 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajAD: Trajectory Anomaly Detection for Trustworthy LLM Agents
Feb 06, 2026We address the problem of runtime trajectory anomaly detection, a critical capability for enabling trustworthy LLM agents. Current safety measures predominantly focus on static input/output filtering. However, we argue that ensuring LLM agents reliability requires auditing the intermediate execution process. In this work, we formulate the task of Trajectory Anomaly Detection. The goal is not merely detection, but precise error localization. This capability is essential for enabling efficient rollback-and-retry. To achieve this, we construct TrajBench, a dataset synthesized via a perturb-and-complete strategy to cover diverse procedural anomalies. Using this benchmark, we investigate the capability of models in process supervision. We observe that general-purpose LLMs, even with zero-shot prompting, struggle to identify and localize these anomalies. This reveals that generalized capabilities do not automatically translate to process reliability. To address this, we propose TrajAD, a specialized verifier trained with fine-grained process supervision. Our approach outperforms baselines, demonstrating that specialized supervision is essential for building trustworthy agents.
Spatial 3D-LLM: Exploring Spatial Awareness in 3D Vision-Language Models
Jul 22, 2025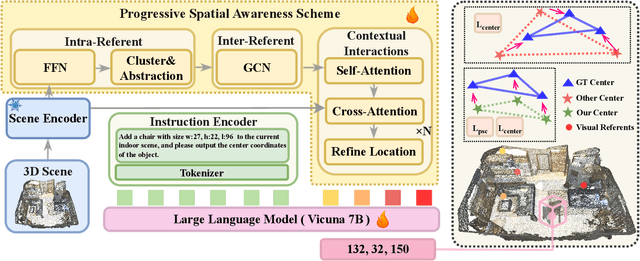

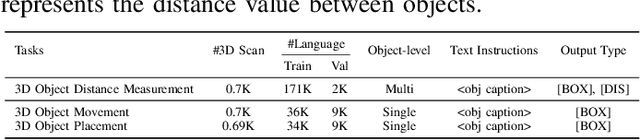
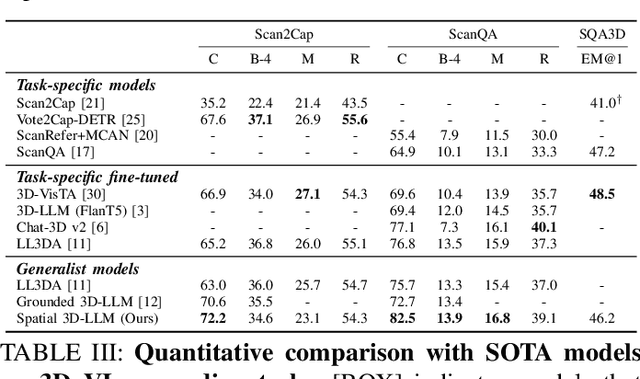
New era has unlocked exciting possibilities for extending Large Language Models (LLMs) to tackle 3D vision-language tasks. However, most existing 3D multimodal LLMs (MLLMs) rely on compressing holistic 3D scene information or segmenting independent objects to perform these tasks, which limits their spatial awareness due to insufficient representation of the richness inherent in 3D scenes. To overcome these limitations, we propose Spatial 3D-LLM, a 3D MLLM specifically designed to enhance spatial awareness for 3D vision-language tasks by enriching the spatial embeddings of 3D scenes. Spatial 3D-LLM integrates an LLM backbone with a progressive spatial awareness scheme that progressively captures spatial information as the perception field expands, generating location-enriched 3D scene embeddings to serve as visual prompts. Furthermore, we introduce two novel tasks: 3D object distance measurement and 3D layout editing, and construct a 3D instruction dataset, MODEL, to evaluate the model's spatial awareness capabilities. Experimental results demonstrate that Spatial 3D-LLM achieves state-of-the-art performance across a wide range of 3D vision-language tasks, revealing the improvements stemmed from our progressive spatial awareness scheme of mining more profound spatial information. Our code is available at https://github.com/bjshuyuan/Spatial-3D-LLM.
Generative AI in Health Economics and Outcomes Research: A Taxonomy of Key Definitions and Emerging Applications, an ISPOR Working Group Report
Oct 26, 2024


