 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetect, Attend and Extract: Keyword Guided Target Speaker Extraction
Feb 08, 2026Target speaker extraction (TSE) aims to extract the speech of a target speaker from mixtures containing multiple competing speakers. Conventional TSE systems predominantly rely on speaker cues, such as pre-enrolled speech, to identify and isolate the target speaker. However, in many practical scenarios, clean enrollment utterances are unavailable, limiting the applicability of existing approaches. In this work, we propose DAE-TSE, a keyword-guided TSE framework that specifies the target speaker through distinct keywords they utter. By leveraging keywords (i.e., partial transcriptions) as cues, our approach provides a flexible and practical alternative to enrollment-based TSE. DAE-TSE follows the Detect-Attend-Extract (DAE) paradigm: it first detects the presence of the given keywords, then attends to the corresponding speaker based on the keyword content, and finally extracts the target speech. Experimental results demonstrate that DAE-TSE outperforms standard TSE systems that rely on clean enrollment speech. To the best of our knowledge, this is the first study to utilize partial transcription as a cue for specifying the target speaker in TSE, offering a flexible and practical solution for real-world scenarios. Our code and demo page are now publicly available.
Interpolating Speaker Identities in Embedding Space for Data Expansion
Aug 26, 2025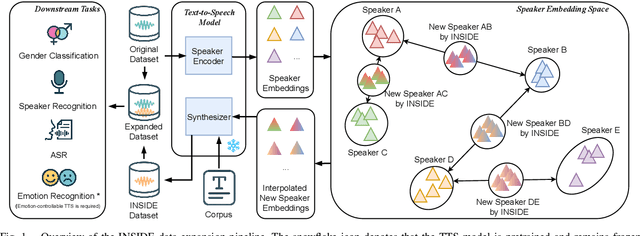
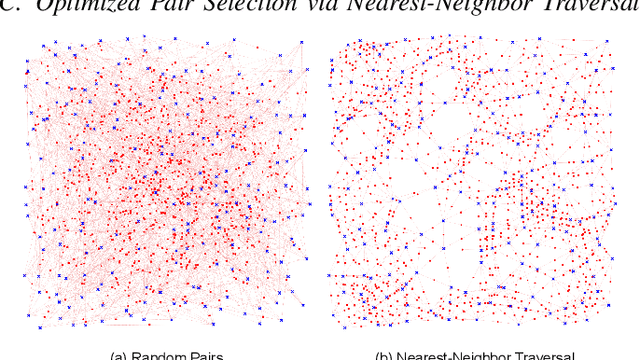
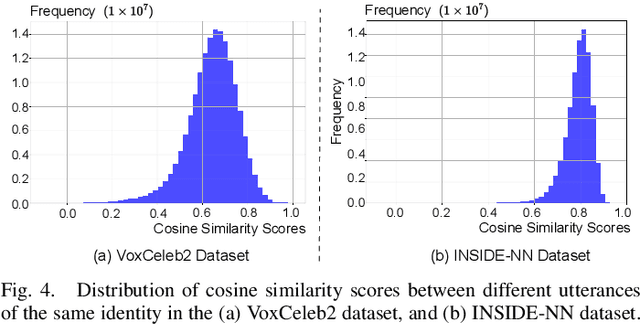
The success of deep learning-based speaker verification systems is largely attributed to access to large-scale and diverse speaker identity data. However, collecting data from more identities is expensive, challenging, and often limited by privacy concerns. To address this limitation, we propose INSIDE (Interpolating Speaker Identities in Embedding Space), a novel data expansion method that synthesizes new speaker identities by interpolating between existing speaker embeddings. Specifically, we select pairs of nearby speaker embeddings from a pretrained speaker embedding space and compute intermediate embeddings using spherical linear interpolation. These interpolated embeddings are then fed to a text-to-speech system to generate corresponding speech waveforms. The resulting data is combined with the original dataset to train downstream models. Experiments show that models trained with INSIDE-expanded data outperform those trained only on real data, achieving 3.06\% to 5.24\% relative improvements. While INSIDE is primarily designed for speaker verification, we also validate its effectiveness on gender classification, where it yields a 13.44\% relative improvement. Moreover, INSIDE is compatible with other augmentation techniques and can serve as a flexible, scalable addition to existing training pipelines.
