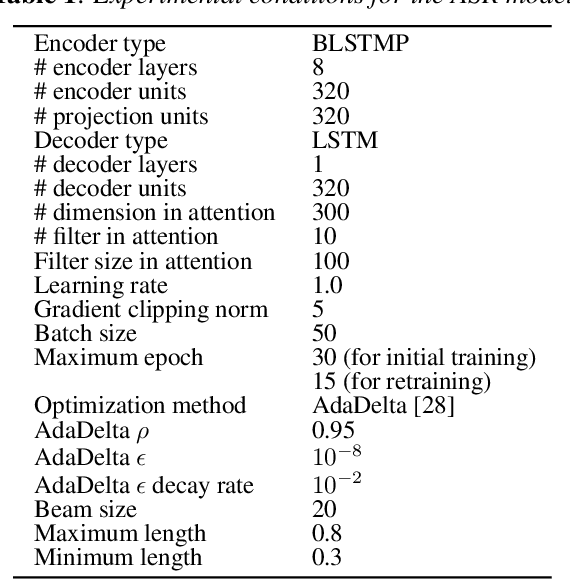


In this paper we propose a novel data augmentation method for attention-based end-to-end automatic speech recognition (E2E-ASR), utilizing a large amount of text which is not paired with speech signals. Inspired by the back-translation technique proposed in the field of machine translation, we build a neural text-to-encoder model which predicts a sequence of hidden states extracted by a pre-trained E2E-ASR encoder from a sequence of characters. By using hidden states as a target instead of acoustic features, it is possible to achieve faster attention learning and reduce computational cost, thanks to sub-sampling in E2E-ASR encoder, also the use of the hidden states can avoid to model speaker dependencies unlike acoustic features. After training, the text-to-encoder model generates the hidden states from a large amount of unpaired text, then E2E-ASR decoder is retrained using the generated hidden states as additional training data. Experimental evaluation using LibriSpeech dataset demonstrates that our proposed method achieves improvement of ASR performance and reduces the number of unknown words without the need for paired data.