 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCP-LLM: Context and Pixel Aware Large Language Model for Video Quality Assessment
May 21, 2025Video quality assessment (VQA) is a challenging research topic with broad applications. Effective VQA necessitates sensitivity to pixel-level distortions and a comprehensive understanding of video context to accurately determine the perceptual impact of distortions. Traditional hand-crafted and learning-based VQA models mainly focus on pixel-level distortions and lack contextual understanding, while recent LLM-based models struggle with sensitivity to small distortions or handle quality scoring and description as separate tasks. To address these shortcomings, we introduce CP-LLM: a Context and Pixel aware Large Language Model. CP-LLM is a novel multimodal LLM architecture featuring dual vision encoders designed to independently analyze perceptual quality at both high-level (video context) and low-level (pixel distortion) granularity, along with a language decoder subsequently reasons about the interplay between these aspects. This design enables CP-LLM to simultaneously produce robust quality scores and interpretable quality descriptions, with enhanced sensitivity to pixel distortions (e.g. compression artifacts). The model is trained via a multi-task pipeline optimizing for score prediction, description generation, and pairwise comparisons. Experiment results demonstrate that CP-LLM achieves state-of-the-art cross-dataset performance on established VQA benchmarks and superior robustness to pixel distortions, confirming its efficacy for comprehensive and practical video quality assessment in real-world scenarios.
Top in Chinese Data Processing: English Code Models
Jan 25, 2024
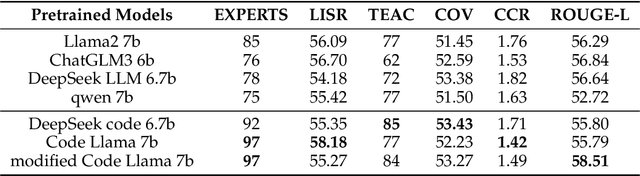
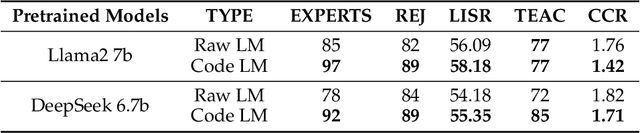
While the alignment between tasks and training corpora is a fundamental consensus in the application of language models, our series of experiments and the metrics we designed reveal that code-based Large Language Models (LLMs) significantly outperform models trained on data that is closely matched to the tasks in non-coding Chinese tasks. Moreover, in tasks high sensitivity to Chinese hallucinations, models exhibiting fewer linguistic features of the Chinese language achieve better performance. Our experimental results can be easily replicated in Chinese data processing tasks, such as preparing data for Retrieval-Augmented Generation (RAG), by simply replacing the base model with a code-based model. Additionally, our research offers a distinct perspective for discussion on the philosophical "Chinese Room" thought experiment.
Accelerated Gradient Flow: Risk, Stability, and Implicit Regularization
Jan 20, 2022


Acceleration and momentum are the de facto standard in modern applications of machine learning and optimization, yet the bulk of the work on implicit regularization focuses instead on unaccelerated methods. In this paper, we study the statistical risk of the iterates generated by Nesterov's accelerated gradient method and Polyak's heavy ball method, when applied to least squares regression, drawing several connections to explicit penalization. We carry out our analyses in continuous-time, allowing us to make sharper statements than in prior work, and revealing complex interactions between early stopping, stability, and the curvature of the loss function.
