 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial 3D-LLM: Exploring Spatial Awareness in 3D Vision-Language Models
Jul 22, 2025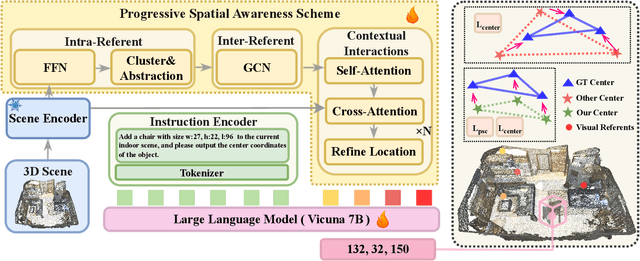

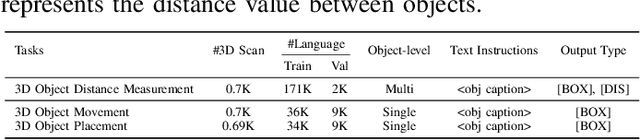
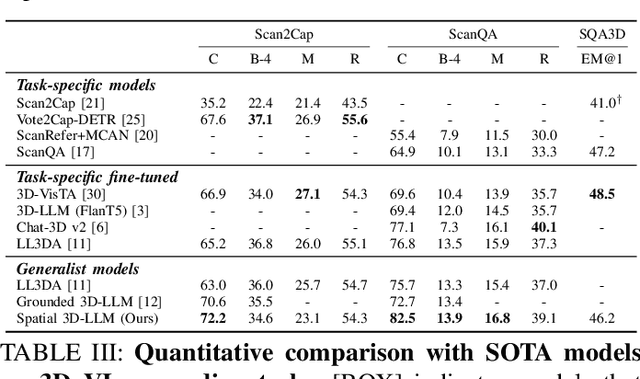
New era has unlocked exciting possibilities for extending Large Language Models (LLMs) to tackle 3D vision-language tasks. However, most existing 3D multimodal LLMs (MLLMs) rely on compressing holistic 3D scene information or segmenting independent objects to perform these tasks, which limits their spatial awareness due to insufficient representation of the richness inherent in 3D scenes. To overcome these limitations, we propose Spatial 3D-LLM, a 3D MLLM specifically designed to enhance spatial awareness for 3D vision-language tasks by enriching the spatial embeddings of 3D scenes. Spatial 3D-LLM integrates an LLM backbone with a progressive spatial awareness scheme that progressively captures spatial information as the perception field expands, generating location-enriched 3D scene embeddings to serve as visual prompts. Furthermore, we introduce two novel tasks: 3D object distance measurement and 3D layout editing, and construct a 3D instruction dataset, MODEL, to evaluate the model's spatial awareness capabilities. Experimental results demonstrate that Spatial 3D-LLM achieves state-of-the-art performance across a wide range of 3D vision-language tasks, revealing the improvements stemmed from our progressive spatial awareness scheme of mining more profound spatial information. Our code is available at https://github.com/bjshuyuan/Spatial-3D-LLM.
MMGDreamer: Mixed-Modality Graph for Geometry-Controllable 3D Indoor Scene Generation
Feb 09, 2025Controllable 3D scene generation has extensive applications in virtual reality and interior design, where the generated scenes should exhibit high levels of realism and controllability in terms of geometry. Scene graphs provide a suitable data representation that facilitates these applications. However, current graph-based methods for scene generation are constrained to text-based inputs and exhibit insufficient adaptability to flexible user inputs, hindering the ability to precisely control object geometry. To address this issue, we propose MMGDreamer, a dual-branch diffusion model for scene generation that incorporates a novel Mixed-Modality Graph, visual enhancement module, and relation predictor. The mixed-modality graph allows object nodes to integrate textual and visual modalities, with optional relationships between nodes. It enhances adaptability to flexible user inputs and enables meticulous control over the geometry of objects in the generated scenes. The visual enhancement module enriches the visual fidelity of text-only nodes by constructing visual representations using text embeddings. Furthermore, our relation predictor leverages node representations to infer absent relationships between nodes, resulting in more coherent scene layouts. Extensive experimental results demonstrate that MMGDreamer exhibits superior control of object geometry, achieving state-of-the-art scene generation performance. Project page: https://yangzhifeio.github.io/project/MMGDreamer.
Beyond Window-Based Detection: A Graph-Centric Framework for Discrete Log Anomaly Detection
Jan 21, 2025



