 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeListening Deepfake Detection: A New Perspective Beyond Speaking-Centric Forgery Analysis
Apr 14, 2026Existing deepfake detection research has primarily focused on scenarios where the manipulated subject is actively speaking, i.e., generating fabricated content by altering the speaker's appearance or voice. However, in realistic interaction settings, attackers often alternate between falsifying speaking and listening states to mislead their targets, thereby enhancing the realism and persuasiveness of the scenario. Although the detection of 'listening deepfakes' remains largely unexplored and is hindered by a scarcity of both datasets and methodologies, the relatively limited quality of synthesized listening reactions presents an excellent breakthrough opportunity for current deepfake detection efforts. In this paper, we present the task of Listening Deepfake Detection (LDD). We introduce ListenForge, the first dataset specifically designed for this task, constructed using five Listening Head Generation (LHG) methods. To address the distinctive characteristics of listening forgeries, we propose MANet, a Motion-aware and Audio-guided Network that captures subtle motion inconsistencies in listener videos while leveraging speaker's audio semantics to guide cross-modal fusion. Extensive experiments demonstrate that existing Speaking Deepfake Detection (SDD) models perform poorly in listening scenarios. In contrast, MANet achieves significantly superior performance on ListenForge. Our work highlights the necessity of rethinking deepfake detection beyond the traditional speaking-centric paradigm and opens new directions for multimodal forgery analysis in interactive communication settings. The dataset and code are available at https://anonymous.4open.science/r/LDD-B4CB.
EgoAdapt: Enhancing Robustness in Egocentric Interactive Speaker Detection Under Missing Modalities
Mar 18, 2026TTM (Talking to Me) task is a pivotal component in understanding human social interactions, aiming to determine who is engaged in conversation with the camera-wearer. Traditional models often face challenges in real-world scenarios due to missing visual data, neglecting the role of head orientation, and background noise. This study addresses these limitations by introducing EgoAdapt, an adaptive framework designed for robust egocentric "Talking to Me" speaker detection under missing modalities. Specifically, EgoAdapt incorporates three key modules: (1) a Visual Speaker Target Recognition (VSTR) module that captures head orientation as a non-verbal cue and lip movement as a verbal cue, allowing a comprehensive interpretation of both verbal and non-verbal signals to address TTM, setting it apart from tasks focused solely on detecting speaking status; (2) a Parallel Shared-weight Audio (PSA) encoder for enhanced audio feature extraction in noisy environments; and (3) a Visual Modality Missing Awareness (VMMA) module that estimates the presence or absence of each modality at each frame to adjust the system response dynamically.Comprehensive evaluations on the TTM benchmark of the Ego4D dataset demonstrate that EgoAdapt achieves a mean Average Precision (mAP) of 67.39% and an Accuracy (Acc) of 62.01%, significantly outperforming the state-of-the-art method by 4.96% in Accuracy and 1.56% in mAP.
Beyond Lips: Integrating Gesture and Lip Cues for Robust Audio-visual Speaker Extraction
Jan 27, 2026Most audio-visual speaker extraction methods rely on synchronized lip recording to isolate the speech of a target speaker from a multi-talker mixture. However, in natural human communication, co-speech gestures are also temporally aligned with speech, often emphasizing specific words or syllables. These gestures provide complementary visual cues that can be especially valuable when facial or lip regions are occluded or distant. In this work, we move beyond lip-centric approaches and propose SeLG, a model that integrates both lip and upper-body gesture information for robust speaker extraction. SeLG features a cross-attention-based fusion mechanism that enables each visual modality to query and selectively attend to relevant speech features in the mixture. To improve the alignment of gesture representations with speech dynamics, SeLG also employs a contrastive InfoNCE loss that encourages gesture embeddings to align more closely with corresponding lip embeddings, which are more strongly correlated with speech. Experimental results on the YGD dataset, containing TED talks, demonstrate that the proposed contrastive learning strategy significantly improves gesture-based speaker extraction, and that our proposed SeLG model, by effectively fusing lip and gesture cues with an attention mechanism and InfoNCE loss, achieves superior performance compared to baselines, across both complete and partial (i.e., missing-modality) conditions.
