 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSchemaless Queries over Document Tables with Dependencies
Nov 21, 2019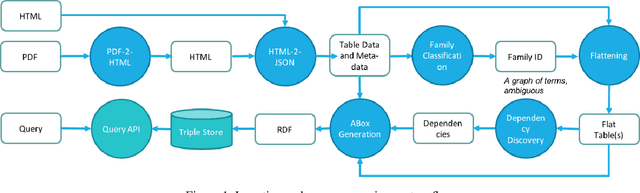
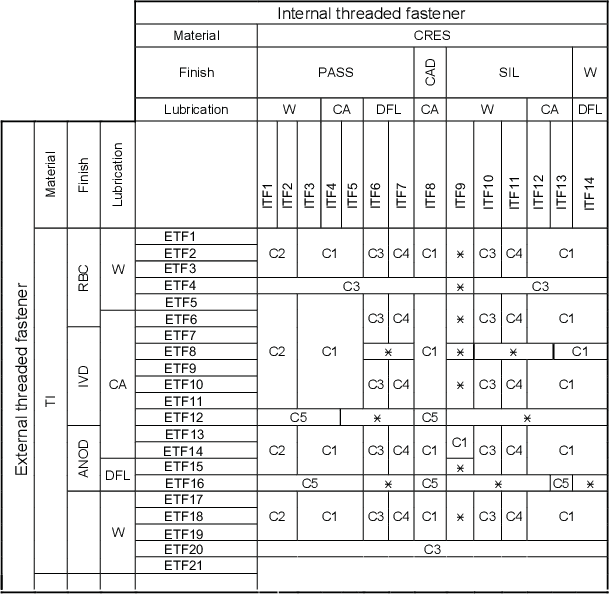
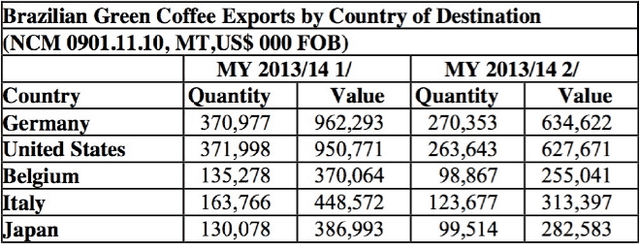
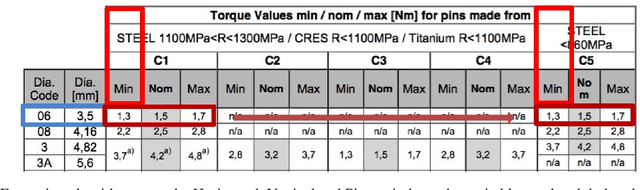
Unstructured enterprise data such as reports, manuals and guidelines often contain tables. The traditional way of integrating data from these tables is through a two-step process of table detection/extraction and mapping the table layouts to an appropriate schema. This can be an expensive process. In this paper we show that by using semantic technologies (RDF/SPARQL and database dependencies) paired with a simple but powerful way to transform tables with non-relational layouts, it is possible to offer query answering services over these tables with minimal manual work or domain-specific mappings. Our method enables users to exploit data in tables embedded in documents with little effort, not only for simple retrieval queries, but also for structured queries that require joining multiple interrelated tables.
High-Fidelity Vector Space Models of Structured Data
Jan 15, 2019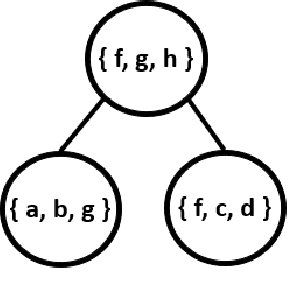

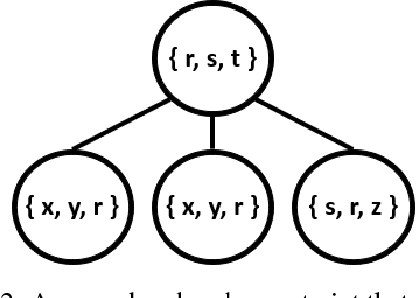
Machine learning systems regularly deal with structured data in real-world applications. Unfortunately, such data has been difficult to faithfully represent in a way that most machine learning techniques would expect, i.e. as a real-valued vector of a fixed, pre-specified size. In this work, we introduce a novel approach that compiles structured data into a satisfiability problem which has in its set of solutions at least (and often only) the input data. The satisfiability problem is constructed from constraints which are generated automatically a priori from a given signature, thus trivially allowing for a bag-of-words-esque vector representation of the input to be constructed. The method is demonstrated in two areas, automated reasoning and natural language processing, where it is shown to produce vector representations of natural-language sentences and first-order logic clauses that can be precisely translated back to their original, structured input forms.
