 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiDAR-EVS: Enhance Extrapolated View Synthesis for 3D Gaussian Splatting with Pseudo-LiDAR Supervision
Mar 16, 20263D Gaussian Splatting (3DGS) has emerged as a powerful technique for real-time LiDAR and camera synthesis in autonomous driving simulation. However, simulating LiDAR with 3DGS remains challenging for extrapolated views beyond the training trajectory, as existing methods are typically trained on single-traversal sensor scans, suffer from severe overfitting and poor generalization to novel ego-vehicle paths. To enable reliable simulation of LiDAR along unseen driving trajectories without external multi-pass data, we present LiDAR-EVS, a lightweight framework for robust extrapolated-view LiDAR simulation in autonomous driving. Designed to be plug-and-play, LiDAR-EVS readily extends to diverse LiDAR sensors and neural rendering baselines with minimal modification. Our framework comprises two key components: (1) pseudo extrapolated-view point cloud supervision with multi-frame LiDAR fusion, view transformation, occlusion curling, and intensity adjustment; (2) spatially-constrained dropout regularization that promotes robustness to diverse trajectory variations encountered in real-world driving. Extensive experiments demonstrate that LiDAR-EVS achieves SOTA performance on extrapolated-view LiDAR synthesis across three datasets, making it a promising tool for data-driven simulation, closed-loop evaluation, and synthetic data generation in autonomous driving systems.
FP8-RL: A Practical and Stable Low-Precision Stack for LLM Reinforcement Learning
Jan 26, 2026Reinforcement learning (RL) for large language models (LLMs) is increasingly bottlenecked by rollout (generation), where long output sequence lengths make attention and KV-cache memory dominate end-to-end step time. FP8 offers an attractive lever for accelerating RL by reducing compute cost and memory traffic during rollout, but applying FP8 in RL introduces unique engineering and algorithmic challenges: policy weights change every step (requiring repeated quantization and weight synchronization into the inference engine) and low-precision rollouts can deviate from the higher-precision policy assumed by the trainer, causing train-inference mismatch and potential instability. This report presents a practical FP8 rollout stack for LLM RL, implemented in the veRL ecosystem with support for common training backends (e.g., FSDP/Megatron-LM) and inference engines (e.g., vLLM/SGLang). We (i) enable FP8 W8A8 linear-layer rollout using blockwise FP8 quantization, (ii) extend FP8 to KV-cache to remove long-context memory bottlenecks via per-step QKV scale recalibration, and (iii) mitigate mismatch using importance-sampling-based rollout correction (token-level TIS/MIS variants). Across dense and MoE models, these techniques deliver up to 44% rollout throughput gains while preserving learning behavior comparable to BF16 baselines.
AIConfigurator: Lightning-Fast Configuration Optimization for Multi-Framework LLM Serving
Jan 09, 2026Optimizing Large Language Model (LLM) inference in production systems is increasingly difficult due to dynamic workloads, stringent latency/throughput targets, and a rapidly expanding configuration space. This complexity spans not only distributed parallelism strategies (tensor/pipeline/expert) but also intricate framework-specific runtime parameters such as those concerning the enablement of CUDA graphs, available KV-cache memory fractions, and maximum token capacity, which drastically impact performance. The diversity of modern inference frameworks (e.g., TRT-LLM, vLLM, SGLang), each employing distinct kernels and execution policies, makes manual tuning both framework-specific and computationally prohibitive. We present AIConfigurator, a unified performance-modeling system that enables rapid, framework-agnostic inference configuration search without requiring GPU-based profiling. AIConfigurator combines (1) a methodology that decomposes inference into analytically modelable primitives - GEMM, attention, communication, and memory operations while capturing framework-specific scheduling dynamics; (2) a calibrated kernel-level performance database for these primitives across a wide range of hardware platforms and popular open-weights models (GPT-OSS, Qwen, DeepSeek, LLama, Mistral); and (3) an abstraction layer that automatically resolves optimal launch parameters for the target backend, seamlessly integrating into production-grade orchestration systems. Evaluation on production LLM serving workloads demonstrates that AIConfigurator identifies superior serving configurations that improve performance by up to 40% for dense models (e.g., Qwen3-32B) and 50% for MoE architectures (e.g., DeepSeek-V3), while completing searches within 30 seconds on average. Enabling the rapid exploration of vast design spaces - from cluster topology down to engine specific flags.
