 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTop in Chinese Data Processing: English Code Models
Jan 25, 2024
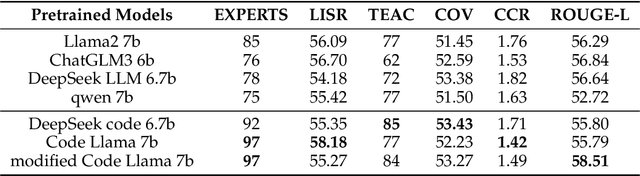
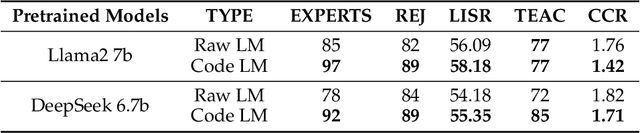
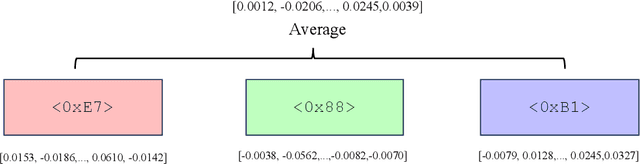
While the alignment between tasks and training corpora is a fundamental consensus in the application of language models, our series of experiments and the metrics we designed reveal that code-based Large Language Models (LLMs) significantly outperform models trained on data that is closely matched to the tasks in non-coding Chinese tasks. Moreover, in tasks high sensitivity to Chinese hallucinations, models exhibiting fewer linguistic features of the Chinese language achieve better performance. Our experimental results can be easily replicated in Chinese data processing tasks, such as preparing data for Retrieval-Augmented Generation (RAG), by simply replacing the base model with a code-based model. Additionally, our research offers a distinct perspective for discussion on the philosophical "Chinese Room" thought experiment.