One-shot distributed ridge regression in high dimensions
Mar 22, 2019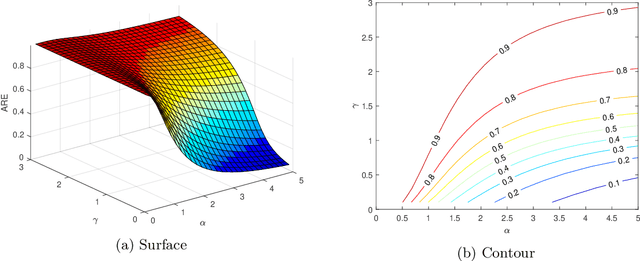
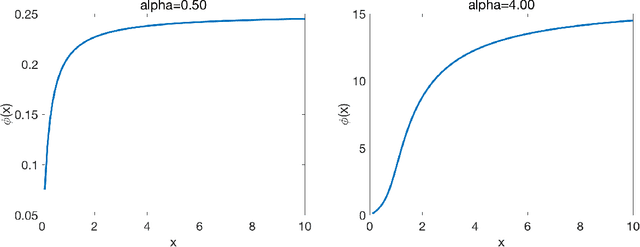
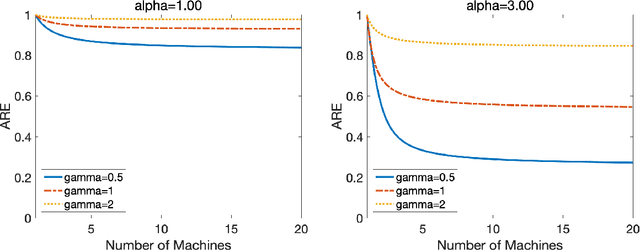
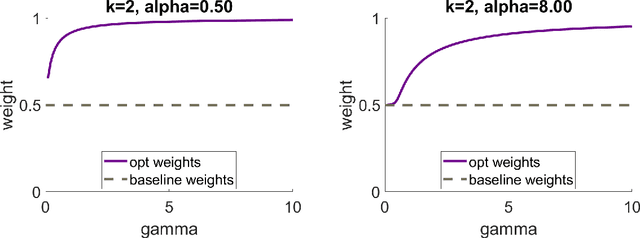
In many areas, practitioners need to analyze large datasets that challenge conventional single-machine computing. To scale up data analysis, distributed and parallel computing approaches are increasingly needed. Datasets are spread out over several computing units, which do most of the analysis locally, and communicate short messages. Here we study a fundamental and highly important problem in this area: How to do ridge regression in a distributed computing environment? Ridge regression is an extremely popular method for supervised learning, and has several optimality properties, thus it is important to study. We study one-shot methods that construct weighted combinations of ridge regression estimators computed on each machine. By analyzing the mean squared error in a high dimensional random-effects model where each predictor has a small effect, we discover several new phenomena. 1. Infinite-worker limit: The distributed estimator works well for very large numbers of machines, a phenomenon we call "infinite-worker limit". 2. Optimal weights: The optimal weights for combining local estimators sum to more than unity, due to the downward bias of ridge. Thus, all averaging methods are suboptimal. We also propose a new optimally weighted one-shot ridge regression algorithm. We confirm our results in simulation studies and using the Million Song Dataset as an example. There we can save at least 100x in computation time, while nearly preserving test accuracy.
Distributed linear regression by averaging
Sep 30, 2018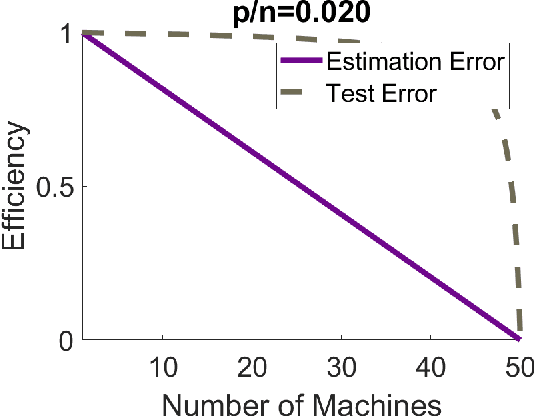
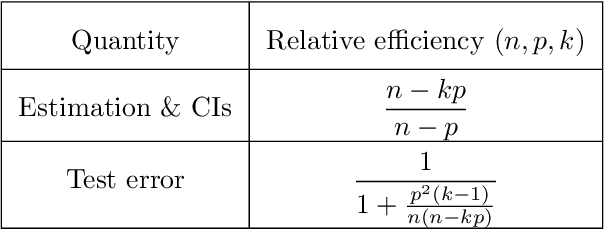
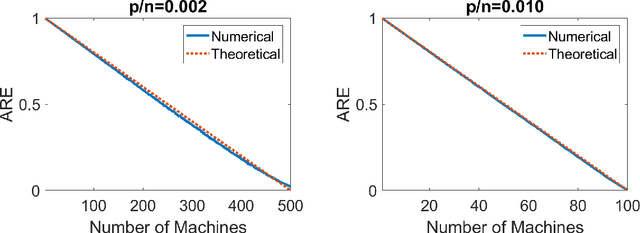

Modern massive datasets pose an enormous computational burden to practitioners. Distributed computation has emerged as a universal approach to ease the burden: Datasets are partitioned over machines, which compute locally, and communicate short messages. Distributed data also arises due to privacy reasons, such as in medicine. It is important to study how to do statistical inference and machine learning in a distributed setting. In this paper, we study one-step parameter averaging in statistical linear models under data parallelism. We do linear regression on each machine, and take a weighted average of the parameters. How much do we lose compared to doing linear regression on the full data? Here we study the performance loss in estimation error, test error, and confidence interval length in high dimensions, where the number of parameters is comparable to the training data size. We discover several key phenomena. First, averaging is not optimal, and we find the exact performance loss. Our results are simple to use in practice. Second, different problems are affected differently by the distributed framework. Estimation error and confidence interval length increases a lot, while prediction error increases much less. These results match simulations and a data analysis example. We rely on recent results from random matrix theory, where we develop a new calculus of deterministic equivalents as a tool of broader interest.