Objective: This article offers a taxonomy of generative artificial intelligence (AI) for health economics and outcomes research (HEOR), explores its emerging applications, and outlines methods to enhance the accuracy and reliability of AI-generated outputs. Methods: The review defines foundational generative AI concepts and highlights current HEOR applications, including systematic literature reviews, health economic modeling, real-world evidence generation, and dossier development. Approaches such as prompt engineering (zero-shot, few-shot, chain-of-thought, persona pattern prompting), retrieval-augmented generation, model fine-tuning, and the use of domain-specific models are introduced to improve AI accuracy and reliability. Results: Generative AI shows significant potential in HEOR, enhancing efficiency, productivity, and offering novel solutions to complex challenges. Foundation models are promising in automating complex tasks, though challenges remain in scientific reliability, bias, interpretability, and workflow integration. The article discusses strategies to improve the accuracy of these AI tools. Conclusion: Generative AI could transform HEOR by increasing efficiency and accuracy across various applications. However, its full potential can only be realized by building HEOR expertise and addressing the limitations of current AI technologies. As AI evolves, ongoing research and innovation will shape its future role in the field.
Llettuce: An Open Source Natural Language Processing Tool for the Translation of Medical Terms into Uniform Clinical Encoding
Oct 04, 2024



This paper introduces Llettuce, an open-source tool designed to address the complexities of converting medical terms into OMOP standard concepts. Unlike existing solutions such as the Athena database search and Usagi, which struggle with semantic nuances and require substantial manual input, Llettuce leverages advanced natural language processing, including large language models and fuzzy matching, to automate and enhance the mapping process. Developed with a focus on GDPR compliance, Llettuce can be deployed locally, ensuring data protection while maintaining high performance in converting informal medical terms to standardised concepts.
Probabilistic Programming with Programmable Variational Inference
Jun 22, 2024
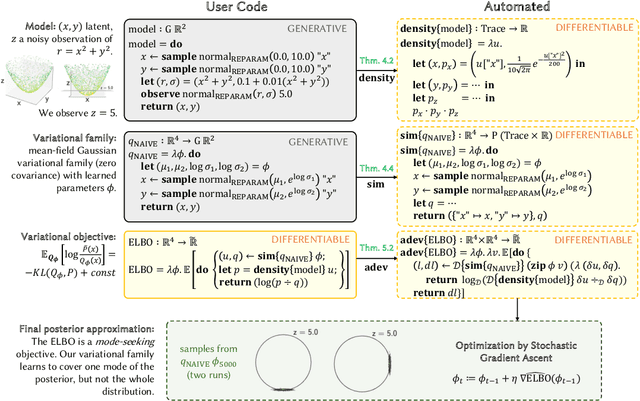

