 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevBench: A Realistic, Developer-Informed Benchmark for Code Generation Models
Jan 17, 2026DevBench is a telemetry-driven benchmark designed to evaluate Large Language Models (LLMs) on realistic code completion tasks. It includes 1,800 evaluation instances across six programming languages and six task categories derived from real developer telemetry, such as API usage and code purpose understanding. Unlike prior benchmarks, it emphasizes ecological validity, avoids training data contamination, and enables detailed diagnostics. The evaluation combines functional correctness, similarity-based metrics, and LLM-judge assessments focused on usefulness and contextual relevance. 9 state-of-the-art models were assessed, revealing differences in syntactic precision, semantic reasoning, and practical utility. Our benchmark provides actionable insights to guide model selection and improvement-detail that is often missing from other benchmarks but is essential for both practical deployment and targeted model development.
Beyond Sharpness: A Flatness Decomposition Framework for Efficient Continual Learning
Jan 12, 2026Continual Learning (CL) aims to enable models to sequentially learn multiple tasks without forgetting previous knowledge. Recent studies have shown that optimizing towards flatter loss minima can improve model generalization. However, existing sharpness-aware methods for CL suffer from two key limitations: (1) they treat sharpness regularization as a unified signal without distinguishing the contributions of its components. and (2) they introduce substantial computational overhead that impedes practical deployment. To address these challenges, we propose FLAD, a novel optimization framework that decomposes sharpness-aware perturbations into gradient-aligned and stochastic-noise components, and show that retaining only the noise component promotes generalization. We further introduce a lightweight scheduling scheme that enables FLAD to maintain significant performance gains even under constrained training time. FLAD can be seamlessly integrated into various CL paradigms and consistently outperforms standard and sharpness-aware optimizers in diverse experimental settings, demonstrating its effectiveness and practicality in CL.
InfoSAM: Fine-Tuning the Segment Anything Model from An Information-Theoretic Perspective
May 28, 2025The Segment Anything Model (SAM), a vision foundation model, exhibits impressive zero-shot capabilities in general tasks but struggles in specialized domains. Parameter-efficient fine-tuning (PEFT) is a promising approach to unleash the potential of SAM in novel scenarios. However, existing PEFT methods for SAM neglect the domain-invariant relations encoded in the pre-trained model. To bridge this gap, we propose InfoSAM, an information-theoretic approach that enhances SAM fine-tuning by distilling and preserving its pre-trained segmentation knowledge. Specifically, we formulate the knowledge transfer process as two novel mutual information-based objectives: (i) to compress the domain-invariant relation extracted from pre-trained SAM, excluding pseudo-invariant information as possible, and (ii) to maximize mutual information between the relational knowledge learned by the teacher (pre-trained SAM) and the student (fine-tuned model). The proposed InfoSAM establishes a robust distillation framework for PEFT of SAM. Extensive experiments across diverse benchmarks validate InfoSAM's effectiveness in improving SAM family's performance on real-world tasks, demonstrating its adaptability and superiority in handling specialized scenarios.
CP-LLM: Context and Pixel Aware Large Language Model for Video Quality Assessment
May 21, 2025Video quality assessment (VQA) is a challenging research topic with broad applications. Effective VQA necessitates sensitivity to pixel-level distortions and a comprehensive understanding of video context to accurately determine the perceptual impact of distortions. Traditional hand-crafted and learning-based VQA models mainly focus on pixel-level distortions and lack contextual understanding, while recent LLM-based models struggle with sensitivity to small distortions or handle quality scoring and description as separate tasks. To address these shortcomings, we introduce CP-LLM: a Context and Pixel aware Large Language Model. CP-LLM is a novel multimodal LLM architecture featuring dual vision encoders designed to independently analyze perceptual quality at both high-level (video context) and low-level (pixel distortion) granularity, along with a language decoder subsequently reasons about the interplay between these aspects. This design enables CP-LLM to simultaneously produce robust quality scores and interpretable quality descriptions, with enhanced sensitivity to pixel distortions (e.g. compression artifacts). The model is trained via a multi-task pipeline optimizing for score prediction, description generation, and pairwise comparisons. Experiment results demonstrate that CP-LLM achieves state-of-the-art cross-dataset performance on established VQA benchmarks and superior robustness to pixel distortions, confirming its efficacy for comprehensive and practical video quality assessment in real-world scenarios.
