 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Guide a Saturation-Based Theorem Prover
Jun 07, 2021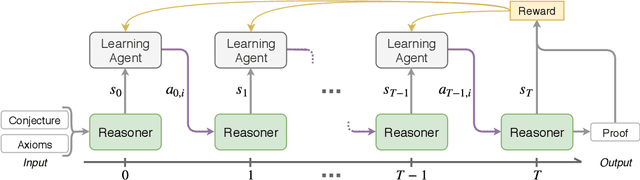
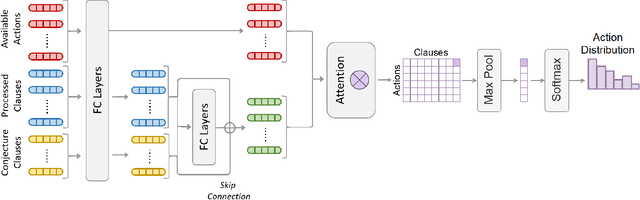
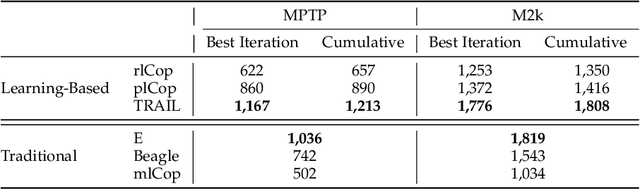
Traditional automated theorem provers have relied on manually tuned heuristics to guide how they perform proof search. Recently, however, there has been a surge of interest in the design of learning mechanisms that can be integrated into theorem provers to improve their performance automatically. In this work, we introduce TRAIL, a deep learning-based approach to theorem proving that characterizes core elements of saturation-based theorem proving within a neural framework. TRAIL leverages (a) an effective graph neural network for representing logical formulas, (b) a novel neural representation of the state of a saturation-based theorem prover in terms of processed clauses and available actions, and (c) a novel representation of the inference selection process as an attention-based action policy. We show through a systematic analysis that these components allow TRAIL to significantly outperform previous reinforcement learning-based theorem provers on two standard benchmark datasets (up to 36% more theorems proved). In addition, to the best of our knowledge, TRAIL is the first reinforcement learning-based approach to exceed the performance of a state-of-the-art traditional theorem prover on a standard theorem proving benchmark (solving up to 17% more problems).
Explainable Deep RDFS Reasoner
Feb 10, 2020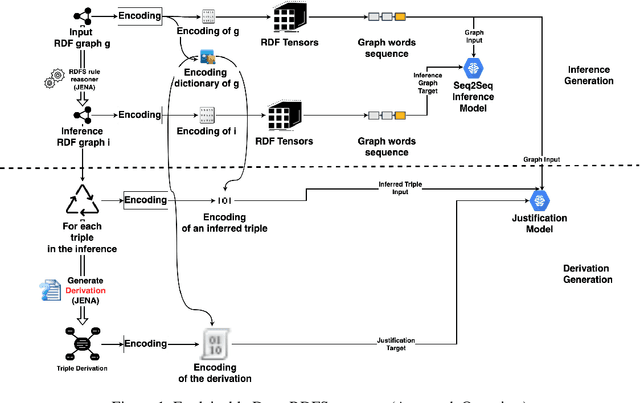
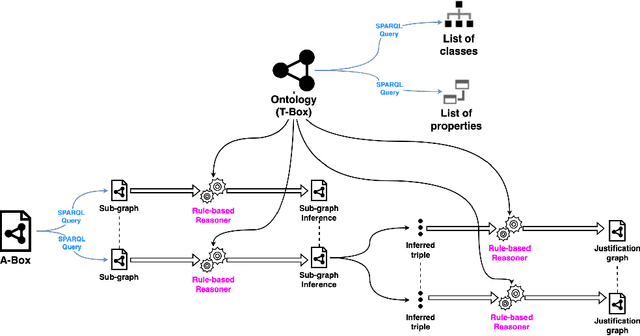

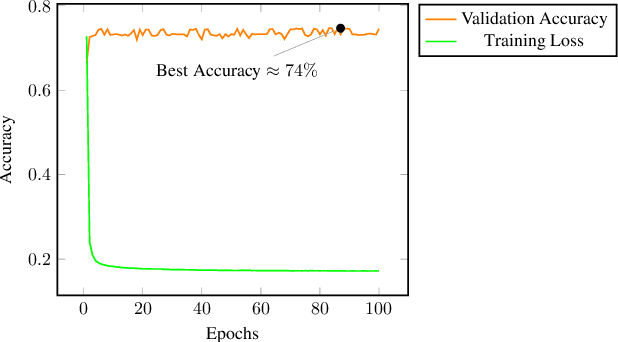
Recent research efforts aiming to bridge the Neural-Symbolic gap for RDFS reasoning proved empirically that deep learning techniques can be used to learn RDFS inference rules. However, one of their main deficiencies compared to rule-based reasoners is the lack of derivations for the inferred triples (i.e. explainability in AI terms). In this paper, we build on these approaches to provide not only the inferred graph but also explain how these triples