Detecting anomalies in discrete event logs is critical for ensuring system reliability, security, and efficiency. Traditional window-based methods for log anomaly detection often suffer from context bias and fuzzy localization, which hinder their ability to precisely and efficiently identify anomalies. To address these challenges, we propose a graph-centric framework, TempoLog, which leverages multi-scale temporal graph networks for discrete log anomaly detection. Unlike conventional methods, TempoLog constructs continuous-time dynamic graphs directly from event logs, eliminating the need for fixed-size window grouping. By representing log templates as nodes and their temporal relationships as edges, the framework dynamically captures both local and global dependencies across multiple temporal scales. Additionally, a semantic-aware model enhances detection by incorporating rich contextual information. Extensive experiments on public datasets demonstrate that our method achieves state-of-the-art performance in event-level anomaly detection, significantly outperforming existing approaches in both accuracy and efficiency.
Quantum Machine Learning in Log-based Anomaly Detection: Challenges and Opportunities
Dec 18, 2024Log-based anomaly detection (LogAD) is the main component of Artificial Intelligence for IT Operations (AIOps), which can detect anomalous that occur during the system on-the-fly. Existing methods commonly extract log sequence features using classical machine learning techniques to identify whether a new sequence is an anomaly or not. However, these classical approaches often require trade-offs between efficiency and accuracy. The advent of quantum machine learning (QML) offers a promising alternative. By transforming parts of classical machine learning computations into parameterized quantum circuits (PQCs), QML can significantly reduce the number of trainable parameters while maintaining accuracy comparable to classical counterparts. In this work, we introduce a unified framework, \ourframework{}, for evaluating QML models in the context of LogAD. This framework incorporates diverse log data, integrated QML models, and comprehensive evaluation metrics. State-of-the-art methods such as DeepLog, LogAnomaly, and LogRobust, along with their quantum-transformed counterparts, are included in our framework.Beyond standard metrics like F1 score, precision, and recall, our evaluation extends to factors critical to QML performance, such as specificity, the number of circuits, circuit design, and quantum state encoding. Using \ourframework{}, we conduct extensive experiments to assess the performance of these models and their quantum counterparts, uncovering valuable insights and paving the way for future research in QML model selection and design for LogAD.
LogGPT: Exploring ChatGPT for Log-Based Anomaly Detection
Sep 03, 2023



The increasing volume of log data produced by software-intensive systems makes it impractical to analyze them manually. Many deep learning-based methods have been proposed for log-based anomaly detection. These methods face several challenges such as high-dimensional and noisy log data, class imbalance, generalization, and model interpretability. Recently, ChatGPT has shown promising results in various domains. However, there is still a lack of study on the application of ChatGPT for log-based anomaly detection. In this work, we proposed LogGPT, a log-based anomaly detection framework based on ChatGPT. By leveraging the ChatGPT's language interpretation capabilities, LogGPT aims to explore the transferability of knowledge from large-scale corpora to log-based anomaly detection. We conduct experiments to evaluate the performance of LogGPT and compare it with three deep learning-based methods on BGL and Spirit datasets. LogGPT shows promising results and has good interpretability. This study provides preliminary insights into prompt-based models, such as ChatGPT, for the log-based anomaly detection task.
Efficient Incremental Text-to-Speech on GPUs
Dec 05, 2022Incremental text-to-speech, also known as streaming TTS, has been increasingly applied to online speech applications that require ultra-low response latency to provide an optimal user experience. However, most of the existing speech synthesis pipelines deployed on GPU are still non-incremental, which uncovers limitations in high-concurrency scenarios, especially when the pipeline is built with end-to-end neural network models. To address this issue, we present a highly efficient approach to perform real-time incremental TTS on GPUs with Instant Request Pooling and Module-wise Dynamic Batching. Experimental results demonstrate that the proposed method is capable of producing high-quality speech with a first-chunk latency lower than 80ms under 100 QPS on a single NVIDIA A10 GPU and significantly outperforms the non-incremental twin in both concurrency and latency. Our work reveals the effectiveness of high-performance incremental TTS on GPUs.