 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified and Reproducible Experimentation Framework for Speech Understanding
May 29, 2026Speech foundation models and Speech LLMs have advanced speech understanding, yet deployment-oriented model selection is hindered by non-comparable evaluations caused by mismatched post-processing, and by training results that are hard to reproduce across data scales and pipelines. We present SURE, a unified experimentation framework that standardizes prediction formats, normalization, and scoring. SURE evaluates strong systems across paradigms, from conventional pipelines to Speech LLMs, on representative tasks under realistic acoustic and linguistic stressors. Beyond evaluation, SURE introduces an agent-assisted training conversion flow that maps paper and code into versioned, runnable training pipelines under a unified protocol on matched open-data subsets. Overall, SURE improves comparability and reproducibility for deployment-oriented evaluation.
HoliTok:A Coutinuous Holistic Tokenization with Robust Dual Capabilities of Speech Generation and Understanding
May 28, 2026Unified speech foundation models require a holistic tokenization space that is both learnable by language models and decodable into high-quality waveforms. Existing speech tokenizers, however, often fail to satisfy these requirements simultaneously, leading to increased architectural complexity and more involved training designs. We propose HoliTok, a continuous Holistic speech Tokenization model designed for unified generation-understanding modeling. HoliTok encodes 48~kHz speech into a compact 25~Hz sequence of 128-dimensional latents. It is trained with a progressive strategy that jointly preserves signal-level fidelity, incorporates semantic information, and maintains strong latent learnability. Based on this tokenization, we build a unified AR+DiT model for speech synthesis and recognition, where the same latent sequence supports both generation-specific and unified generation-understanding tasks. Experiments show that HoliTok achieves competitive reconstruction fidelity, improves generative learnability for high-quality and controllable synthesis, and, among the evaluated representations, is the only one that operates robustly in our unified generation-understanding architecture without additional optimization tricks. These results suggest that HoliTok serves as an effective speech tokenizer and a foundational representation interface for unified spoken language modeling. The code is available at: https://github.com/bovod-sjtu/HoliTok.
Audio-Mind: An Auditable Agentic Framework for Audio Understanding
May 27, 2026Audio agents extend large audio-language models (LALMs) by decomposing audio questions into tool calls, intermediate evidence, and iterative reasoning steps. However, as LALMs become stronger, the key challenge shifts from enabling tool use to determining when agentic evidence acquisition genuinely benefits audio understanding. We propose Audio-Mind, an auditable and pluggable framework for conditional evidence acquisition in audio understanding. Audio-Mind dynamically combines a strong frontend with planner-guided tool use, preserving frontend judgment when initial evidence is sufficient while acquiring bounded external evidence for questions with unresolved evidence gaps. Experiments on MMAR and MSU-Bench show that Audio-Mind outperforms prior audio-agent baselines, reaching 80.4% accuracy on MMAR and 82.8% accuracy on MSU-Bench. A matched-backbone comparison highlights why this design matters: under strong audio frontends, agentic decomposition can become an orchestration bottleneck when the workflow does not preserve the frontend's holistic audio-grounded judgment. Beyond accuracy, Audio-Mind produces higher-quality, auditable reasoning traces that expose uncertainty, tool evidence, and answer rationales, offering a potential basis for more reliable audio-QA annotation and error analysis.
TASU2: Controllable CTC Simulation for Alignment and Low-Resource Adaptation of Speech LLMs
Apr 09, 2026Speech LLM post-training increasingly relies on efficient cross-modal alignment and robust low-resource adaptation, yet collecting large-scale audio-text pairs remains costly. Text-only alignment methods such as TASU reduce this burden by simulating CTC posteriors from transcripts, but they provide limited control over uncertainty and error rate, making curriculum design largely heuristic. We propose \textbf{TASU2}, a controllable CTC simulation framework that simulates CTC posterior distributions under a specified WER range, producing text-derived supervision that better matches the acoustic decoding interface. This enables principled post-training curricula that smoothly vary supervision difficulty without TTS. Across multiple source-to-target adaptation settings, TASU2 improves in-domain and out-of-domain recognition over TASU, and consistently outperforms strong baselines including text-only fine-tuning and TTS-based augmentation, while mitigating source-domain performance degradation.
TC-BiMamba: Trans-Chunk bidirectionally within BiMamba for unified streaming and non-streaming ASR
Feb 12, 2026This work investigates bidirectional Mamba (BiMamba) for unified streaming and non-streaming automatic speech recognition (ASR). Dynamic chunk size training enables a single model for offline decoding and streaming decoding with various latency settings. In contrast, existing BiMamba based streaming method is limited to fixed chunk size decoding. When dynamic chunk size training is applied, training overhead increases substantially. To tackle this issue, we propose the Trans-Chunk BiMamba (TC-BiMamba) for dynamic chunk size training. Trans-Chunk mechanism trains both bidirectional sequences in an offline style with dynamic chunk size. On the one hand, compared to traditional chunk-wise processing, TC-BiMamba simultaneously achieves 1.3 times training speedup, reduces training memory by 50%, and improves model performance since it can capture bidirectional context. On the other hand, experimental results show that TC-BiMamba outperforms U2++ and matches LC-BiMmaba with smaller model size.