were inferred. In the graph words approach, RDF graphs are represented as a sequence of graph words where inference can be achieved through neural machine translation. To achieve explainability in RDFS reasoning, we revisit this approach and introduce a new neural network model that gets the input graph--as a sequence of graph words-- as well as the encoding of the inferred triple and outputs the derivation for the inferred triple. We evaluated our justification model on two datasets: a synthetic dataset-- LUBM benchmark-- and a real-world dataset --ScholarlyData about conferences-- where the lowest validation accuracy approached 96%.
Infusing Knowledge into the Textual Entailment Task Using Graph Convolutional Networks
Nov 22, 2019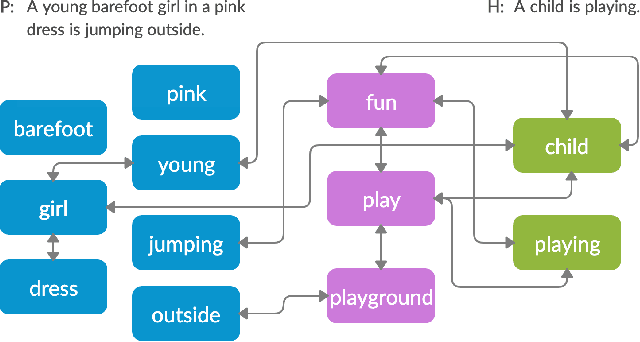

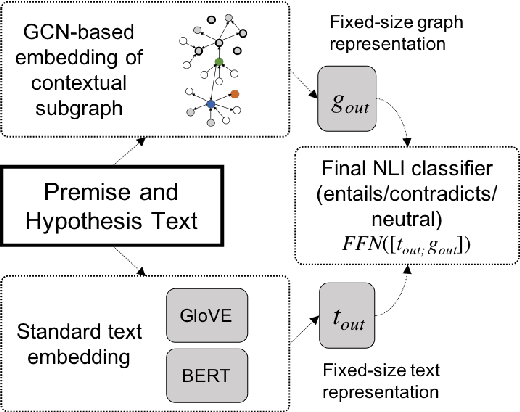
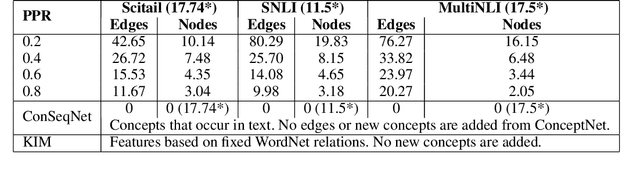
Textual entailment is a fundamental task in natural language processing. Most approaches for solving the problem use only the textual content present in training data. A few approaches have shown that information from external knowledge sources like knowledge graphs (KGs) can add value, in addition to the textual content, by providing background knowledge that may be critical for a task. However, the proposed models do not fully exploit the information in the usually large and noisy KGs, and it is not clear how it can be effectively encoded to be useful for entailment. We present an approach that complements text-based entailment models with information from KGs by (1) using Personalized PageR- ank to generate contextual subgraphs with reduced noise and (2) encoding these subgraphs using graph convolutional networks to capture KG structure. Our technique extends the capability of text models exploiting structural and semantic information found in KGs. We evaluate our approach on multiple textual entailment datasets and show that the use of external knowledge helps improve prediction accuracy. This is particularly evident in the challenging BreakingNLI dataset, where we see an absolute improvement of 5-20% over multiple text-based entailment models.