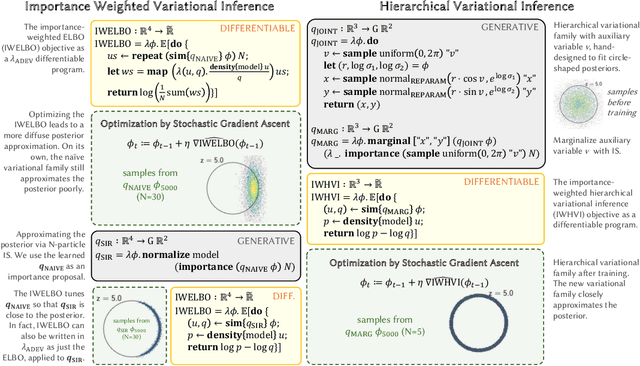
Compared to the wide array of advanced Monte Carlo methods supported by modern probabilistic programming languages (PPLs), PPL support for variational inference (VI) is less developed: users are typically limited to a predefined selection of variational objectives and gradient estimators, which are implemented monolithically (and without formal correctness arguments) in PPL backends. In this paper, we propose a more modular approach to supporting variational inference in PPLs, based on compositional program transformation. In our approach, variational objectives are expressed as programs, that may employ first-class constructs for computing densities of and expected values under user-defined models and variational families. We then transform these programs systematically into unbiased gradient estimators for optimizing the objectives they define. Our design enables modular reasoning about many interacting concerns, including automatic differentiation, density accumulation, tracing, and the application of unbiased gradient estimation strategies. Additionally, relative to existing support for VI in PPLs, our design increases expressiveness along three axes: (1) it supports an open-ended set of user-defined variational objectives, rather than a fixed menu of options; (2) it supports a combinatorial space of gradient estimation strategies, many not automated by today's PPLs; and (3) it supports a broader class of models and variational families, because it supports constructs for approximate marginalization and normalization (previously introduced only for Monte Carlo inference). We implement our approach in an extension to the Gen probabilistic programming system (genjax.vi, implemented in JAX), and evaluate on several deep generative modeling tasks, showing minimal performance overhead vs. hand-coded implementations and performance competitive with well-established open-source PPLs.
Deep Learning Method to Predict Wound Healing Progress Based on Collagen Fibers in Wound Tissue
May 08, 2024Wound healing is a complex process involving changes in collagen fibers. Accurate monitoring of these changes is crucial for assessing the progress of wound healing and has significant implications for guiding clinical treatment strategies and drug screening. However, traditional quantitative analysis methods focus on spatial characteristics such as collagen fiber alignment and variance, lacking threshold standards to differentiate between different stages of wound healing. To address this issue, we propose an innovative approach based on deep learning to predict the progression of wound healing by analyzing collagen fiber features in histological images of wound tissue. Leveraging the unique learning capabilities of deep learning models, our approach captures the feature variations of collagen fibers in histological images from different categories and classifies them into various stages of wound healing. To overcome the limited availability of histological image data, we employ a transfer learning strategy. Specifically, we fine-tune a VGG16 model pretrained on the ImageNet dataset to adapt it to the classification task of histological images of wounds. Through this process, our model achieves 82% accuracy in classifying six stages of wound healing. Furthermore, to enhance the interpretability of the model, we employ a class activation mapping technique called LayerCAM. LayerCAM reveals the image regions on which the model relies when making predictions, providing transparency to the model's decision-making process. This visualization not only helps us understand how the model identifies and evaluates collagen fiber features but also enhances trust in the model's prediction results. To the best of our knowledge, our proposed model is the first deep learning-based classification model used for predicting wound healing stages.
3DMIT: 3D Multi-modal Instruction Tuning for Scene Understanding
Jan 16, 2024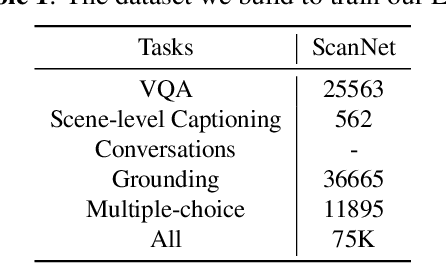
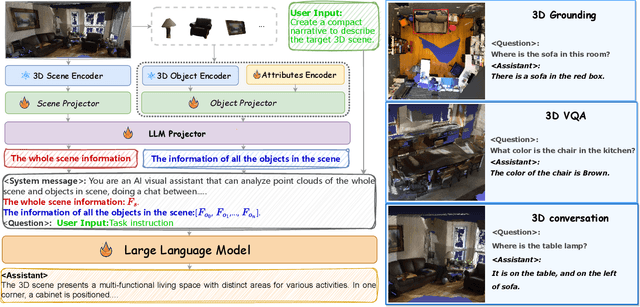
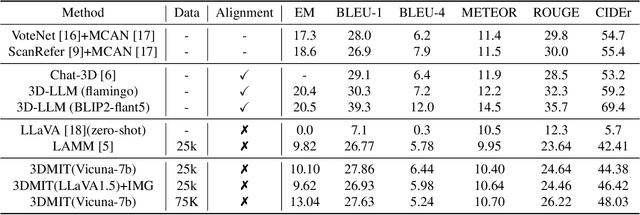

The remarkable potential of multi-modal large language models (MLLMs) in comprehending both vision and language information has been widely acknowledged. However, the scarcity of 3D scenes-language pairs in comparison to their 2D counterparts, coupled with the inadequacy of existing approaches in understanding of 3D scenes by LLMs, poses a significant challenge. In response, we collect and construct an extensive dataset comprising 75K instruction-response pairs tailored for 3D scenes. This dataset addresses tasks related to 3D VQA, 3D grounding, and 3D conversation. To further enhance the integration of 3D spatial information into LLMs, we introduce a novel and efficient prompt tuning paradigm, 3DMIT. This paradigm eliminates the alignment stage between 3D scenes and language and extends the instruction prompt with the 3D modality information including the entire scene and segmented objects. We evaluate the effectiveness of our method across diverse tasks in the 3D scene domain and find that our approach serves as a strategic means to enrich LLMs' comprehension of the 3D world. Our code is available at https://github.com/staymylove/3DMIT.
Fairy: Fast Parallelized Instruction-Guided Video-to-Video Synthesis
Dec 20, 2023



In this paper, we introduce Fairy, a minimalist yet robust adaptation of image-editing diffusion models, enhancing them for video editing applications. Our approach centers on the concept of anchor-based cross-frame attention, a mechanism that implicitly propagates diffusion features across frames, ensuring superior temporal coherence and high-fidelity synthesis. Fairy not only addresses limitations of previous models, including memory and processing speed. It also improves temporal consistency through a unique data augmentation strategy. This strategy renders the model equivariant to affine transformations in both source and target images. Remarkably efficient, Fairy generates 120-frame 512x384 videos (4-second duration at 30 FPS) in just 14 seconds, outpacing prior works by at least 44x. A comprehensive user study, involving 1000 generated samples, confirms that our approach delivers superior quality, decisively outperforming established methods.
AVID: Any-Length Video Inpainting with Diffusion Model
Dec 06, 2023