MFA-KWS: Effective Keyword Spotting with Multi-head Frame-asynchronous Decoding
May 26, 2025Keyword spotting (KWS) is essential for voice-driven applications, demanding both accuracy and efficiency. Traditional ASR-based KWS methods, such as greedy and beam search, explore the entire search space without explicitly prioritizing keyword detection, often leading to suboptimal performance. In this paper, we propose an effective keyword-specific KWS framework by introducing a streaming-oriented CTC-Transducer-combined frame-asynchronous system with multi-head frame-asynchronous decoding (MFA-KWS). Specifically, MFA-KWS employs keyword-specific phone-synchronous decoding for CTC and replaces conventional RNN-T with Token-and-Duration Transducer to enhance both performance and efficiency. Furthermore, we explore various score fusion strategies, including single-frame-based and consistency-based methods. Extensive experiments demonstrate the superior performance of MFA-KWS, which achieves state-of-the-art results on both fixed keyword and arbitrary keywords datasets, such as Snips, MobvoiHotwords, and LibriKWS-20, while exhibiting strong robustness in noisy environments. Among fusion strategies, the consistency-based CDC-Last method delivers the best performance. Additionally, MFA-KWS achieves a 47% to 63% speed-up over the frame-synchronous baselines across various datasets. Extensive experimental results confirm that MFA-KWS is an effective and efficient KWS framework, making it well-suited for on-device deployment.
UniCodec: Unified Audio Codec with Single Domain-Adaptive Codebook
Feb 27, 2025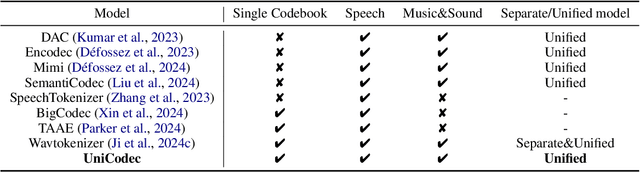

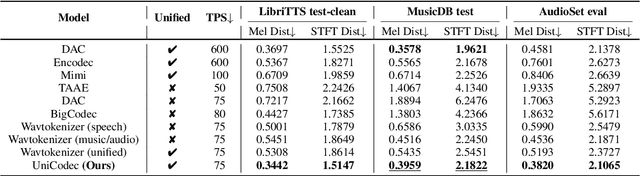
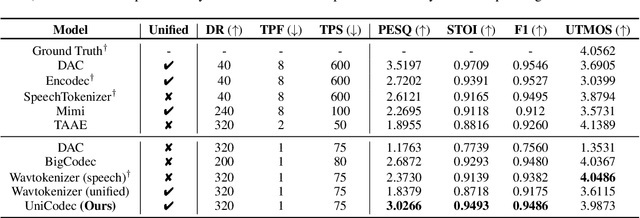
The emergence of audio language models is empowered by neural audio codecs, which establish critical mappings between continuous waveforms and discrete tokens compatible with language model paradigms. The evolutionary trends from multi-layer residual vector quantizer to single-layer quantizer are beneficial for language-autoregressive decoding. However, the capability to handle multi-domain audio signals through a single codebook remains constrained by inter-domain distribution discrepancies. In this work, we introduce UniCodec, a unified audio codec with a single codebook to support multi-domain audio data, including speech, music, and sound. To achieve this, we propose a partitioned domain-adaptive codebook method and domain Mixture-of-Experts strategy to capture the distinct characteristics of each audio domain. Furthermore, to enrich the semantic density of the codec without auxiliary modules, we propose a self-supervised mask prediction modeling approach. Comprehensive objective and subjective evaluations demonstrate that UniCodec achieves excellent audio reconstruction performance across the three audio domains, outperforming existing unified neural codecs with a single codebook, and even surpasses state-of-the-art domain-specific codecs on both acoustic and semantic representation capabilities.