Detect, Attend and Extract: Keyword Guided Target Speaker Extraction
Feb 08, 2026Target speaker extraction (TSE) aims to extract the speech of a target speaker from mixtures containing multiple competing speakers. Conventional TSE systems predominantly rely on speaker cues, such as pre-enrolled speech, to identify and isolate the target speaker. However, in many practical scenarios, clean enrollment utterances are unavailable, limiting the applicability of existing approaches. In this work, we propose DAE-TSE, a keyword-guided TSE framework that specifies the target speaker through distinct keywords they utter. By leveraging keywords (i.e., partial transcriptions) as cues, our approach provides a flexible and practical alternative to enrollment-based TSE. DAE-TSE follows the Detect-Attend-Extract (DAE) paradigm: it first detects the presence of the given keywords, then attends to the corresponding speaker based on the keyword content, and finally extracts the target speech. Experimental results demonstrate that DAE-TSE outperforms standard TSE systems that rely on clean enrollment speech. To the best of our knowledge, this is the first study to utilize partial transcription as a cue for specifying the target speaker in TSE, offering a flexible and practical solution for real-world scenarios. Our code and demo page are now publicly available.
Qwen3-ASR Technical Report
Jan 29, 2026In this report, we introduce Qwen3-ASR family, which includes two powerful all-in-one speech recognition models and a novel non-autoregressive speech forced alignment model. Qwen3-ASR-1.7B and Qwen3-ASR-0.6B are ASR models that support language identification and ASR for 52 languages and dialects. Both of them leverage large-scale speech training data and the strong audio understanding ability of their foundation model Qwen3-Omni. We conduct comprehensive internal evaluation besides the open-sourced benchmarks as ASR models might differ little on open-sourced benchmark scores but exhibit significant quality differences in real-world scenarios. The experiments reveal that the 1.7B version achieves SOTA performance among open-sourced ASR models and is competitive with the strongest proprietary APIs while the 0.6B version offers the best accuracy-efficiency trade-off. Qwen3-ASR-0.6B can achieve an average TTFT as low as 92ms and transcribe 2000 seconds speech in 1 second at a concurrency of 128. Qwen3-ForcedAligner-0.6B is an LLM based NAR timestamp predictor that is able to align text-speech pairs in 11 languages. Timestamp accuracy experiments show that the proposed model outperforms the three strongest force alignment models and takes more advantages in efficiency and versatility. To further accelerate the community research of ASR and audio understanding, we release these models under the Apache 2.0 license.
Time-Layer Adaptive Alignment for Speaker Similarity in Flow-Matching Based Zero-Shot TTS
Nov 13, 2025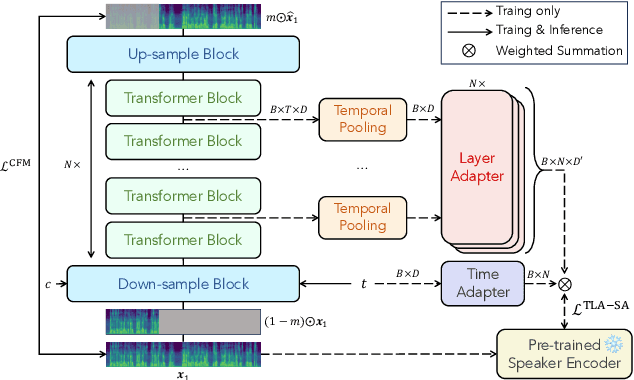

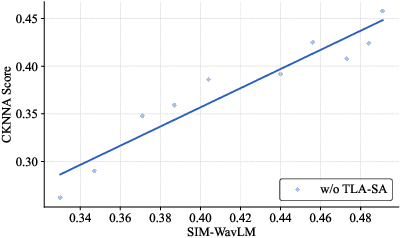

Flow-Matching (FM)-based zero-shot text-to-speech (TTS) systems exhibit high-quality speech synthesis and robust generalization capabilities. However, the speaker representation ability of such systems remains underexplored, primarily due to the lack of explicit speaker-specific supervision in the FM framework. To this end, we conduct an empirical analysis of speaker information distribution and reveal its non-uniform allocation across time steps and network layers, underscoring the need for adaptive speaker alignment. Accordingly, we propose Time-Layer Adaptive Speaker Alignment (TLA-SA), a loss that enhances speaker consistency by jointly leveraging temporal and hierarchical variations in speaker information. Experimental results show that TLA-SA significantly improves speaker similarity compared to baseline systems on both research- and industrial-scale datasets and generalizes effectively across diverse model architectures, including decoder-only language models (LM) and FM-based TTS systems free of LM.
