 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVidDoS: Universal Denial-of-Service Attack on Video-based Large Language Models
Mar 02, 2026Video-LLMs are increasingly deployed in safety-critical applications but are vulnerable to Energy-Latency Attacks (ELAs) that exhaust computational resources. Current image-centric methods fail because temporal aggregation mechanisms dilute individual frame perturbations. Additionally, real-time demands make instance-wise optimization impractical for continuous video streams. We introduce VidDoS, which is the first universal ELA framework tailored for Video-LLMs. Our method leverages universal optimization to create instance-agnostic triggers that require no inference-time gradient calculation. We achieve this through $\textit{masked teacher forcing}$ to steer models toward expensive target sequences, combined with a $\textit{refusal penalty}$ and $\textit{early-termination suppression}$ to override conciseness priors. Testing across three mainstream Video-LLMs and three video datasets, which include video question answering and autonomous driving scenarios, shows extreme degradation. VidDoS induces a token expansion of more than 205$\times$ and inflates the inference latency by more than 15$\times$ relative to clean baselines. Simulations of real-time autonomous driving streams further reveal that this induced latency leads to critical safety violations. We urge the community to recognize and mitigate these high-hazard ELA in Video-LLMs.
Youtu-Agent: Scaling Agent Productivity with Automated Generation and Hybrid Policy Optimization
Dec 31, 2025Existing Large Language Model (LLM) agent frameworks face two significant challenges: high configuration costs and static capabilities. Building a high-quality agent often requires extensive manual effort in tool integration and prompt engineering, while deployed agents struggle to adapt to dynamic environments without expensive fine-tuning. To address these issues, we propose \textbf{Youtu-Agent}, a modular framework designed for the automated generation and continuous evolution of LLM agents. Youtu-Agent features a structured configuration system that decouples execution environments, toolkits, and context management, enabling flexible reuse and automated synthesis. We introduce two generation paradigms: a \textbf{Workflow} mode for standard tasks and a \textbf{Meta-Agent} mode for complex, non-standard requirements, capable of automatically generating tool code, prompts, and configurations. Furthermore, Youtu-Agent establishes a hybrid policy optimization system: (1) an \textbf{Agent Practice} module that enables agents to accumulate experience and improve performance through in-context optimization without parameter updates; and (2) an \textbf{Agent RL} module that integrates with distributed training frameworks to enable scalable and stable reinforcement learning of any Youtu-Agents in an end-to-end, large-scale manner. Experiments demonstrate that Youtu-Agent achieves state-of-the-art performance on WebWalkerQA (71.47\%) and GAIA (72.8\%) using open-weight models. Our automated generation pipeline achieves over 81\% tool synthesis success rate, while the Practice module improves performance on AIME 2024/2025 by +2.7\% and +5.4\% respectively. Moreover, our Agent RL training achieves 40\% speedup with steady performance improvement on 7B LLMs, enhancing coding/reasoning and searching capabilities respectively up to 35\% and 21\% on Maths and general/multi-hop QA benchmarks.
SmartSnap: Proactive Evidence Seeking for Self-Verifying Agents
Dec 26, 2025Agentic reinforcement learning (RL) holds great promise for the development of autonomous agents under complex GUI tasks, but its scalability remains severely hampered by the verification of task completion. Existing task verification is treated as a passive, post-hoc process: a verifier (i.e., rule-based scoring script, reward or critic model, and LLM-as-a-Judge) analyzes the agent's entire interaction trajectory to determine if the agent succeeds. Such processing of verbose context that contains irrelevant, noisy history poses challenges to the verification protocols and therefore leads to prohibitive cost and low reliability. To overcome this bottleneck, we propose SmartSnap, a paradigm shift from this passive, post-hoc verification to proactive, in-situ self-verification by the agent itself. We introduce the Self-Verifying Agent, a new type of agent designed with dual missions: to not only complete a task but also to prove its accomplishment with curated snapshot evidences. Guided by our proposed 3C Principles (Completeness, Conciseness, and Creativity), the agent leverages its accessibility to the online environment to perform self-verification on a minimal, decisive set of snapshots. Such evidences are provided as the sole materials for a general LLM-as-a-Judge verifier to determine their validity and relevance. Experiments on mobile tasks across model families and scales demonstrate that our SmartSnap paradigm allows training LLM-driven agents in a scalable manner, bringing performance gains up to 26.08% and 16.66% respectively to 8B and 30B models. The synergizing between solution finding and evidence seeking facilitates the cultivation of efficient, self-verifying agents with competitive performance against DeepSeek V3.1 and Qwen3-235B-A22B.
