 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScanpath Prediction in Panoramic Videos via Expected Code Length Minimization
Paper and Code


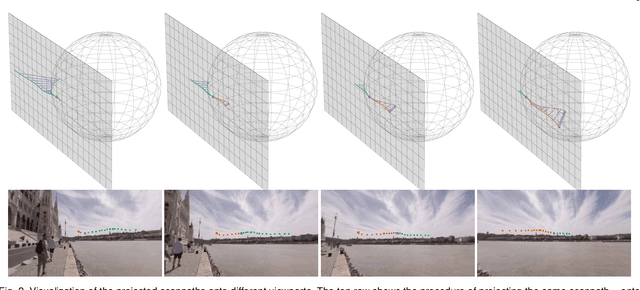

Predicting human scanpaths when exploring panoramic videos is a challenging task due to the spherical geometry and the multimodality of the input, and the inherent uncertainty and diversity of the output. Most previous methods fail to give a complete treatment of these characteristics, and thus are prone to errors. In this paper, we present a simple new criterion for scanpath prediction based on principles from lossy data compression. This criterion suggests minimizing the expected code length of quantized scanpaths in a training set, which corresponds to fitting a discrete conditional probability model via maximum likelihood. Specifically, the probability model is conditioned on two modalities: a viewport sequence as the deformation-reduced visual input and a set of relative historical scanpaths projected onto respective viewports as the aligned path input. The probability model is parameterized by a product of discretized Gaussian mixture models to capture the uncertainty and the diversity of scanpaths from different users. Most importantly, the training of the probability model does not rely on the specification of "ground-truth" scanpaths for imitation learning. We also introduce a proportional-integral-derivative (PID) controller-based sampler to generate realistic human-like scanpaths from the learned probability model. Experimental results demonstrate that our method consistently produces better quantitative scanpath results in terms of prediction accuracy (by comparing to the assumed "ground-truths") and perceptual realism (through machine discrimination) over a wide range of prediction horizons. We additionally verify the perceptual realism improvement via a formal psychophysical experiment and the generalization improvement on several unseen panoramic video datasets.