Streaming Keyword Spotting Boosted by Cross-layer Discrimination Consistency
Dec 17, 2024



Connectionist Temporal Classification (CTC), a non-autoregressive training criterion, is widely used in online keyword spotting (KWS). However, existing CTC-based KWS decoding strategies either rely on Automatic Speech Recognition (ASR), which performs suboptimally due to its broad search over the acoustic space without keyword-specific optimization, or on KWS-specific decoding graphs, which are complex to implement and maintain. In this work, we propose a streaming decoding algorithm enhanced by Cross-layer Discrimination Consistency (CDC), tailored for CTC-based KWS. Specifically, we introduce a streamlined yet effective decoding algorithm capable of detecting the start of the keyword at any arbitrary position. Furthermore, we leverage discrimination consistency information across layers to better differentiate between positive and false alarm samples. Our experiments on both clean and noisy Hey Snips datasets show that the proposed streaming decoding strategy outperforms ASR-based and graph-based KWS baselines. The CDC-boosted decoding further improves performance, yielding an average absolute recall improvement of 6.8% and a 46.3% relative reduction in the miss rate compared to the graph-based KWS baseline, with a very low false alarm rate of 0.05 per hour.
WavChat: A Survey of Spoken Dialogue Models
Nov 26, 2024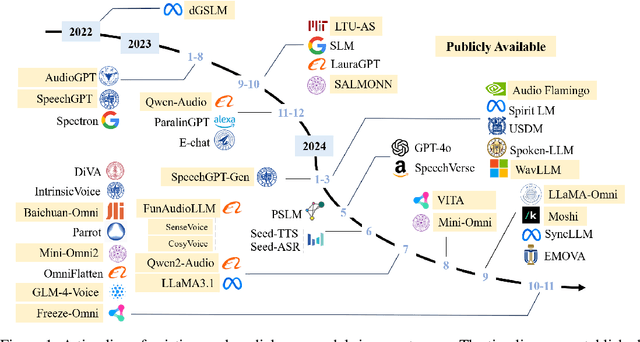

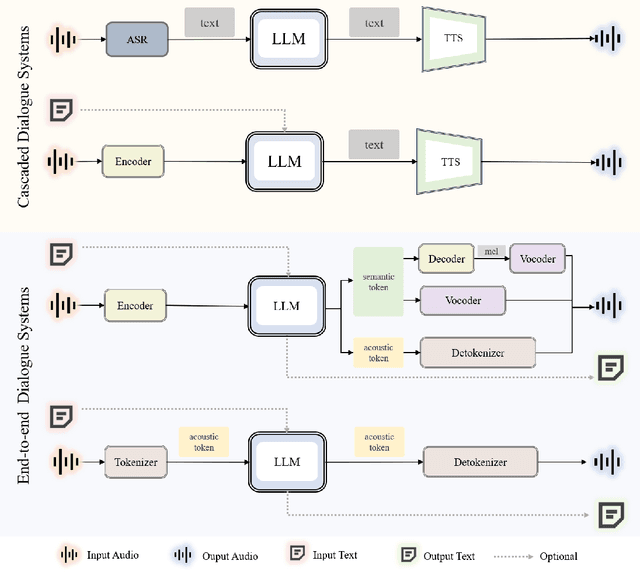
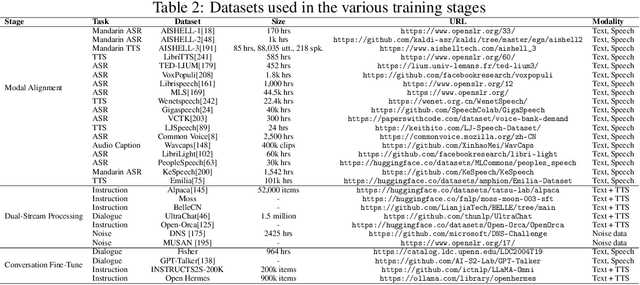
Recent advancements in spoken dialogue models, exemplified by systems like GPT-4o, have captured significant attention in the speech domain. Compared to traditional three-tier cascaded spoken dialogue models that comprise speech recognition (ASR), large language models (LLMs), and text-to-speech (TTS), modern spoken dialogue models exhibit greater intelligence. These advanced spoken dialogue models not only comprehend audio, music, and other speech-related features, but also capture stylistic and timbral characteristics in speech. Moreover, they generate high-quality, multi-turn speech responses with low latency, enabling real-time interaction through simultaneous listening and speaking capability. Despite the progress in spoken dialogue systems, there is a lack of comprehensive surveys that systematically organize and analyze these systems and the underlying technologies. To address this, we have first compiled existing spoken dialogue systems in the chronological order and categorized them into the cascaded and end-to-end paradigms. We then provide an in-depth overview of the core technologies in spoken dialogue models, covering aspects such as speech representation, training paradigm, streaming, duplex, and interaction capabilities. Each section discusses the limitations of these technologies and outlines considerations for future research. Additionally, we present a thorough review of relevant datasets, evaluation metrics, and benchmarks from the perspectives of training and evaluating spoken dialogue systems. We hope this survey will contribute to advancing both academic research and industrial applications in the field of spoken dialogue systems. The related material is available at https://github.com/jishengpeng/WavChat.
