Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Noisy Student Training on Non-target Domain Data for Automatic Speech Recognition
Paper and Code
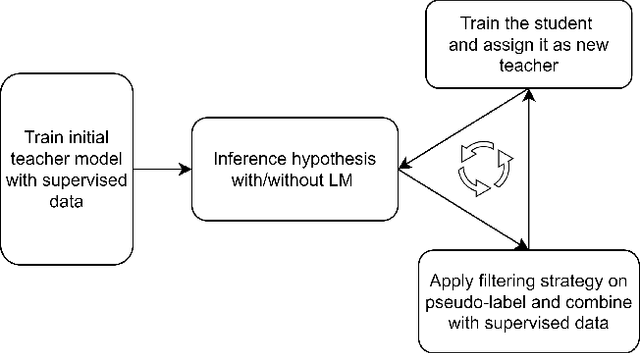


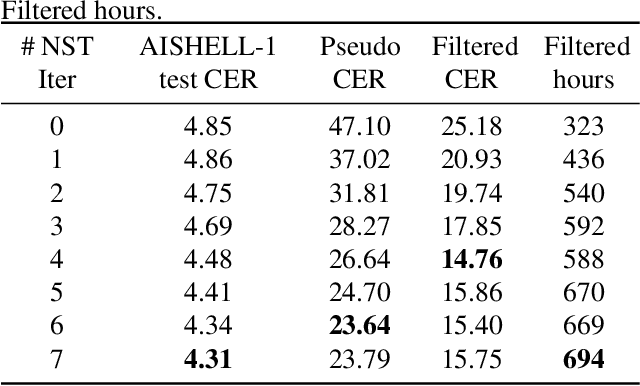
Noisy Student Training (NST) has recently demonstrated extremely strong performance in Automatic Speech Recognition (ASR). In this paper, we propose a data selection strategy named LM Filter to improve the performances of NST on non-target domain data in ASR tasks. Hypothesis with and without Language Model are generated and CER differences between them are utilized as a filter threshold. Results reveal that significant improvements of 10.4% compared with no data filtering baselines. We can achieve 3.31% CER in AISHELL-1 test set, which is best result from our knowledge without any other supervised data. We also perform evaluations on supervised 1000 hour AISHELL-2 dataset and competitive results of 4.72% CER can be achieved.
View paper on