 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVP-SelDoA: Visual-prompted Selective DoA Estimation of Target Sound via Semantic-Spatial Matching
Jul 10, 2025Audio-visual sound source localization (AV-SSL) identifies the position of a sound source by exploiting the complementary strengths of auditory and visual signals. However, existing AV-SSL methods encounter three major challenges: 1) inability to selectively isolate the target sound source in multi-source scenarios, 2) misalignment between semantic visual features and spatial acoustic features, and 3) overreliance on paired audio-visual data. To overcome these limitations, we introduce Cross-Instance Audio-Visual Localization (CI-AVL), a novel task that leverages images from different instances of the same sound event category to localize target sound sources, thereby reducing dependence on paired data while enhancing generalization capabilities. Our proposed VP-SelDoA tackles this challenging task through a semantic-level modality fusion and employs a Frequency-Temporal ConMamba architecture to generate target-selective masks for sound isolation. We further develop a Semantic-Spatial Matching mechanism that aligns the heterogeneous semantic and spatial features via integrated cross- and self-attention mechanisms. To facilitate the CI-AVL research, we construct a large-scale dataset named VGG-SSL, comprising 13,981 spatial audio clips across 296 sound event categories. Extensive experiments show that our proposed method outperforms state-of-the-art audio-visual localization methods, achieving a mean absolute error (MAE) of 12.04 and an accuracy (ACC) of 78.23%.
Exploring Length Generalization For Transformer-based Speech Enhancement
Jun 07, 2025
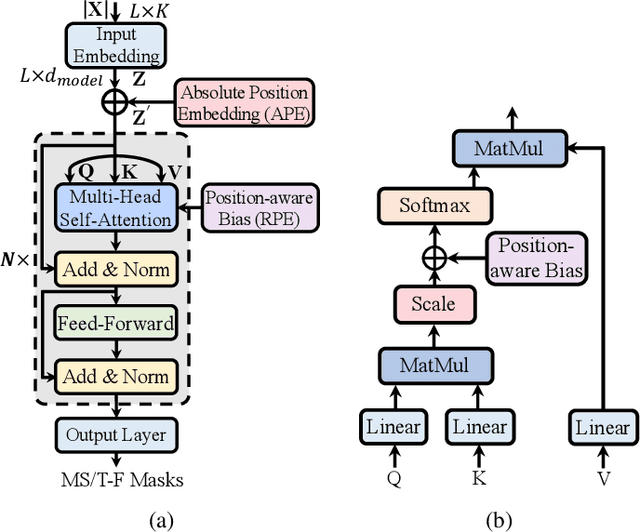
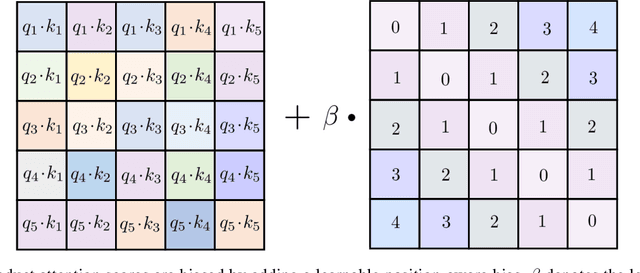
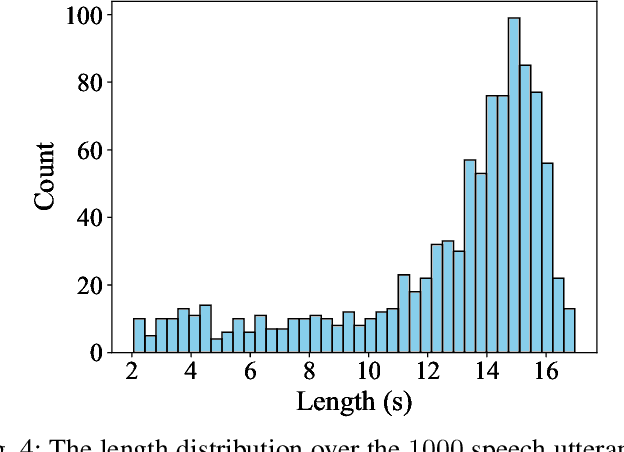
Transformer network architecture has proven effective in speech enhancement. However, as its core module, self-attention suffers from quadratic complexity, making it infeasible for training on long speech utterances. In practical scenarios, speech enhancement models are often required to perform on noisy speech at run-time that is substantially longer than the training utterances. It remains a challenge how a Transformer-based speech enhancement model can generalize to long speech utterances. In this paper, extensive empirical studies are conducted to explore the model's length generalization ability. In particular, we conduct speech enhancement experiments on four training objectives and evaluate with five metrics. Our studies establish that positional encoding is an effective instrument to dampen the effect of utterance length on speech enhancement. We first explore several existing positional encoding methods, and the results show that relative positional encoding methods exhibit a better length generalization property than absolute positional encoding methods. Additionally, we also explore a simpler and more effective positional encoding scheme, i.e. LearnLin, that uses only one trainable parameter for each attention head to scale the real relative position between time frames, which learns the different preferences on short- or long-term dependencies of these heads. The results demonstrate that our proposal exhibits excellent length generalization ability with comparable or superior performance than other state-of-the-art positional encoding strategies.
An Exploration of Length Generalization in Transformer-Based Speech Enhancement
Jun 17, 2024