A Deep Reinforcement Learning based Approach to Learning Transferable Proof Guidance Strategies
Nov 05, 2019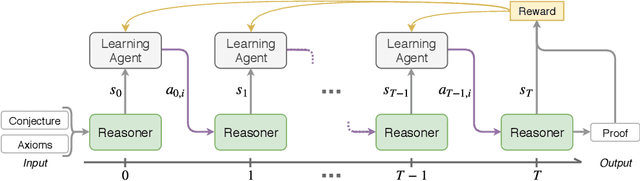
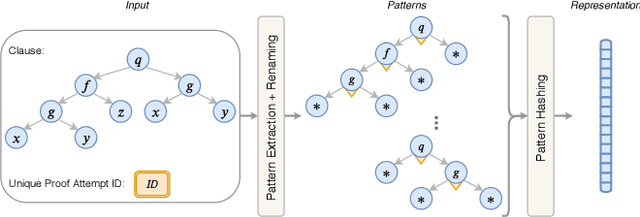

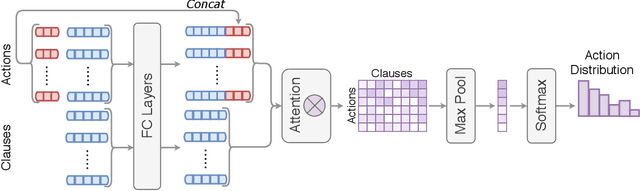
Traditional first-order logic (FOL) reasoning systems usually rely on manual heuristics for proof guidance. We propose TRAIL: a system that learns to perform proof guidance using reinforcement learning. A key design principle of our system is that it is general enough to allow transfer to problems in different domains that do not share the same vocabulary of the training set. To do so, we developed a novel representation of the internal state of a prover in terms of clauses and inference actions, and a novel neural-based attention mechanism to learn interactions between clauses. We demonstrate that this approach enables the system to generalize from training to test data across domains with different vocabularies, suggesting that the neural architecture in TRAIL is well suited for representing and processing of logical formalisms.
Answering Science Exam Questions Using Query Rewriting with Background Knowledge
Sep 15, 2018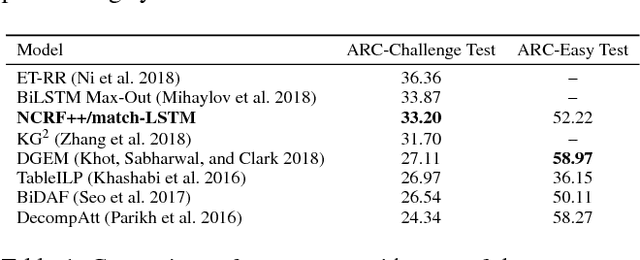
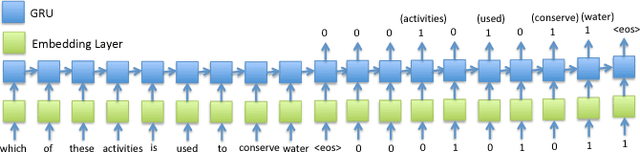
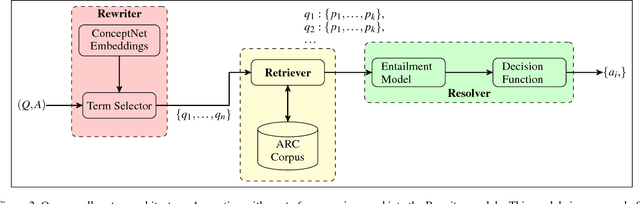
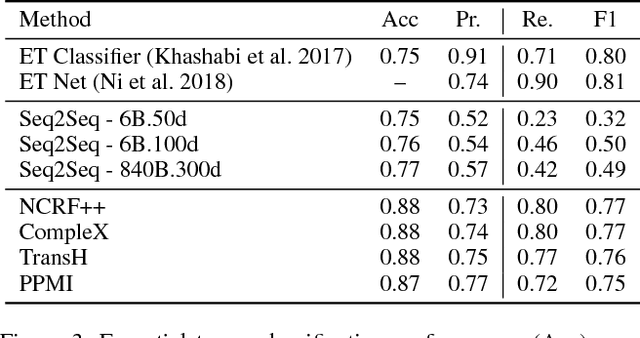
Open-domain question answering (QA) is an important problem in AI and NLP that is emerging as a bellwether for progress on the generalizability of AI methods and techniques. Much of the progress in open-domain QA systems has been realized through advances in information retrieval methods and corpus construction. In this paper, we focus on the recently introduced ARC Challenge dataset, which contains 2,590 multiple choice questions authored for grade-school science exams. These questions are selected to be the most challenging for current QA systems, and current state of the art performance is only slightly better than random chance. We present a system that rewrites a given question into queries that are used to retrieve supporting text from a large corpus of science-related