 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoal-Oriented Sequential Bayesian Experimental Design for Causal Learning
Jul 10, 2025



We present GO-CBED, a goal-oriented Bayesian framework for sequential causal experimental design. Unlike conventional approaches that select interventions aimed at inferring the full causal model, GO-CBED directly maximizes the expected information gain (EIG) on user-specified causal quantities of interest, enabling more targeted and efficient experimentation. The framework is both non-myopic, optimizing over entire intervention sequences, and goal-oriented, targeting only model aspects relevant to the causal query. To address the intractability of exact EIG computation, we introduce a variational lower bound estimator, optimized jointly through a transformer-based policy network and normalizing flow-based variational posteriors. The resulting policy enables real-time decision-making via an amortized network. We demonstrate that GO-CBED consistently outperforms existing baselines across various causal reasoning and discovery tasks-including synthetic structural causal models and semi-synthetic gene regulatory networks-particularly in settings with limited experimental budgets and complex causal mechanisms. Our results highlight the benefits of aligning experimental design objectives with specific research goals and of forward-looking sequential planning.
Top in Chinese Data Processing: English Code Models
Jan 25, 2024
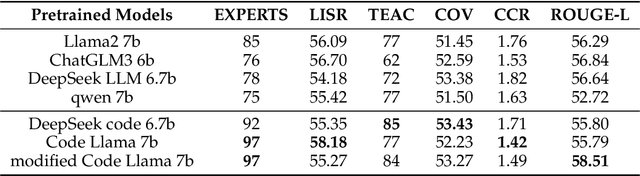
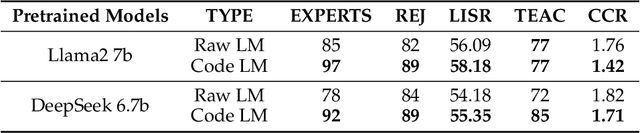
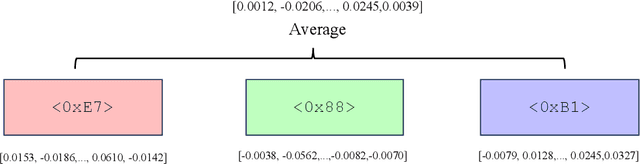
While the alignment between tasks and training corpora is a fundamental consensus in the application of language models, our series of experiments and the metrics we designed reveal that code-based Large Language Models (LLMs) significantly outperform models trained on data that is closely matched to the tasks in non-coding Chinese tasks. Moreover, in tasks high sensitivity to Chinese hallucinations, models exhibiting fewer linguistic features of the Chinese language achieve better performance. Our experimental results can be easily replicated in Chinese data processing tasks, such as preparing data for Retrieval-Augmented Generation (RAG), by simply replacing the base model with a code-based model. Additionally, our research offers a distinct perspective for discussion on the philosophical "Chinese Room" thought experiment.
Enhancing Dynamical System Modeling through Interpretable Machine Learning Augmentations: A Case Study in Cathodic Electrophoretic Deposition
Jan 16, 2024We introduce a comprehensive data-driven framework aimed at enhancing the modeling of physical systems, employing inference techniques and machine learning enhancements. As a demonstrative application, we pursue the modeling of cathodic electrophoretic deposition (EPD), commonly known as e-coating. Our approach illustrates a systematic procedure for enhancing physical models by identifying their limitations through inference on experimental data and introducing adaptable model enhancements to address these shortcomings. We begin by tackling the issue of model parameter identifiability, which reveals aspects of the model that require improvement. To address generalizability , we introduce modifications which also enhance identifiability. However, these modifications do not fully capture essential experimental behaviors. To overcome this limitation, we incorporate interpretable yet flexible augmentations into the baseline model. These augmentations are parameterized by simple fully-connected neural networks (FNNs), and we leverage machine learning tools, particularly Neural Ordinary Differential Equations (Neural ODEs), to learn these augmentations. Our simulations demonstrate that the machine learning-augmented model more accurately captures observed behaviors and improves predictive accuracy. Nevertheless, we contend that while the model updates offer superior performance and capture the relevant physics, we can reduce off-line computational costs by eliminating certain dynamics without compromising accuracy or interpretability in downstream predictions of quantities of interest, particularly film thickness predictions. The entire process outlined here provides a structured approach to leverage data-driven methods. Firstly, it helps us comprehend the root causes of model inaccuracies, and secondly, it offers a principled method for enhancing model performance.
Variational Sequential Optimal Experimental Design using Reinforcement Learning
Jun 17, 2023



We introduce variational sequential Optimal Experimental Design (vsOED), a new method for optimally designing a finite sequence of experiments under a Bayesian framework and with information-gain utilities. Specifically, we adopt a lower bound estimator for the expected utility through variational approximation to the Bayesian posteriors. The optimal design policy is solved numerically by simultaneously maximizing the variational lower bound and performing policy gradient updates. We demonstrate this general methodology for a range of OED problems targeting parameter inference, model discrimination, and goal-oriented prediction. These cases encompass explicit and implicit likelihoods, nuisance parameters, and physics-based partial differential equation models. Our vsOED results indicate substantially improved sample efficiency and reduced number of forward model simulations compared to previous sequential design algorithms.