Unified Audio Event Detection
Sep 13, 2024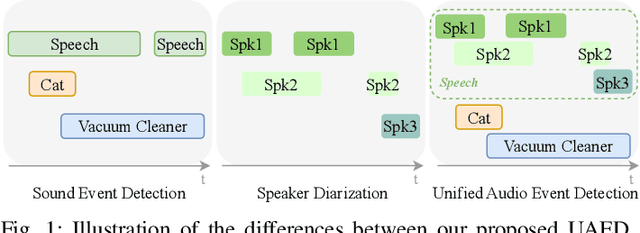
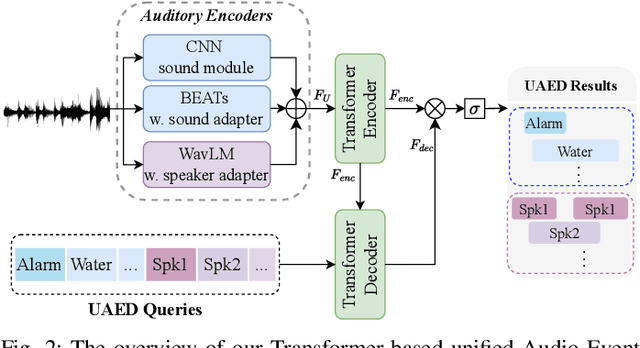
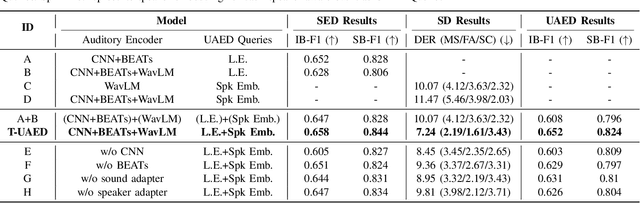
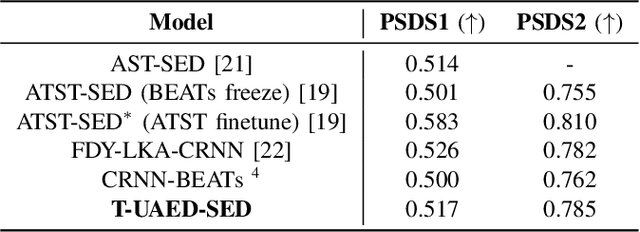
Sound Event Detection (SED) detects regions of sound events, while Speaker Diarization (SD) segments speech conversations attributed to individual speakers. In SED, all speaker segments are classified as a single speech event, while in SD, non-speech sounds are treated merely as background noise. Thus, both tasks provide only partial analysis in complex audio scenarios involving both speech conversation and non-speech sounds. In this paper, we introduce a novel task called Unified Audio Event Detection (UAED) for comprehensive audio analysis. UAED explores the synergy between SED and SD tasks, simultaneously detecting non-speech sound events and fine-grained speech events based on speaker identities. To tackle this task, we propose a Transformer-based UAED (T-UAED) framework and construct the UAED Data derived from the Librispeech dataset and DESED soundbank. Experiments demonstrate that the proposed framework effectively exploits task interactions and substantially outperforms the baseline that simply combines the outputs of SED and SD models. T-UAED also shows its versatility by performing comparably to specialized models for individual SED and SD tasks on DESED and CALLHOME datasets.