The use of Transformer architectures has facilitated remarkable progress in speech enhancement. Training Transformers using substantially long speech utterances is often infeasible as self-attention suffers from quadratic complexity. It is a critical and unexplored challenge for a Transformer-based speech enhancement model to learn from short speech utterances and generalize to longer ones. In this paper, we conduct comprehensive experiments to explore the length generalization problem in speech enhancement with Transformer. Our findings first establish that position embedding provides an effective instrument to alleviate the impact of utterance length on Transformer-based speech enhancement. Specifically, we explore four different position embedding schemes to enable length generalization. The results confirm the superiority of relative position embeddings (RPEs) over absolute PE (APEs) in length generalization.
An Empirical Study on the Impact of Positional Encoding in Transformer-based Monaural Speech Enhancement
Jan 18, 2024



Transformer architecture has enabled recent progress in speech enhancement. Since Transformers are position-agostic, positional encoding is the de facto standard component used to enable Transformers to distinguish the order of elements in a sequence. However, it remains unclear how positional encoding exactly impacts speech enhancement based on Transformer architectures. In this paper, we perform a comprehensive empirical study evaluating five positional encoding methods, i.e., Sinusoidal and learned absolute position embedding (APE), T5-RPE, KERPLE, as well as the Transformer without positional encoding (No-Pos), across both causal and noncausal configurations. We conduct extensive speech enhancement experiments, involving spectral mapping and masking methods. Our findings establish that positional encoding is not quite helpful for the models in a causal configuration, which indicates that causal attention may implicitly incorporate position information. In a noncausal configuration, the models significantly benefit from the use of positional encoding. In addition, we find that among the four position embeddings, relative position embeddings outperform APEs.
EEG-Derived Voice Signature for Attended Speaker Detection
Aug 28, 2023



\textit{Objective:} Conventional EEG-based auditory attention detection (AAD) is achieved by comparing the time-varying speech stimuli and the elicited EEG signals. However, in order to obtain reliable correlation values, these methods necessitate a long decision window, resulting in a long detection latency. Humans have a remarkable ability to recognize and follow a known speaker, regardless of the spoken content. In this paper, we seek to detect the attended speaker among the pre-enrolled speakers from the elicited EEG signals. In this manner, we avoid relying on the speech stimuli for AAD at run-time. In doing so, we propose a novel EEG-based attended speaker detection (E-ASD) task. \textit{Methods:} We encode a speaker's voice with a fixed dimensional vector, known as speaker embedding, and project it to an audio-derived voice signature, which characterizes the speaker's unique voice regardless of the spoken content. We hypothesize that such a voice signature also exists in the listener's brain that can be decoded from the elicited EEG signals, referred to as EEG-derived voice signature. By comparing the audio-derived voice signature and the EEG-derived voice signature, we are able to effectively detect the attended speaker in the listening brain. \textit{Results:} Experiments show that E-ASD can effectively detect the attended speaker from the 0.5s EEG decision windows, achieving 99.78\% AAD accuracy, 99.94\% AUC, and 0.27\% EER. \textit{Conclusion:} We conclude that it is possible to derive the attended speaker's voice signature from the EEG signals so as to detect the attended speaker in a listening brain. \textit{Significance:} We present the first proof of concept for detecting the attended speaker from the elicited EEG signals in a cocktail party environment. The successful implementation of E-ASD marks a non-trivial, but crucial step towards smart hearing aids.
An Automata-Theoretic Approach to Synthesizing Binarized Neural Networks
Jul 29, 2023



Deep neural networks, (DNNs, a.k.a. NNs), have been widely used in various tasks and have been proven to be successful. However, the accompanied expensive computing and storage costs make the deployments in resource-constrained devices a significant concern. To solve this issue, quantization has emerged as an effective way to reduce the costs of DNNs with little accuracy degradation by quantizing floating-point numbers to low-width fixed-point representations. Quantized neural networks (QNNs) have been developed, with binarized neural networks (BNNs) restricted to binary values as a special case. Another concern about neural networks is their vulnerability and lack of interpretability. Despite the active research on trustworthy of DNNs, few approaches have been proposed to QNNs. To this end, this paper presents an automata-theoretic approach to synthesizing BNNs that meet designated properties. More specifically, we define a temporal logic, called BLTL, as the specification language. We show that each BLTL formula can be transformed into an automaton on finite words. To deal with the state-explosion problem, we provide a tableau-based approach in real implementation. For the synthesis procedure, we utilize SMT solvers to detect the existence of a model (i.e., a BNN) in the construction process. Notably, synthesis provides a way to determine the hyper-parameters of the network before training.Moreover, we experimentally evaluate our approach and demonstrate its effectiveness in improving the individual fairness and local robustness of BNNs while maintaining accuracy to a great extent.
Ripple sparse self-attention for monaural speech enhancement
May 15, 2023The use of Transformer represents a recent success in speech enhancement. However, as its core component, self-attention suffers from quadratic complexity, which is computationally prohibited for long speech recordings. Moreover, it allows each time frame to attend to all time frames, neglecting the strong local correlations of speech signals. This study presents a simple yet effective sparse self-attention for speech enhancement, called ripple attention, which simultaneously performs fine- and coarse-grained modeling for local and global dependencies, respectively. Specifically, we employ local band attention to enable each frame to attend to its closest neighbor frames in a window at fine granularity, while employing dilated attention outside the window to model the global dependencies at a coarse granularity. We evaluate the efficacy of our ripple attention for speech enhancement on two commonly used training objectives. Extensive experimental results consistently confirm the superior performance of the ripple attention design over standard full self-attention, blockwise attention, and dual-path attention (Sep-Former) in terms of speech quality and intelligibility.