Towards the Generalization of Multi-view Learning: An Information-theoretical Analysis
Jan 28, 2025Multiview learning has drawn widespread attention for its efficacy in leveraging cross-view consensus and complementarity information to achieve a comprehensive representation of data. While multi-view learning has undergone vigorous development and achieved remarkable success, the theoretical understanding of its generalization behavior remains elusive. This paper aims to bridge this gap by developing information-theoretic generalization bounds for multi-view learning, with a particular focus on multi-view reconstruction and classification tasks. Our bounds underscore the importance of capturing both consensus and complementary information from multiple different views to achieve maximally disentangled representations. These results also indicate that applying the multi-view information bottleneck regularizer is beneficial for satisfactory generalization performance. Additionally, we derive novel data-dependent bounds under both leave-one-out and supersample settings, yielding computational tractable and tighter bounds. In the interpolating regime, we further establish the fast-rate bound for multi-view learning, exhibiting a faster convergence rate compared to conventional square-root bounds. Numerical results indicate a strong correlation between the true generalization gap and the derived bounds across various learning scenarios.
Towards Sharper Information-theoretic Generalization Bounds for Meta-Learning
Jan 26, 2025
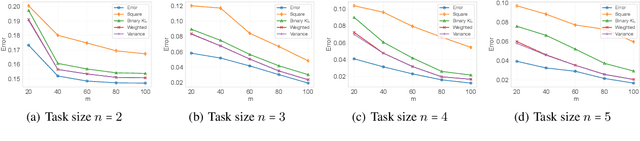

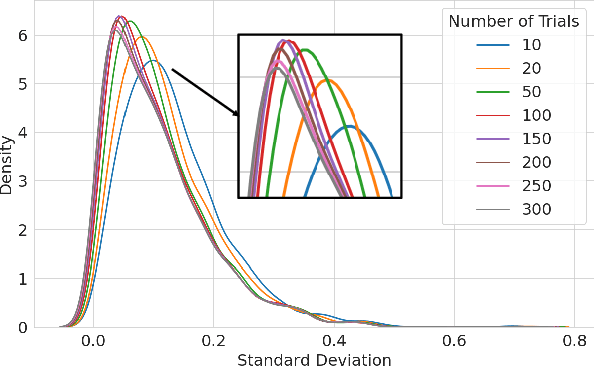
In recent years, information-theoretic generalization bounds have emerged as a promising approach for analyzing the generalization capabilities of meta-learning algorithms. However, existing results are confined to two-step bounds, failing to provide a sharper characterization of the meta-generalization gap that simultaneously accounts for environment-level and task-level dependencies. This paper addresses this fundamental limitation by establishing novel single-step information-theoretic bounds for meta-learning. Our bounds exhibit substantial advantages over prior MI- and CMI-based bounds, especially in terms of tightness, scaling behavior associated with sampled tasks and samples per task, and computational tractability. Furthermore, we provide novel theoretical insights into the generalization behavior of two classes of noise and iterative meta-learning algorithms via gradient covariance analysis, where the meta-learner uses either the entire meta-training data (e.g., Reptile), or separate training and test data within the task (e.g., model agnostic meta-learning (MAML)). Numerical results validate the effectiveness of the derived bounds in capturing the generalization dynamics of meta-learning.
An Ensemble Approach to Short-form Video Quality Assessment Using Multimodal LLM
Dec 24, 2024
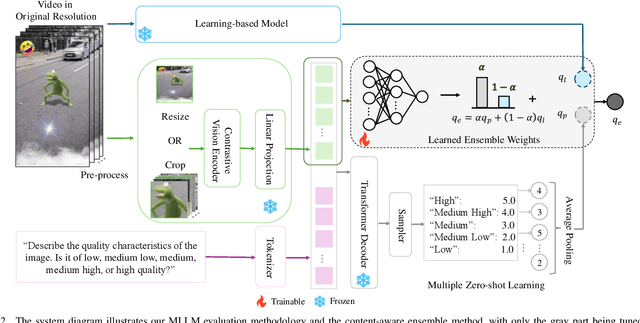

The rise of short-form videos, characterized by diverse content, editing styles, and artifacts, poses substantial challenges for learning-based blind video quality assessment (BVQA) models. Multimodal large language models (MLLMs), renowned for their superior generalization capabilities, present a promising solution. This paper focuses on effectively leveraging a pretrained MLLM for short-form video quality assessment, regarding the impacts of pre-processing and response variability, and insights on combining the MLLM with BVQA models. We first investigated how frame pre-processing and sampling techniques influence the MLLM's performance. Then, we introduced a lightweight learning-based ensemble method that adaptively integrates predictions from the MLLM and state-of-the-art BVQA models. Our results demonstrated superior generalization performance with the proposed ensemble approach. Furthermore, the analysis of content-aware ensemble weights highlighted that some video characteristics are not fully represented by existing BVQA models, revealing potential directions to improve BVQA models further.
