 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Interpretability for Vision Models via Shapley Value Optimization
Dec 16, 2025Deep neural networks have demonstrated remarkable performance across various domains, yet their decision-making processes remain opaque. Although many explanation methods are dedicated to bringing the obscurity of DNNs to light, they exhibit significant limitations: post-hoc explanation methods often struggle to faithfully reflect model behaviors, while self-explaining neural networks sacrifice performance and compatibility due to their specialized architectural designs. To address these challenges, we propose a novel self-explaining framework that integrates Shapley value estimation as an auxiliary task during training, which achieves two key advancements: 1) a fair allocation of the model prediction scores to image patches, ensuring explanations inherently align with the model's decision logic, and 2) enhanced interpretability with minor structural modifications, preserving model performance and compatibility. Extensive experiments on multiple benchmarks demonstrate that our method achieves state-of-the-art interpretability.
Learned Scanpaths Aid Blind Panoramic Video Quality Assessment
Mar 30, 2024Panoramic videos have the advantage of providing an immersive and interactive viewing experience. Nevertheless, their spherical nature gives rise to various and uncertain user viewing behaviors, which poses significant challenges for panoramic video quality assessment (PVQA). In this work, we propose an end-to-end optimized, blind PVQA method with explicit modeling of user viewing patterns through visual scanpaths. Our method consists of two modules: a scanpath generator and a quality assessor. The scanpath generator is initially trained to predict future scanpaths by minimizing their expected code length and then jointly optimized with the quality assessor for quality prediction. Our blind PVQA method enables direct quality assessment of panoramic images by treating them as videos composed of identical frames. Experiments on three public panoramic image and video quality datasets, encompassing both synthetic and authentic distortions, validate the superiority of our blind PVQA model over existing methods.
Scanpath Prediction in Panoramic Videos via Expected Code Length Minimization
May 05, 2023

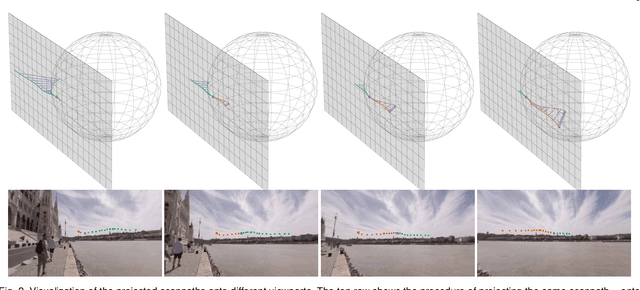

Predicting human scanpaths when exploring panoramic videos is a challenging task due to the spherical geometry and the multimodality of the input, and the inherent uncertainty and diversity of the output. Most previous methods fail to give a complete treatment of these characteristics, and thus are prone to errors. In this paper, we present a simple new criterion for scanpath prediction based on principles from lossy data compression. This criterion suggests minimizing the expected code length of quantized scanpaths in a training set, which corresponds to fitting a discrete conditional probability model via maximum likelihood. Specifically, the probability model is conditioned on two modalities: a viewport sequence as the deformation-reduced visual input and a set of relative historical scanpaths projected onto respective viewports as the aligned path input. The probability model is parameterized by a product of discretized Gaussian mixture models to capture the uncertainty and the diversity of scanpaths from different users. Most importantly, the training of the probability model does not rely on the specification of "ground-truth" scanpaths for imitation learning. We also introduce a proportional-integral-derivative (PID) controller-based sampler to generate realistic human-like scanpaths from the learned probability model. Experimental results demonstrate that our method consistently produces better quantitative scanpath results in terms of prediction accuracy (by comparing to the assumed "ground-truths") and perceptual realism (through machine discrimination) over a wide range of prediction horizons. We additionally verify the perceptual realism improvement via a formal psychophysical experiment and the generalization improvement on several unseen panoramic video datasets.