Joint decoding method for controllable contextual speech recognition based on Speech LLM
Aug 12, 2025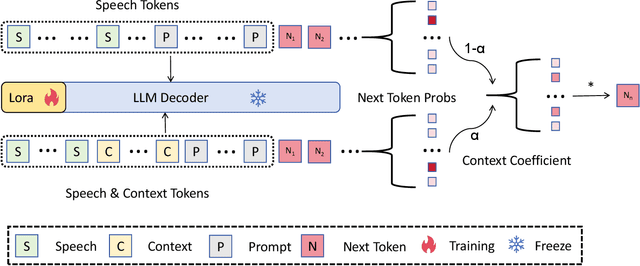
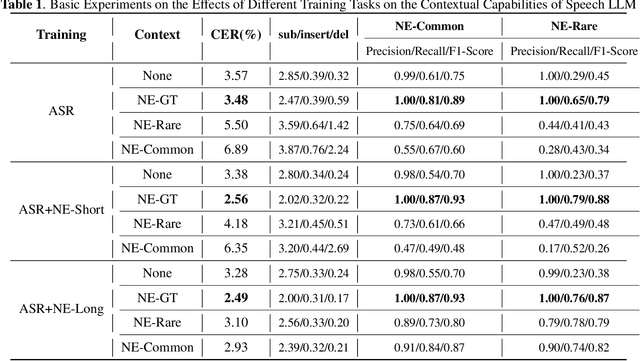
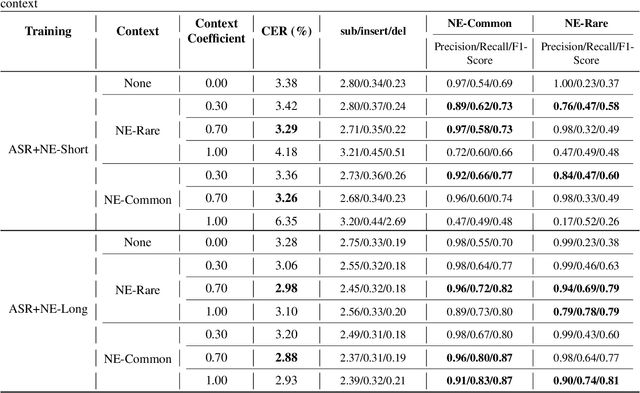
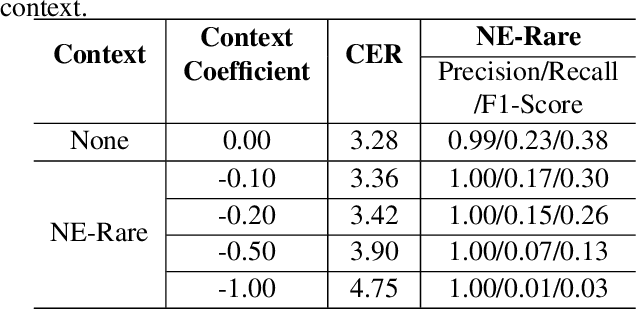
Contextual speech recognition refers to the ability to identify preferences for specific content based on contextual information. Recently, leveraging the contextual understanding capabilities of Speech LLM to achieve contextual biasing by injecting contextual information through prompts have emerged as a research hotspot.However, the direct information injection method via prompts relies on the internal attention mechanism of the model, making it impossible to explicitly control the extent of information injection. To address this limitation, we propose a joint decoding method to control the contextual information. This approach enables explicit control over the injected contextual information and achieving superior recognition performance. Additionally, Our method can also be used for sensitive word suppression recognition.Furthermore, experimental results show that even Speech LLM not pre-trained on long contextual data can acquire long contextual capabilities through our method.
Low-Resource Domain Adaptation for Speech LLMs via Text-Only Fine-Tuning
Jun 06, 2025



Recent advances in automatic speech recognition (ASR) have combined speech encoders with large language models (LLMs) through projection, forming Speech LLMs with strong performance. However, adapting them to new domains remains challenging, especially in low-resource settings where paired speech-text data is scarce. We propose a text-only fine-tuning strategy for Speech LLMs using unpaired target-domain text without requiring additional audio. To preserve speech-text alignment, we introduce a real-time evaluation mechanism during fine-tuning. This enables effective domain adaptation while maintaining source-domain performance. Experiments on LibriSpeech, SlideSpeech, and Medical datasets show that our method achieves competitive recognition performance, with minimal degradation compared to full audio-text fine-tuning. It also improves generalization to new domains without catastrophic forgetting, highlighting the potential of text-only fine-tuning for low-resource domain adaptation of ASR.