 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Speech Large Language Models
Oct 24, 2024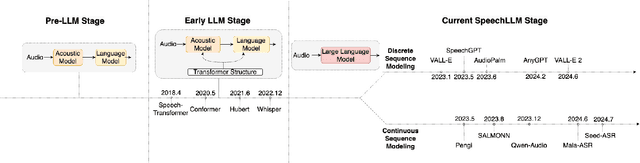
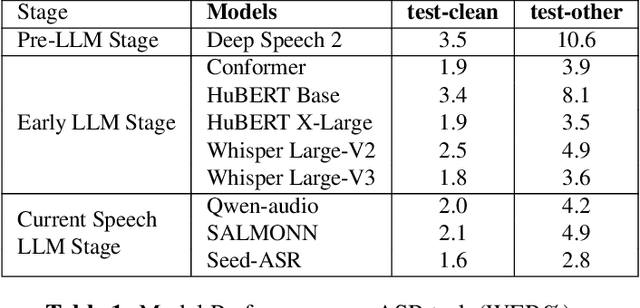
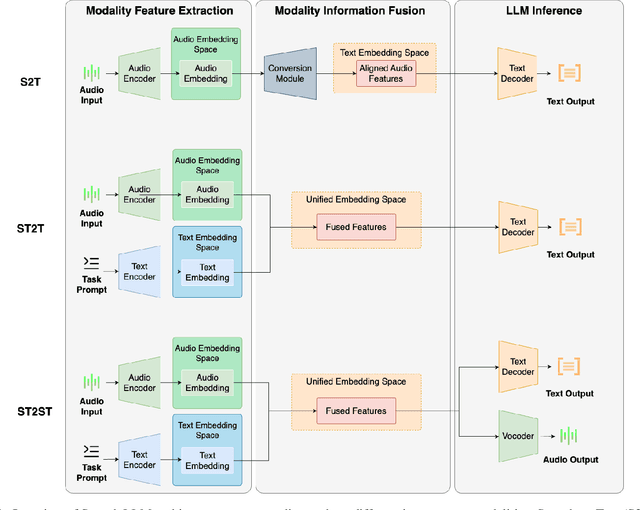
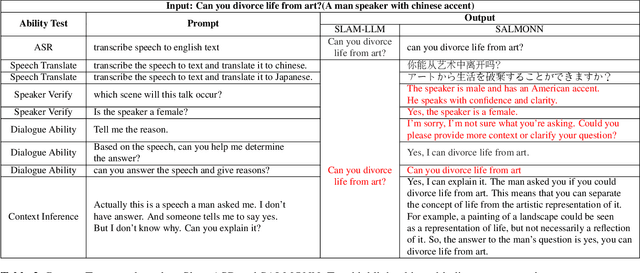
Large Language Models (LLMs) exhibit strong contextual understanding and remarkable multi-task performance. Therefore, researchers have been seeking to integrate LLMs in the broad sense of Spoken Language Understanding (SLU) field. Different from the traditional method of cascading LLMs to process text generated by Automatic Speech Recognition(ASR), new efforts have focused on designing architectures centered around Audio Feature Extraction - Multimodal Information Fusion - LLM Inference(Speech LLMs). This approach enables richer audio feature extraction while simultaneously facilitating end-to-end fusion of audio and text modalities, thereby achieving deeper understanding and reasoning from audio data. This paper elucidates the development of Speech LLMs, offering an in-depth analysis of system architectures and training strategies. Through extensive research and a series of targeted experiments, the paper assesses Speech LLMs' advancements in Rich Audio Transcription and its potential for Cross-task Integration within the SLU field. Additionally, it indicates key challenges uncovered through experimentation, such as the Dormancy of LLMs under certain conditions. The paper further delves into the training strategies for Speech LLMs, proposing potential solutions based on these findings, and offering valuable insights and references for future research in this domain, as well as LLM applications in multimodal contexts.