Answering Science Exam Questions Using Query Rewriting with Background Knowledge
Sep 15, 2018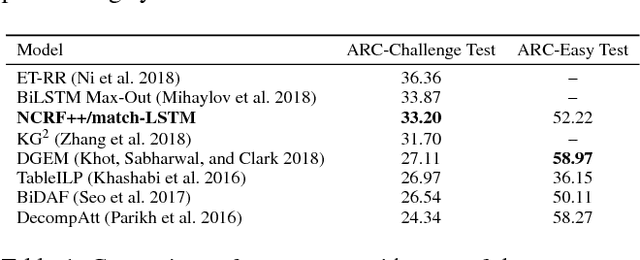
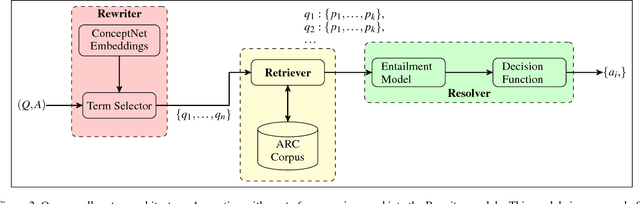
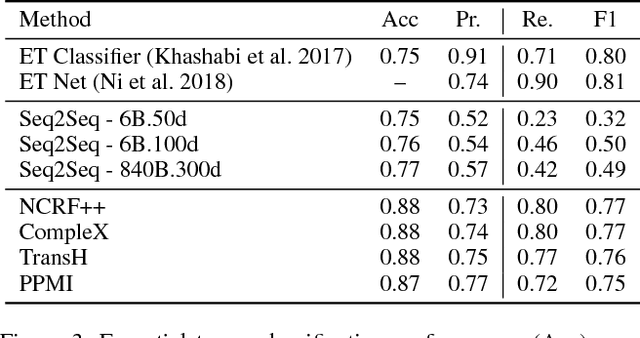
Open-domain question answering (QA) is an important problem in AI and NLP that is emerging as a bellwether for progress on the generalizability of AI methods and techniques. Much of the progress in open-domain QA systems has been realized through advances in information retrieval methods and corpus construction. In this paper, we focus on the recently introduced ARC Challenge dataset, which contains 2,590 multiple choice questions authored for grade-school science exams. These questions are selected to be the most challenging for current QA systems, and current state of the art performance is only slightly better than random chance. We present a system that rewrites a given question into queries that are used to retrieve supporting text from a large corpus of science-related text. Our rewriter is able to incorporate background knowledge from ConceptNet and -- in tandem with a generic textual entailment system trained on SciTail that identifies support in the retrieved results -- outperforms several strong baselines on the end-to-end QA task despite only being trained to identify essential terms in the original source question. We use a generalizable decision methodology over the retrieved evidence and answer candidates to select the best answer. By combining query rewriting, background knowledge, and textual entailment our system is able to outperform several strong baselines on the ARC dataset.