Analytic Incremental Learning For Sound Source Localization With Imbalance Rectification
Jan 26, 2026Sound source localization (SSL) demonstrates remarkable results in controlled settings but struggles in real-world deployment due to dual imbalance challenges: intra-task imbalance arising from long-tailed direction-of-arrival (DoA) distributions, and inter-task imbalance induced by cross-task skews and overlaps. These often lead to catastrophic forgetting, significantly degrading the localization accuracy. To mitigate these issues, we propose a unified framework with two key innovations. Specifically, we design a GCC-PHAT-based data augmentation (GDA) method that leverages peak characteristics to alleviate intra-task distribution skews. We also propose an Analytic dynamic imbalance rectifier (ADIR) with task-adaption regularization, which enables analytic updates that adapt to inter-task dynamics. On the SSLR benchmark, our proposal achieves state-of-the-art (SoTA) results of 89.0% accuracy, 5.3° mean absolute error, and 1.6 backward transfer, demonstrating robustness to evolving imbalances without exemplar storage.
PALM-Bench: A Comprehensive Benchmark for Personalized Audio-Language Models
Jan 07, 2026Large Audio-Language Models (LALMs) have demonstrated strong performance in audio understanding and generation. Yet, our extensive benchmarking reveals that their behavior is largely generic (e.g., summarizing spoken content) and fails to adequately support personalized question answering (e.g., summarizing what my best friend says). In contrast, human conditions their interpretation and decision-making on each individual's personal context. To bridge this gap, we formalize the task of Personalized LALMs (PALM) for recognizing personal concepts and reasoning within personal context. Moreover, we create the first benchmark (PALM-Bench) to foster the methodological advances in PALM and enable structured evaluation on several tasks across multi-speaker scenarios. Our extensive experiments on representative open-source LALMs, show that existing training-free prompting and supervised fine-tuning strategies, while yield improvements, remains limited in modeling personalized knowledge and transferring them across tasks robustly. Data and code will be released.
Region-Specific Audio Tagging for Spatial Sound
Sep 11, 2025Audio tagging aims to label sound events appearing in an audio recording. In this paper, we propose region-specific audio tagging, a new task which labels sound events in a given region for spatial audio recorded by a microphone array. The region can be specified as an angular space or a distance from the microphone. We first study the performance of different combinations of spectral, spatial, and position features. Then we extend state-of-the-art audio tagging systems such as pre-trained audio neural networks (PANNs) and audio spectrogram transformer (AST) to the proposed region-specific audio tagging task. Experimental results on both the simulated and the real datasets show the feasibility of the proposed task and the effectiveness of the proposed method. Further experiments show that incorporating the directional features is beneficial for omnidirectional tagging.
VP-SelDoA: Visual-prompted Selective DoA Estimation of Target Sound via Semantic-Spatial Matching
Jul 10, 2025Audio-visual sound source localization (AV-SSL) identifies the position of a sound source by exploiting the complementary strengths of auditory and visual signals. However, existing AV-SSL methods encounter three major challenges: 1) inability to selectively isolate the target sound source in multi-source scenarios, 2) misalignment between semantic visual features and spatial acoustic features, and 3) overreliance on paired audio-visual data. To overcome these limitations, we introduce Cross-Instance Audio-Visual Localization (CI-AVL), a novel task that leverages images from different instances of the same sound event category to localize target sound sources, thereby reducing dependence on paired data while enhancing generalization capabilities. Our proposed VP-SelDoA tackles this challenging task through a semantic-level modality fusion and employs a Frequency-Temporal ConMamba architecture to generate target-selective masks for sound isolation. We further develop a Semantic-Spatial Matching mechanism that aligns the heterogeneous semantic and spatial features via integrated cross- and self-attention mechanisms. To facilitate the CI-AVL research, we construct a large-scale dataset named VGG-SSL, comprising 13,981 spatial audio clips across 296 sound event categories. Extensive experiments show that our proposed method outperforms state-of-the-art audio-visual localization methods, achieving a mean absolute error (MAE) of 12.04 and an accuracy (ACC) of 78.23%.