Semi-supervised Learning for Code-Switching ASR with Large Language Model Filter
Jul 05, 2024
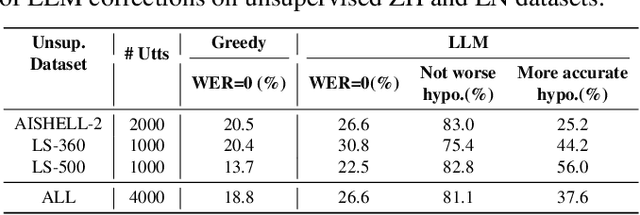


Code-switching (CS) phenomenon occurs when words or phrases from different languages are alternated in a single sentence. Due to data scarcity, building an effective CS Automatic Speech Recognition (ASR) system remains challenging. In this paper, we propose to enhance CS-ASR systems by utilizing rich unsupervised monolingual speech data within a semi-supervised learning framework, particularly when access to CS data is limited. To achieve this, we establish a general paradigm for applying noisy student training (NST) to the CS-ASR task. Specifically, we introduce the LLM-Filter, which leverages well-designed prompt templates to activate the correction capability of large language models (LLMs) for monolingual data selection and pseudo-labels refinement during NST. Our experiments on the supervised ASRU-CS and unsupervised AISHELL-2 and LibriSpeech datasets show that our method not only achieves significant improvements over supervised and semi-supervised learning baselines for the CS task, but also attains better performance compared with the fully-supervised oracle upper-bound on the CS English part. Additionally, we further investigate the influence of accent on AESRC dataset and demonstrate that our method can get achieve additional benefits when the monolingual data contains relevant linguistic characteristic.
Romanization Encoding For Multilingual ASR
Jul 05, 2024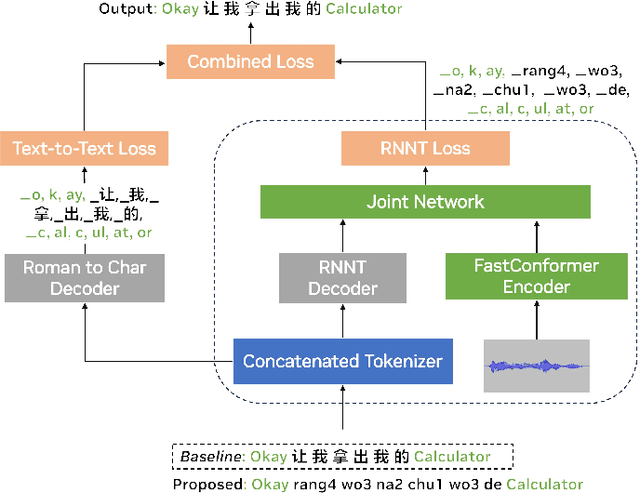


We introduce romanization encoding for script-heavy languages to optimize multilingual and code-switching Automatic Speech Recognition (ASR) systems. By adopting romanization encoding alongside a balanced concatenated tokenizer within a FastConformer-RNNT framework equipped with a Roman2Char module, we significantly reduce vocabulary and output dimensions, enabling larger training batches and reduced memory consumption. Our method decouples acoustic modeling and language modeling, enhancing the flexibility and adaptability of the system. In our study, applying this method to Mandarin-English ASR resulted in a remarkable 63.51% vocabulary reduction and notable performance gains of 13.72% and 15.03% on SEAME code-switching benchmarks. Ablation studies on Mandarin-Korean and Mandarin-Japanese highlight our method's strong capability to address the complexities of other script-heavy languages, paving the way for more versatile and effective multilingual ASR systems.
Incremental FastPitch: Chunk-based High Quality Text to Speech
Jan 03, 2024Parallel text-to-speech models have been widely applied for real-time speech synthesis, and they offer more controllability and a much faster synthesis process compared with conventional auto-regressive models. Although parallel models have benefits in many aspects, they become naturally unfit for incremental synthesis due to their fully parallel architecture such as transformer. In this work, we propose Incremental FastPitch, a novel FastPitch variant capable of incrementally producing high-quality Mel chunks by improving the architecture with chunk-based FFT blocks, training with receptive-field constrained chunk attention masks, and inference with fixed size past model states. Experimental results show that our proposal can produce speech quality comparable to the parallel FastPitch, with a significant lower latency that allows even lower response time for real-time speech applications.
Efficient Incremental Text-to-Speech on GPUs
Dec 05, 2022Incremental text-to-speech, also known as streaming TTS, has been increasingly applied to online speech applications that require ultra-low response latency to provide an optimal user experience. However, most of the existing speech synthesis pipelines deployed on GPU are still non-incremental, which uncovers limitations in high-concurrency scenarios, especially when the pipeline is built with end-to-end neural network models. To address this issue, we present a highly efficient approach to perform real-time incremental TTS on GPUs with Instant Request Pooling and Module-wise Dynamic Batching. Experimental results demonstrate that the proposed method is capable of producing high-quality speech with a first-chunk latency lower than 80ms under 100 QPS on a single NVIDIA A10 GPU and significantly outperforms the non-incremental twin in both concurrency and latency. Our work reveals the effectiveness of high-performance incremental TTS on GPUs.