Improving Natural Language Inference Using External Knowledge in the Science Questions Domain
Sep 15, 2018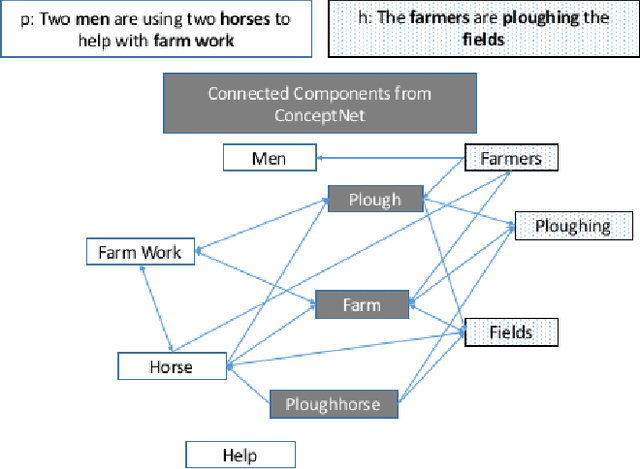
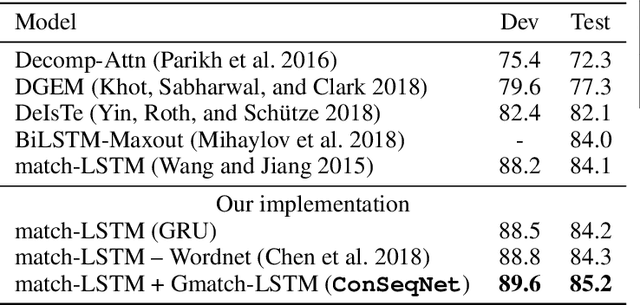
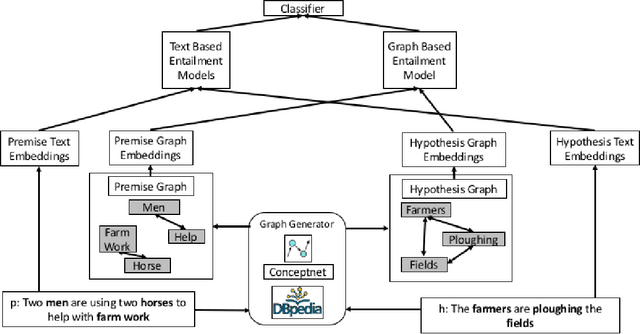
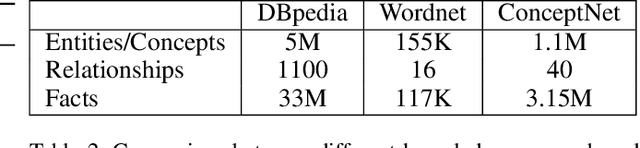
Natural Language Inference (NLI) is fundamental to many Natural Language Processing (NLP) applications including semantic search and question answering. The NLI problem has gained significant attention thanks to the release of large scale, challenging datasets. Present approaches to the problem largely focus on learning-based methods that use only textual information in order to classify whether a given premise entails, contradicts, or is neutral with respect to a given hypothesis. Surprisingly, the use of methods based on structured knowledge -- a central topic in artificial intelligence -- has not received much attention vis-a-vis the NLI problem. While there are many open knowledge bases that contain various types of reasoning information, their use for NLI has not been well explored. To address this, we present a combination of techniques that harness knowledge graphs to improve performance on the NLI problem in the science questions domain. We present the results of applying our techniques on text, graph, and text-to-graph based models, and discuss implications for the use of external knowledge in solving the NLI problem. Our model achieves the new state-of-the-art performance on the NLI problem over the SciTail science questions dataset.
