 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM$^2$DQN: A Robust Method for Accelerating Deep Q-learning Network
Sep 16, 2022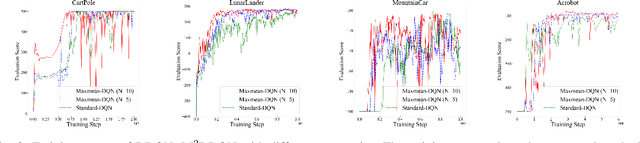
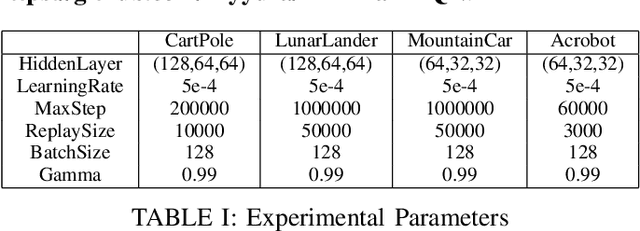
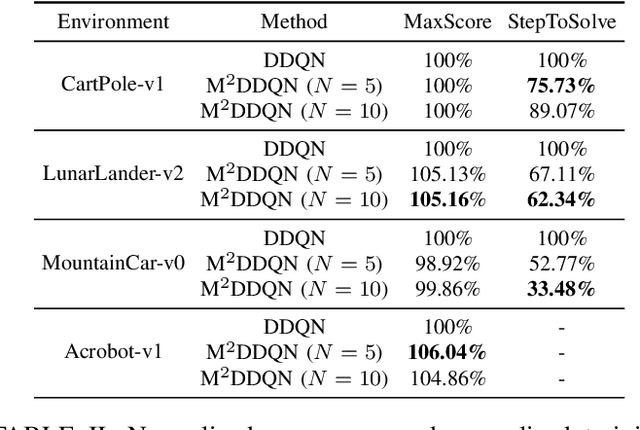
Deep Q-learning Network (DQN) is a successful way which combines reinforcement learning with deep neural networks and leads to a widespread application of reinforcement learning. One challenging problem when applying DQN or other reinforcement learning algorithms to real world problem is data collection. Therefore, how to improve data efficiency is one of the most important problems in the research of reinforcement learning. In this paper, we propose a framework which uses the Max-Mean loss in Deep Q-Network (M$^2$DQN). Instead of sampling one batch of experiences in the training step, we sample several batches from the experience replay and update the parameters such that the maximum TD-error of these batches is minimized. The proposed method can be combined with most of existing techniques of DQN algorithm by replacing the loss function. We verify the effectiveness of this framework with one of the most widely used techniques, Double DQN (DDQN), in several gym games. The results show that our method leads to a substantial improvement in both the learning speed and performance.