Flow-TSVAD: Target-Speaker Voice Activity Detection via Latent Flow Matching
Sep 07, 2024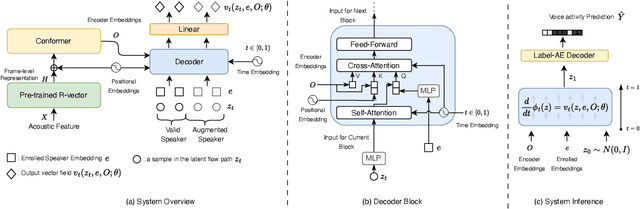

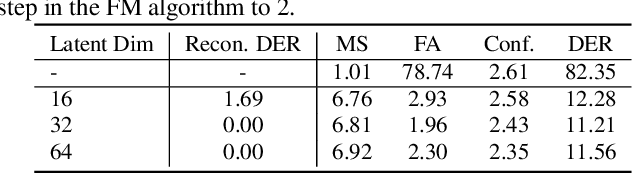
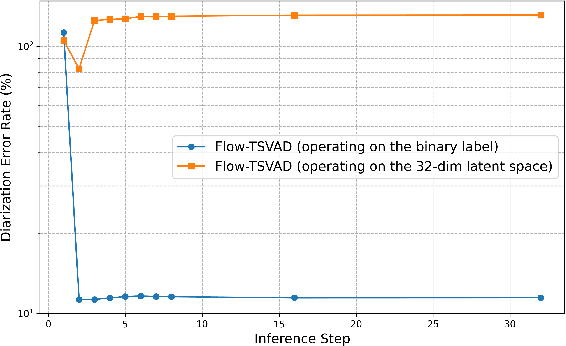
Speaker diarization is typically considered a discriminative task, using discriminative approaches to produce fixed diarization results. In this paper, we explore the use of neural network-based generative methods for speaker diarization for the first time. We implement a Flow-Matching (FM) based generative algorithm within the sequence-to-sequence target speaker voice activity detection (Seq2Seq-TSVAD) diarization system. Our experiments reveal that applying the generative method directly to the original binary label sequence space of the TS-VAD output is ineffective. To address this issue, we propose mapping the binary label sequence into a dense latent space before applying the generative algorithm and our proposed Flow-TSVAD method outperforms the Seq2Seq-TSVAD system. Additionally, we observe that the FM algorithm converges rapidly during the inference stage, requiring only two inference steps to achieve promising results. As a generative model, Flow-TSVAD allows for sampling different diarization results by running the model multiple times. Moreover, ensembling results from various sampling instances further enhances diarization performance.
WavTokenizer: an Efficient Acoustic Discrete Codec Tokenizer for Audio Language Modeling
Aug 29, 2024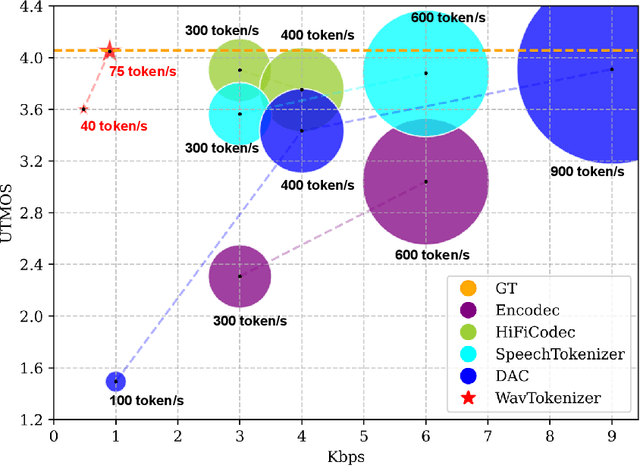
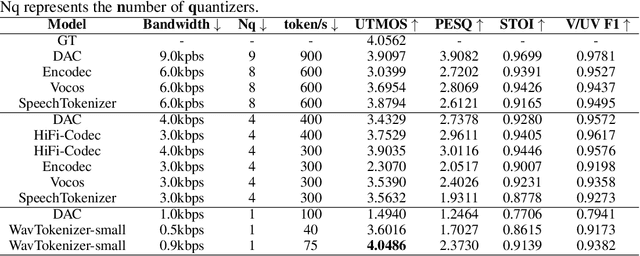
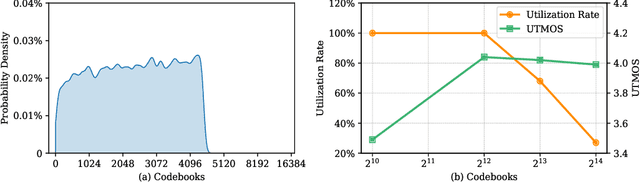
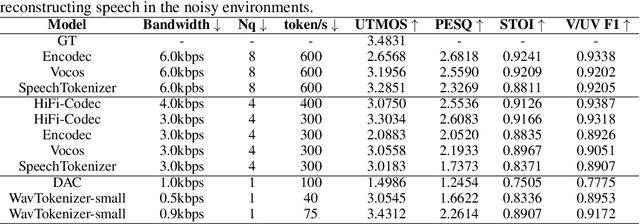
Language models have been effectively applied to modeling natural signals, such as images, video, speech, and audio. A crucial component of these models is the codec tokenizer, which compresses high-dimensional natural signals into lower-dimensional discrete tokens. In this paper, we introduce WavTokenizer, which offers several advantages over previous SOTA acoustic codec models in the audio domain: 1)extreme compression. By compressing the layers of quantizers and the temporal dimension of the discrete codec, one-second audio of 24kHz sampling rate requires only a single quantizer with 40 or 75 tokens. 