Neural Directed Speech Enhancement with Dual Microphone Array in High Noise Scenario
Dec 24, 2024



In multi-speaker scenarios, leveraging spatial features is essential for enhancing target speech. While with limited microphone arrays, developing a compact multi-channel speech enhancement system remains challenging, especially in extremely low signal-to-noise ratio (SNR) conditions. To tackle this issue, we propose a triple-steering spatial selection method, a flexible framework that uses three steering vectors to guide enhancement and determine the enhancement range. Specifically, we introduce a causal-directed U-Net (CDUNet) model, which takes raw multi-channel speech and the desired enhancement width as inputs. This enables dynamic adjustment of steering vectors based on the target direction and fine-tuning of the enhancement region according to the angular separation between the target and interference signals. Our model with only a dual microphone array, excels in both speech quality and downstream task performance. It operates in real-time with minimal parameters, making it ideal for low-latency, on-device streaming applications.
Role Play: Learning Adaptive Role-Specific Strategies in Multi-Agent Interactions
Nov 02, 2024Zero-shot coordination problem in multi-agent reinforcement learning (MARL), which requires agents to adapt to unseen agents, has attracted increasing attention. Traditional approaches often rely on the Self-Play (SP) framework to generate a diverse set of policies in a policy pool, which serves to improve the generalization capability of the final agent. However, these frameworks may struggle to capture the full spectrum of potential strategies, especially in real-world scenarios that demand agents balance cooperation with competition. In such settings, agents need strategies that can adapt to varying and often conflicting goals. Drawing inspiration from Social Value Orientation (SVO)-where individuals maintain stable value orientations during interactions with others-we propose a novel framework called \emph{Role Play} (RP). RP employs role embeddings to transform the challenge of policy diversity into a more manageable diversity of roles. It trains a common policy with role embedding observations and employs a role predictor to estimate the joint role embeddings of other agents, helping the learning agent adapt to its assigned role. We theoretically prove that an approximate optimal policy can be achieved by optimizing the expected cumulative reward relative to an approximate role-based policy. Experimental results in both cooperative (Overcooked) and mixed-motive games (Harvest, CleanUp) reveal that RP consistently outperforms strong baselines when interacting with unseen agents, highlighting its robustness and adaptability in complex environments.
The Impact of Generative AI on Collaborative Open-Source Software Development: Evidence from GitHub Copilot
Oct 02, 2024
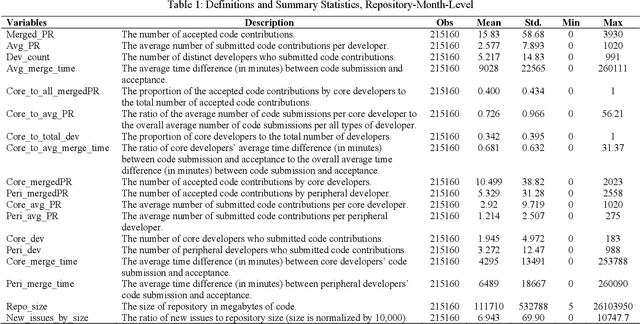
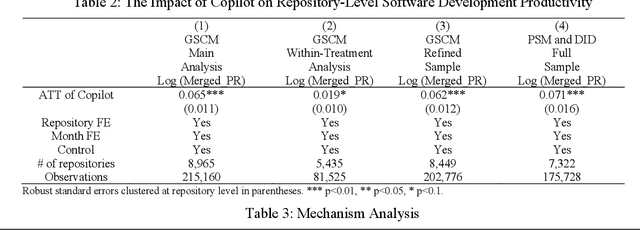

Generative artificial intelligence (AI) has opened the possibility of automated content production, including coding in software development, which can significantly influence the participation and performance of software developers. To explore this impact, we investigate the role of GitHub Copilot, a generative AI pair programmer, on software development in open-source community, where multiple developers voluntarily collaborate on software projects. Using GitHub's dataset for open-source repositories and a generalized synthetic control method, we find that Copilot significantly enhances project-level productivity by 6.5%. Delving deeper, we dissect the key mechanisms driving this improvement. Our findings reveal a 5.5% increase in individual productivity and a 5.4% increase in participation. However, this is accompanied with a 41.6% increase in integration time, potentially due to higher coordination costs. Interestingly, we also observe the differential effects among developers. We discover that core developers achieve greater project-level productivity gains from using Copilot, benefiting more in terms of individual productivity and participation compared to peripheral developers, plausibly due to their deeper familiarity with software projects. We also find that the increase in project-level productivity is accompanied with no change in code quality. We conclude that AI pair programmers bring benefits to developers to automate and augment their code, but human developers' knowledge of software projects can enhance the benefits. In summary, our research underscores the role of AI pair programmers in impacting project-level productivity within the open-source community and suggests potential implications for the structure of open-source software projects.