 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial 3D-LLM: Exploring Spatial Awareness in 3D Vision-Language Models
Jul 22, 2025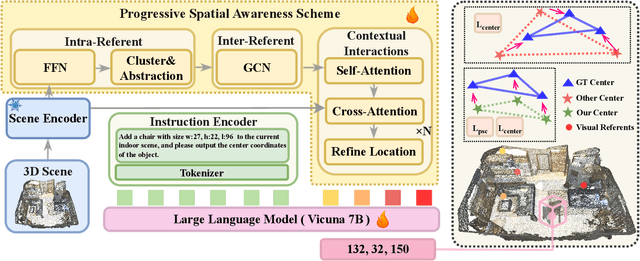

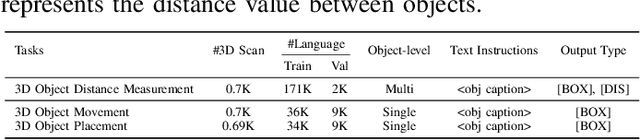
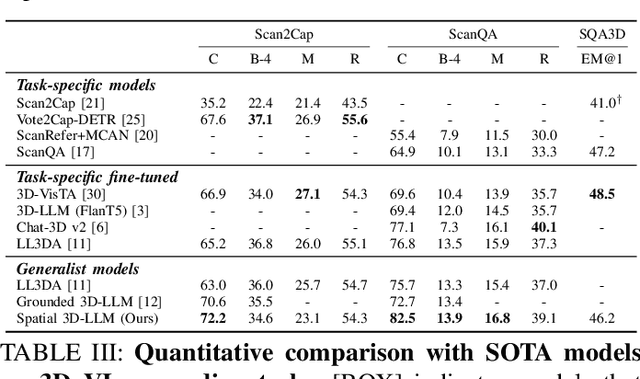
New era has unlocked exciting possibilities for extending Large Language Models (LLMs) to tackle 3D vision-language tasks. However, most existing 3D multimodal LLMs (MLLMs) rely on compressing holistic 3D scene information or segmenting independent objects to perform these tasks, which limits their spatial awareness due to insufficient representation of the richness inherent in 3D scenes. To overcome these limitations, we propose Spatial 3D-LLM, a 3D MLLM specifically designed to enhance spatial awareness for 3D vision-language tasks by enriching the spatial embeddings of 3D scenes. Spatial 3D-LLM integrates an LLM backbone with a progressive spatial awareness scheme that progressively captures spatial information as the perception field expands, generating location-enriched 3D scene embeddings to serve as visual prompts. Furthermore, we introduce two novel tasks: 3D object distance measurement and 3D layout editing, and construct a 3D instruction dataset, MODEL, to evaluate the model's spatial awareness capabilities. Experimental results demonstrate that Spatial 3D-LLM achieves state-of-the-art performance across a wide range of 3D vision-language tasks, revealing the improvements stemmed from our progressive spatial awareness scheme of mining more profound spatial information. Our code is available at https://github.com/bjshuyuan/Spatial-3D-LLM.
R3GS: Gaussian Splatting for Robust Reconstruction and Relocalization in Unconstrained Image Collections
May 21, 2025