Improving Noisy Student Training on Non-target Domain Data for Automatic Speech Recognition
Nov 09, 2022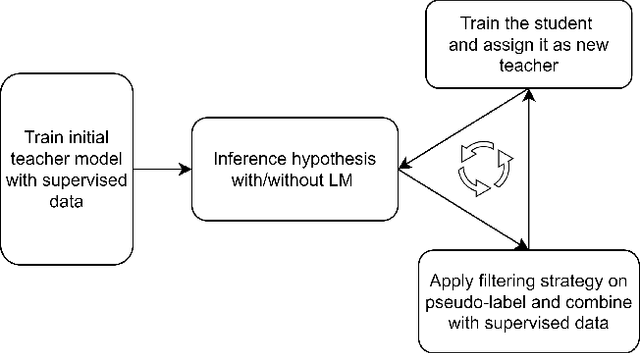


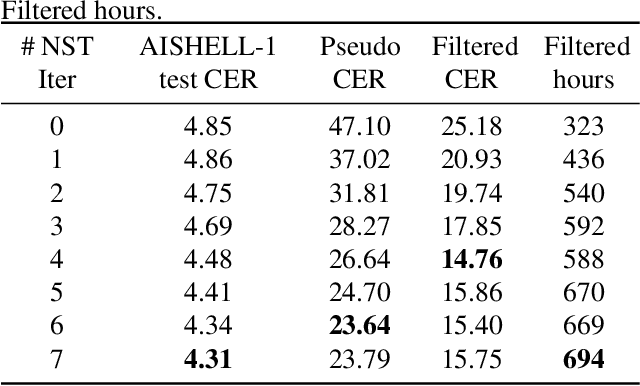
Noisy Student Training (NST) has recently demonstrated extremely strong performance in Automatic Speech Recognition (ASR). In this paper, we propose a data selection strategy named LM Filter to improve the performances of NST on non-target domain data in ASR tasks. Hypothesis with and without Language Model are generated and CER differences between them are utilized as a filter threshold. Results reveal that significant improvements of 10.4% compared with no data filtering baselines. We can achieve 3.31% CER in AISHELL-1 test set, which is best result from our knowledge without any other supervised data. We also perform evaluations on supervised 1000 hour AISHELL-2 dataset and competitive results of 4.72% CER can be achieved.
M$^2$DQN: A Robust Method for Accelerating Deep Q-learning Network
Sep 16, 2022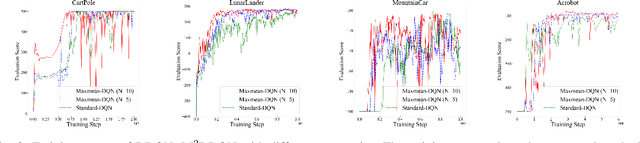
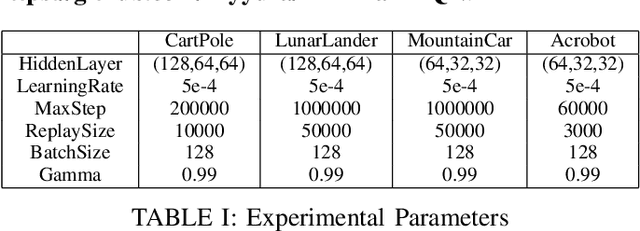
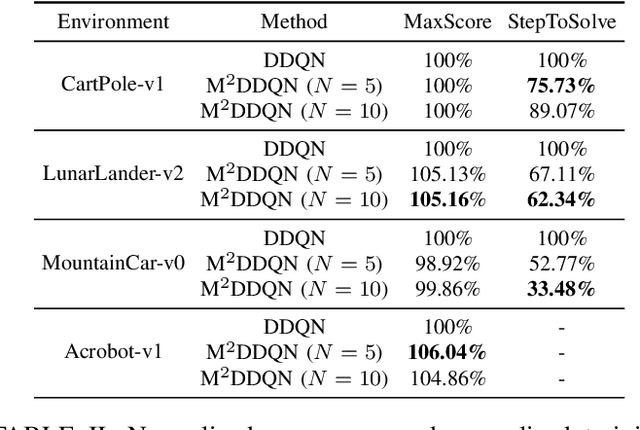
Deep Q-learning Network (DQN) is a successful way which combines reinforcement learning with deep neural networks and leads to a widespread application of reinforcement learning. One challenging problem when applying DQN or other reinforcement learning algorithms to real world problem is data collection. Therefore, how to improve data efficiency is one of the most important problems in the research of reinforcement learning. In this paper, we propose a framework which uses the Max-Mean loss in Deep Q-Network (M$^2$DQN). Instead of sampling one batch of experiences in the training step, we sample several batches from the experience replay and update the parameters such that the maximum TD-error of these batches is minimized. The proposed method can be combined with most of existing techniques of DQN algorithm by replacing the loss function. We verify the effectiveness of this framework with one of the most widely used techniques, Double DQN (DDQN), in several gym games. The results show that our method leads to a substantial improvement in both the learning speed and performance.