 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Order Sub-questions for Complex Question Answering
Nov 12, 2019
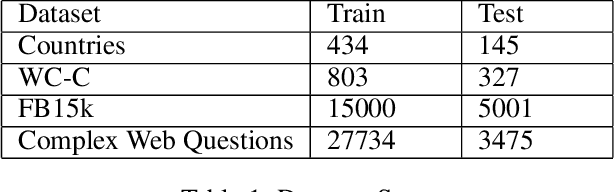
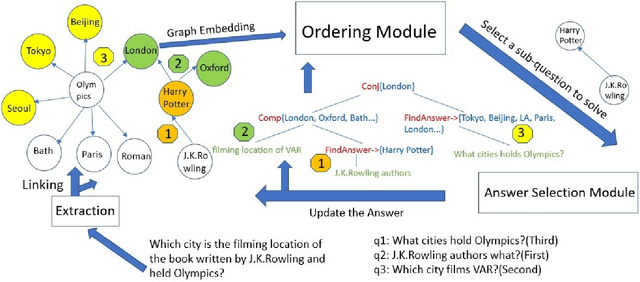
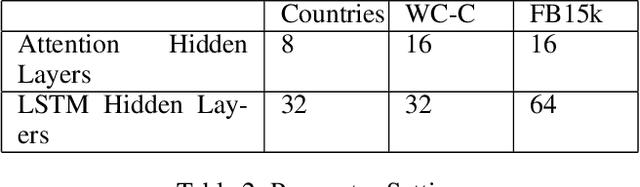
Answering complex questions involving multiple entities and relations is a challenging task. Logically, the answer to a complex question should be derived by decomposing the complex question into multiple simple sub-questions and then answering those sub-questions. Existing work has followed this strategy but has not attempted to optimize the order of how those sub-questions are answered. As a result, the sub-questions are answered in an arbitrary order, leading to larger search space and a higher risk of missing an answer. In this paper, we propose a novel reinforcement learning(RL) approach to answering complex questions that can learn a policy to dynamically decide which sub-question should be answered at each stage of reasoning. We lever-age the expected value-variance criterion to enable the learned policy to balance between the risk and utility of answering a sub-question. Experiment results show that the RL approach can substantially improve the optimality of ordering the sub-questions, leading to improved accuracy of question answering. The proposed method for learning to order sub-questions is general and can thus be potentially combined with many existing ideas for answering complex questions to enhance their performance.