We propose R3GS, a robust reconstruction and relocalization framework tailored for unconstrained datasets. Our method uses a hybrid representation during training. Each anchor combines a global feature from a convolutional neural network (CNN) with a local feature encoded by the multiresolution hash grids [2]. Subsequently, several shallow multi-layer perceptrons (MLPs) predict the attributes of each Gaussians, including color, opacity, and covariance. To mitigate the adverse effects of transient objects on the reconstruction process, we ffne-tune a lightweight human detection network. Once ffne-tuned, this network generates a visibility map that efffciently generalizes to other transient objects (such as posters, banners, and cars) with minimal need for further adaptation. Additionally, to address the challenges posed by sky regions in outdoor scenes, we propose an effective sky-handling technique that incorporates a depth prior as a constraint. This allows the inffnitely distant sky to be represented on the surface of a large-radius sky sphere, signiffcantly reducing ffoaters caused by errors in sky reconstruction. Furthermore, we introduce a novel relocalization method that remains robust to changes in lighting conditions while estimating the camera pose of a given image within the reconstructed 3DGS scene. As a result, R3GS significantly enhances rendering ffdelity, improves both training and rendering efffciency, and reduces storage requirements. Our method achieves state-of-the-art performance compared to baseline methods on in-the-wild datasets. The code will be made open-source following the acceptance of the paper.
* 7 pages, 4 figures
MMGDreamer: Mixed-Modality Graph for Geometry-Controllable 3D Indoor Scene Generation
Feb 09, 2025Controllable 3D scene generation has extensive applications in virtual reality and interior design, where the generated scenes should exhibit high levels of realism and controllability in terms of geometry. Scene graphs provide a suitable data representation that facilitates these applications. However, current graph-based methods for scene generation are constrained to text-based inputs and exhibit insufficient adaptability to flexible user inputs, hindering the ability to precisely control object geometry. To address this issue, we propose MMGDreamer, a dual-branch diffusion model for scene generation that incorporates a novel Mixed-Modality Graph, visual enhancement module, and relation predictor. The mixed-modality graph allows object nodes to integrate textual and visual modalities, with optional relationships between nodes. It enhances adaptability to flexible user inputs and enables meticulous control over the geometry of objects in the generated scenes. The visual enhancement module enriches the visual fidelity of text-only nodes by constructing visual representations using text embeddings. Furthermore, our relation predictor leverages node representations to infer absent relationships between nodes, resulting in more coherent scene layouts. Extensive experimental results demonstrate that MMGDreamer exhibits superior control of object geometry, achieving state-of-the-art scene generation performance. Project page: https://yangzhifeio.github.io/project/MMGDreamer.
3DMIT: 3D Multi-modal Instruction Tuning for Scene Understanding
Jan 16, 2024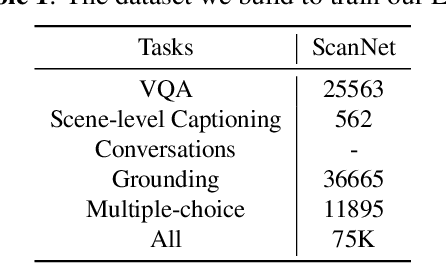
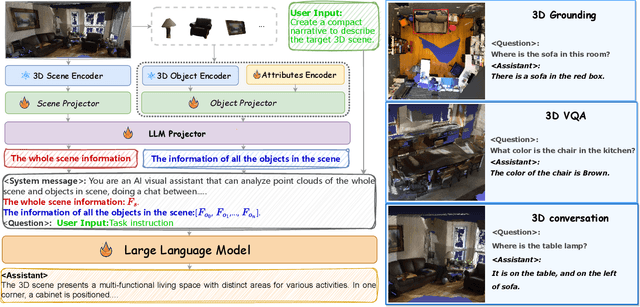
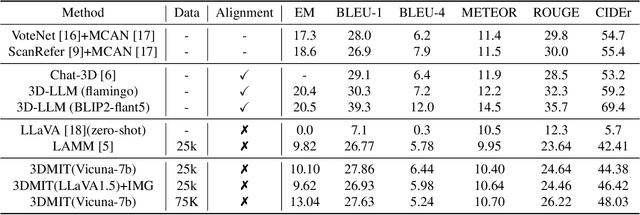

The remarkable potential of multi-modal large language models (MLLMs) in comprehending both vision and language information has been widely acknowledged. However, the scarcity of 3D scenes-language pairs in comparison to their 2D counterparts, coupled with the inadequacy of existing approaches in understanding of 3D scenes by LLMs, poses a significant challenge. In response, we collect and construct an extensive dataset comprising 75K instruction-response pairs tailored for 3D scenes. This dataset addresses tasks related to 3D VQA, 3D grounding, and 3D conversation. To further enhance the integration of 3D spatial information into LLMs, we introduce a novel and efficient prompt tuning paradigm, 3DMIT. This paradigm eliminates the alignment stage between 3D scenes and language and extends the instruction prompt with the 3D modality information including the entire scene and segmented objects. We evaluate the effectiveness of our method across diverse tasks in the 3D scene domain and find that our approach serves as a strategic means to enrich LLMs' comprehension of the 3D world. Our code is available at https://github.com/staymylove/3DMIT.