 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhi-3 Safety Post-Training: Aligning Language Models with a "Break-Fix" Cycle
Paper and Code
Jul 18, 2024


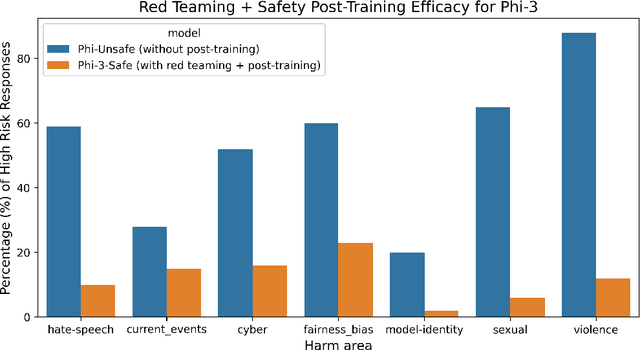
Recent innovations in language model training have demonstrated that it is possible to create highly performant models that are small enough to run on a smartphone. As these models are deployed in an increasing number of domains, it is critical to ensure that they are aligned with human preferences and safety considerations. In this report, we present our methodology for safety aligning the Phi-3 series of language models. We utilized a "break-fix" cycle, performing multiple rounds of dataset curation, safety post-training, benchmarking, red teaming, and vulnerability identification to cover a variety of harm areas in both single and multi-turn scenarios. Our results indicate that this approach iteratively improved the performance of the Phi-3 models across a wide range of responsible AI benchmarks.