2)improved subjective quality. Despite the reduced number of tokens, WavTokenizer achieves state-of-the-art reconstruction quality with outstanding UTMOS scores and inherently contains richer semantic information. Specifically, we achieve these results by designing a broader VQ space, extended contextual windows, and improved attention networks, as well as introducing a powerful multi-scale discriminator and an inverse Fourier transform structure. We conducted extensive reconstruction experiments in the domains of speech, audio, and music. WavTokenizer exhibited strong performance across various objective and subjective metrics compared to state-of-the-art models. We also tested semantic information, VQ utilization, and adaptability to generative models. Comprehensive ablation studies confirm the necessity of each module in WavTokenizer. The related code, demos, and pre-trained models are available at https://github.com/jishengpeng/WavTokenizer.
Multi-Stage Face-Voice Association Learning with Keynote Speaker Diarization
Jul 25, 2024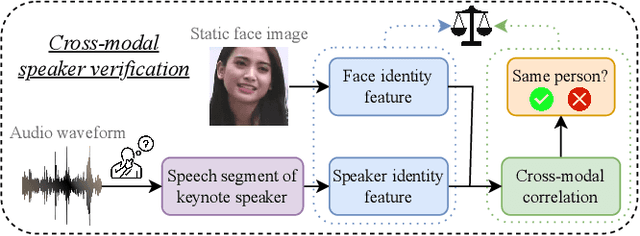
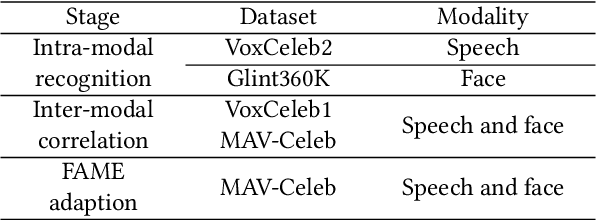
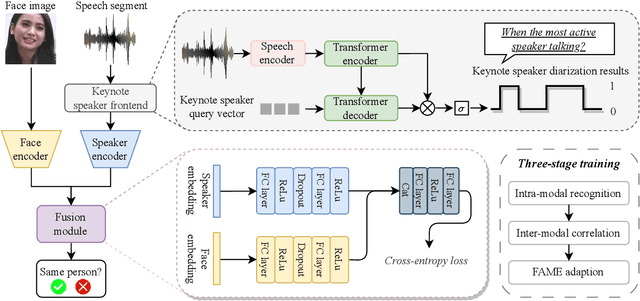

The human brain has the capability to associate the unknown person's voice and face by leveraging their general relationship, referred to as ``cross-modal speaker verification''. This task poses significant challenges due to the complex relationship between the modalities. In this paper, we propose a ``Multi-stage Face-voice Association Learning with Keynote Speaker Diarization''~(MFV-KSD) framework. MFV-KSD contains a keynote speaker diarization front-end to effectively address the noisy speech inputs issue. To balance and enhance the intra-modal feature learning and inter-modal correlation understanding, MFV-KSD utilizes a novel three-stage training strategy. Our experimental results demonstrated robust performance, achieving the first rank in the 2024 Face-voice Association in Multilingual Environments (FAME) challenge with an overall Equal Error Rate (EER) of 19.9%. Details can be found in https://github.com/TaoRuijie/MFV-KSD.