text. Our rewriter is able to incorporate background knowledge from ConceptNet and -- in tandem with a generic textual entailment system trained on SciTail that identifies support in the retrieved results -- outperforms several strong baselines on the end-to-end QA task despite only being trained to identify essential terms in the original source question. We use a generalizable decision methodology over the retrieved evidence and answer candidates to select the best answer. By combining query rewriting, background knowledge, and textual entailment our system is able to outperform several strong baselines on the ARC dataset.
Improving Natural Language Inference Using External Knowledge in the Science Questions Domain
Sep 15, 2018
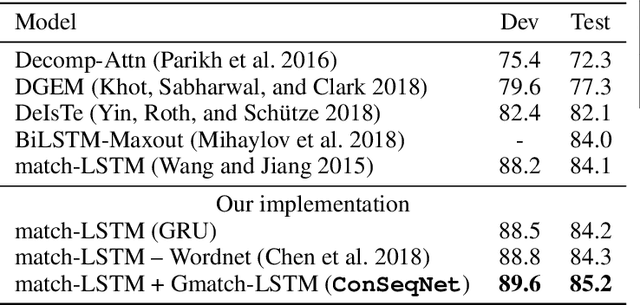
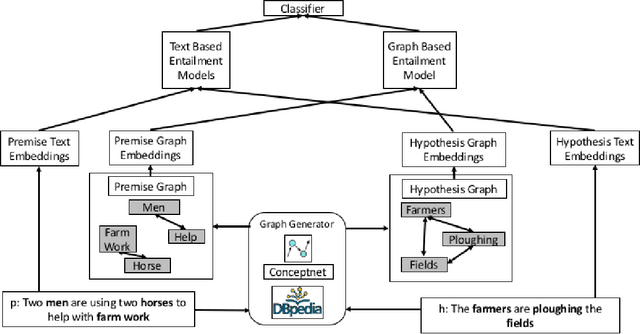
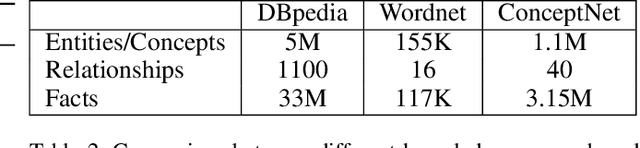
Natural Language Inference (NLI) is fundamental to many Natural Language Processing (NLP) applications including semantic search and question answering. The NLI problem has gained significant attention thanks to the release of large scale, challenging datasets. Present approaches to the problem largely focus on learning-based methods that use only textual information in order to classify whether a given premise entails, contradicts, or is neutral with respect to a given hypothesis. Surprisingly, the use of methods based on structured knowledge -- a central topic in artificial intelligence -- has not received much attention vis-a-vis the NLI problem. While there are many open knowledge bases that contain various types of reasoning information, their use for NLI has not been well explored. To address this, we present a combination of techniques that harness knowledge graphs to improve performance on the NLI problem in the science questions domain. We present the results of applying our techniques on text, graph, and text-to-graph based models, and discuss implications for the use of external knowledge in solving the NLI problem. Our model achieves the new state-of-the-art performance on the NLI problem over the SciTail science questions dataset.