Recent advances in diffusion models have successfully enabled text-guided image inpainting. While it seems straightforward to extend such editing capability into video domain, there has been fewer works regarding text-guided video inpainting. Given a video, a masked region at its initial frame, and an editing prompt, it requires a model to do infilling at each frame following the editing guidance while keeping the out-of-mask region intact. There are three main challenges in text-guided video inpainting: ($i$) temporal consistency of the edited video, ($ii$) supporting different inpainting types at different structural fidelity level, and ($iii$) dealing with variable video length. To address these challenges, we introduce Any-Length Video Inpainting with Diffusion Model, dubbed as AVID. At its core, our model is equipped with effective motion modules and adjustable structure guidance, for fixed-length video inpainting. Building on top of that, we propose a novel Temporal MultiDiffusion sampling pipeline with an middle-frame attention guidance mechanism, facilitating the generation of videos with any desired duration. Our comprehensive experiments show our model can robustly deal with various inpainting types at different video duration range, with high quality. More visualization results is made publicly available at https://zhang-zx.github.io/AVID/ .
PPL Bench: Evaluation Framework For Probabilistic Programming Languages
Oct 17, 2020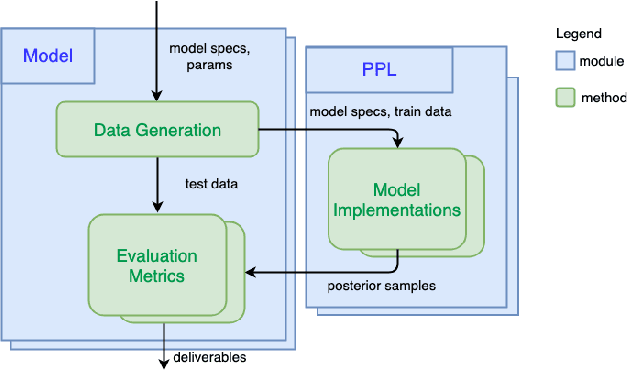
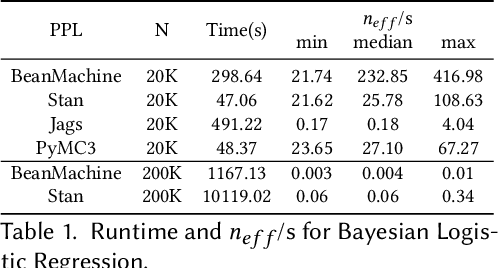
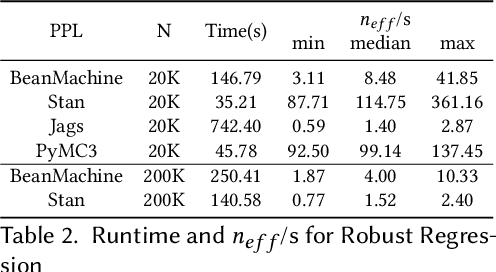
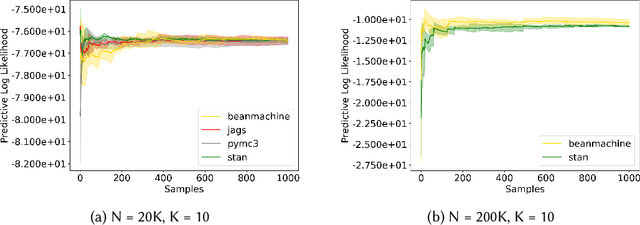
We introduce PPL Bench, a new benchmark for evaluating Probabilistic Programming Languages (PPLs) on a variety of statistical models. The benchmark includes data generation and evaluation code for a number of models as well as implementations in some common PPLs. All of the benchmark code and PPL implementations are available on Github. We welcome contributions of new models and PPLs and as well as improvements in existing PPL implementations. The purpose of the benchmark is two-fold. First, we want researchers as well as conference reviewers to be able to evaluate improvements in PPLs in a standardized setting. Second, we want end users to be able to pick the PPL that is most suited for their modeling application. In particular, we are interested in evaluating the accuracy and speed of convergence of the inferred posterior. Each PPL only needs to provide posterior samples given a model and observation data. The framework automatically computes and plots growth in predictive log-likelihood on held out data in addition to reporting other common metrics such as effective sample size and $\hat{r}$.