A Systematic Classification of Knowledge, Reasoning, and Context within the ARC Dataset
Jun 01, 2018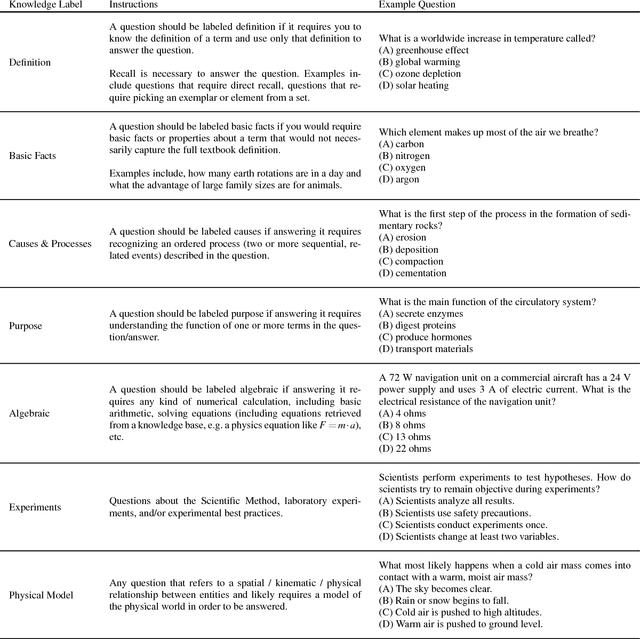
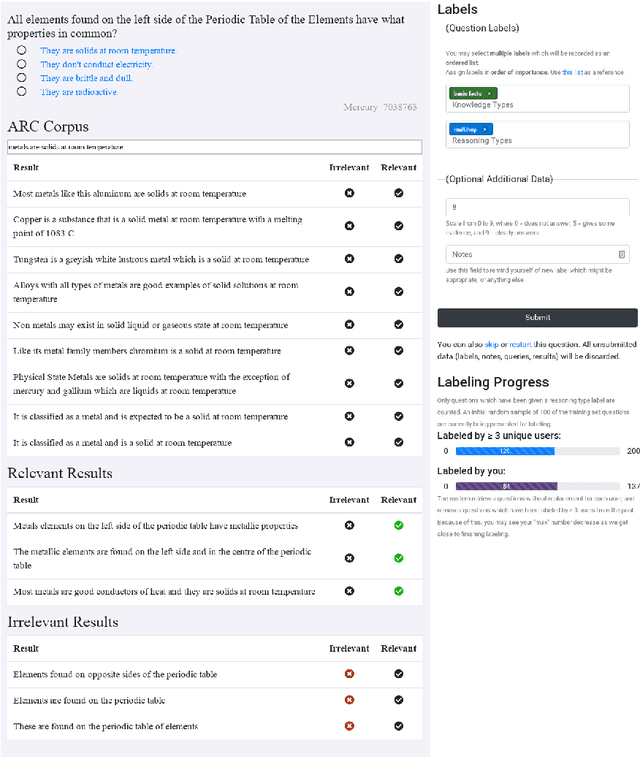
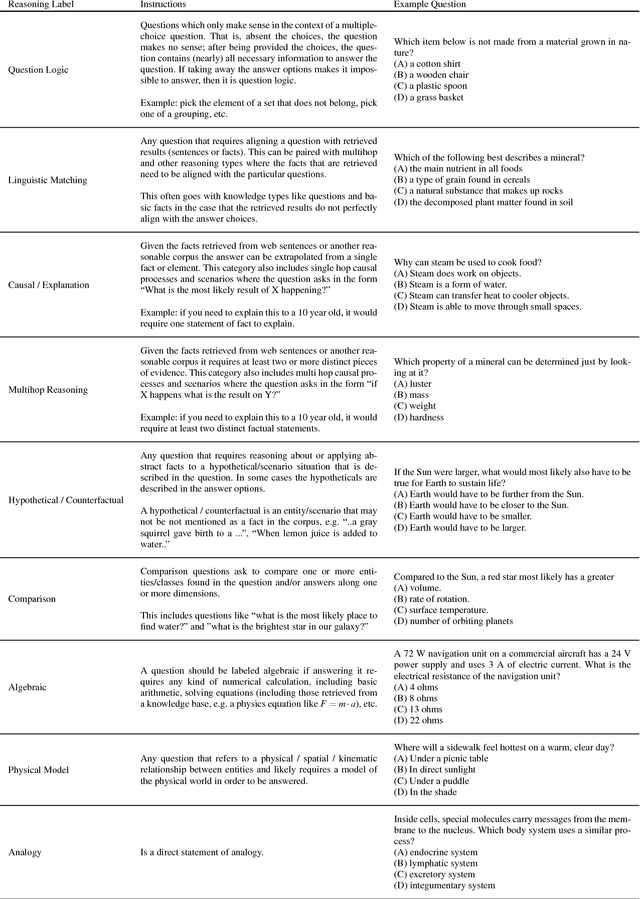
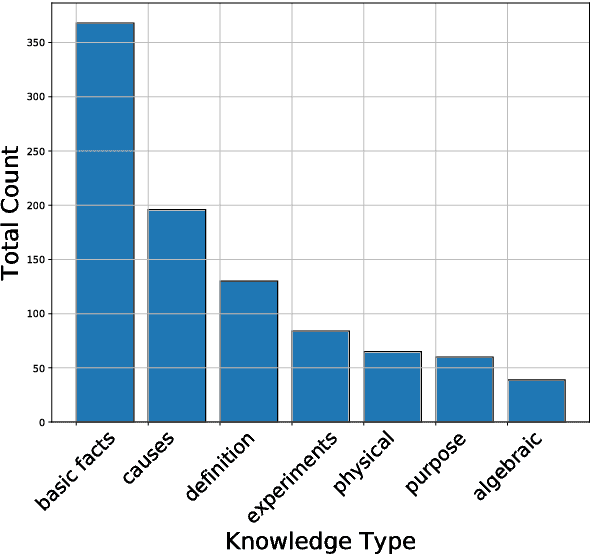
The recent work of Clark et al. introduces the AI2 Reasoning Challenge (ARC) and the associated ARC dataset that partitions open domain, complex science questions into an Easy Set and a Challenge Set. That paper includes an analysis of 100 questions with respect to the types of knowledge and reasoning required to answer them; however, it does not include clear definitions of these types, nor does it offer information about the quality of the labels. We propose a comprehensive set of definitions of knowledge and reasoning types necessary for answering the questions in the ARC dataset. Using ten annotators and a sophisticated annotation interface, we analyze the distribution of labels across the Challenge Set and statistics related to them. Additionally, we demonstrate that although naive information retrieval methods return sentences that are irrelevant to answering the query, sufficient supporting text is often present in the (ARC) corpus. Evaluating with human-selected relevant sentences improves the performance of a neural machine comprehension model by 42 points.