Exploring Length Generalization For Transformer-based Speech Enhancement
Jun 07, 2025
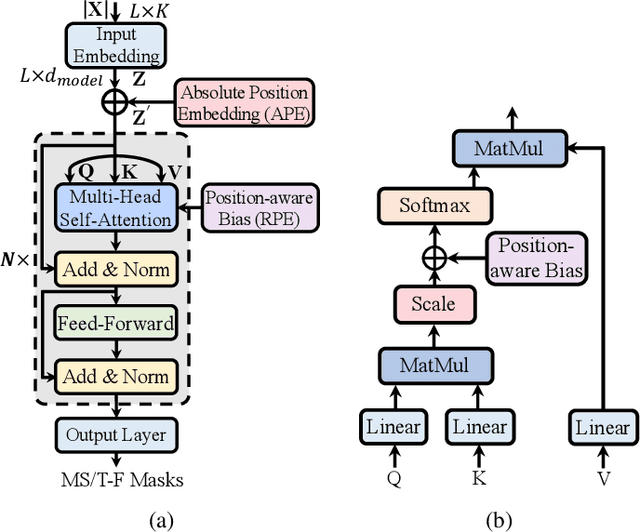
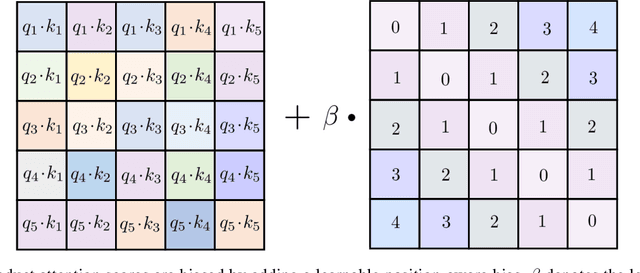
Transformer network architecture has proven effective in speech enhancement. However, as its core module, self-attention suffers from quadratic complexity, making it infeasible for training on long speech utterances. In practical scenarios, speech enhancement models are often required to perform on noisy speech at run-time that is substantially longer than the training utterances. It remains a challenge how a Transformer-based speech enhancement model can generalize to long speech utterances. In this paper, extensive empirical studies are conducted to explore the model's length generalization ability. In particular, we conduct speech enhancement experiments on four training objectives and evaluate with five metrics. Our studies establish that positional encoding is an effective instrument to dampen the effect of utterance length on speech enhancement. We first explore several existing positional encoding methods, and the results show that relative positional encoding methods exhibit a better length generalization property than absolute positional encoding methods. Additionally, we also explore a simpler and more effective positional encoding scheme, i.e. LearnLin, that uses only one trainable parameter for each attention head to scale the real relative position between time frames, which learns the different preferences on short- or long-term dependencies of these heads. The results demonstrate that our proposal exhibits excellent length generalization ability with comparable or superior performance than other state-of-the-art positional encoding strategies.
FIGhost: Fluorescent Ink-based Stealthy and Flexible Backdoor Attacks on Physical Traffic Sign Recognition
May 17, 2025Traffic sign recognition (TSR) systems are crucial for autonomous driving but are vulnerable to backdoor attacks. Existing physical backdoor attacks either lack stealth, provide inflexible attack control, or ignore emerging Vision-Large-Language-Models (VLMs). In this paper, we introduce FIGhost, the first physical-world backdoor attack leveraging fluorescent ink as triggers. Fluorescent triggers are invisible under normal conditions and activated stealthily by ultraviolet light, providing superior stealthiness, flexibility, and untraceability. Inspired by real-world graffiti, we derive realistic trigger shapes and enhance their robustness via an interpolation-based fluorescence simulation algorithm. Furthermore, we develop an automated backdoor sample generation method to support three attack objectives. Extensive evaluations in the physical world demonstrate FIGhost's effectiveness against state-of-the-art detectors and VLMs, maintaining robustness under environmental variations and effectively evading existing defenses.
Audio-Visual Class-Incremental Learning for Fish Feeding intensity Assessment in Aquaculture
Apr 21, 2025



Fish Feeding Intensity Assessment (FFIA) is crucial in industrial aquaculture management. Recent multi-modal approaches have shown promise in improving FFIA robustness and efficiency. However, these methods face significant challenges when adapting to new fish species or environments due to catastrophic forgetting and the lack of suitable datasets. To address these limitations, we first introduce AV-CIL-FFIA, a new dataset comprising 81,932 labelled audio-visual clips capturing feeding intensities across six different fish species in real aquaculture environments. Then, we pioneer audio-visual class incremental learning (CIL) for FFIA and demonstrate through benchmarking on AV-CIL-FFIA that it significantly outperforms single-modality methods. Existing CIL methods rely heavily on historical data. Exemplar-based approaches store raw samples, creating storage challenges, while exemplar-free methods avoid data storage but struggle to distinguish subtle feeding intensity variations across different fish species. To overcome these limitations, we introduce HAIL-FFIA, a novel audio-visual class-incremental learning framework that bridges this gap with a prototype-based approach that achieves exemplar-free efficiency while preserving essential knowledge through compact feature representations. Specifically, HAIL-FFIA employs hierarchical representation learning with a dual-path knowledge preservation mechanism that separates general intensity knowledge from fish-specific characteristics. Additionally, it features a dynamic modality balancing system that adaptively adjusts the importance of audio versus visual information based on feeding behaviour stages. Experimental results show that HAIL-FFIA is superior to SOTA methods on AV-CIL-FFIA, achieving higher accuracy with lower storage needs while effectively mitigating catastrophic forgetting in incremental fish species learning.