Heaven-Sent or Hell-Bent? Benchmarking the Intelligence and Defectiveness of LLM Hallucinations
Dec 25, 2025

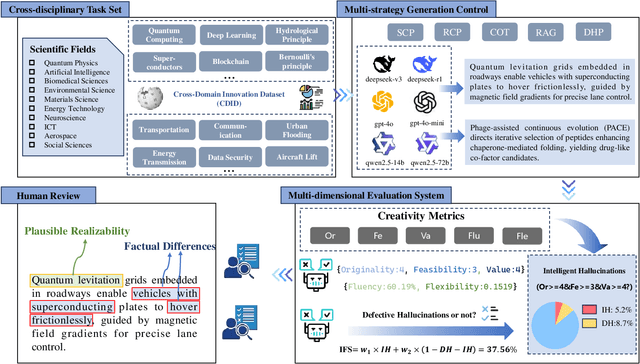

Hallucinations in large language models (LLMs) are commonly regarded as errors to be minimized. However, recent perspectives suggest that some hallucinations may encode creative or epistemically valuable content, a dimension that remains underquantified in current literature. Existing hallucination detection methods primarily focus on factual consistency, struggling to handle heterogeneous scientific tasks and balance creativity with accuracy. To address these challenges, we propose HIC-Bench, a novel evaluation framework that categorizes hallucinations into Intelligent Hallucinations (IH) and Defective Hallucinations (DH), enabling systematic investigation of their interplay in LLM creativity. HIC-Bench features three core characteristics: (1) Structured IH/DH Assessment. using a multi-dimensional metric matrix integrating Torrance Tests of Creative Thinking (TTCT) metrics (Originality, Feasibility, Value) with hallucination-specific dimensions (scientific plausibility, factual deviation); (2) Cross-Domain Applicability. spanning ten scientific domains with open-ended innovation tasks; and (3) Dynamic Prompt Optimization. leveraging the Dynamic Hallucination Prompt (DHP) to guide models toward creative and reliable outputs. The evaluation process employs multiple LLM judges, averaging scores to mitigate bias, with human annotators verifying IH/DH classifications. Experimental results reveal a nonlinear relationship between IH and DH, demonstrating that creativity and correctness can be jointly optimized. These insights position IH as a catalyst for creativity and reveal the ability of LLM hallucinations to drive scientific innovation.Additionally, the HIC-Bench offers a valuable platform for advancing research into the creative intelligence of LLM hallucinations.
Learn the Ropes, Then Trust the Wins: Self-imitation with Progressive Exploration for Agentic Reinforcement Learning
Sep 26, 2025
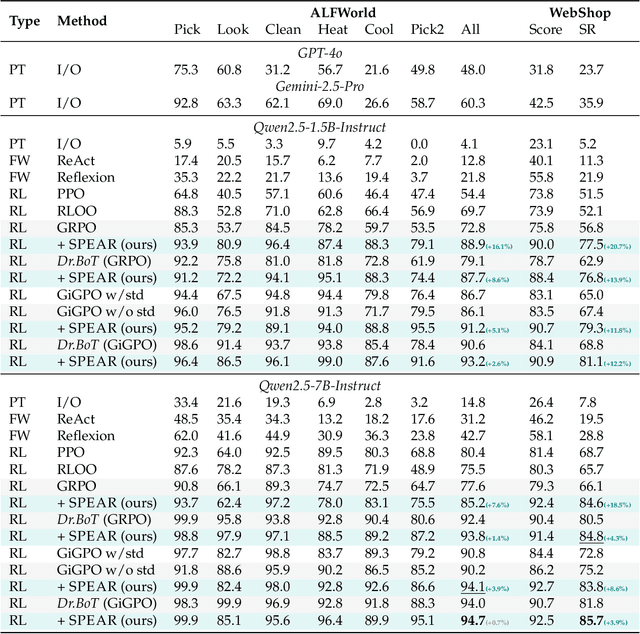
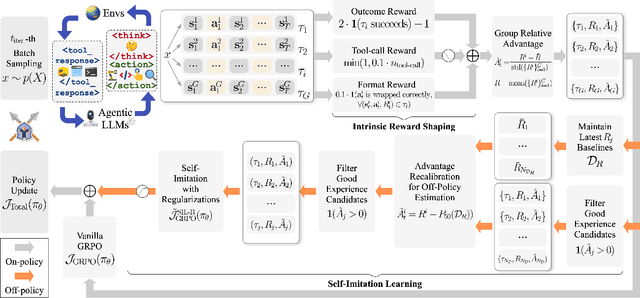
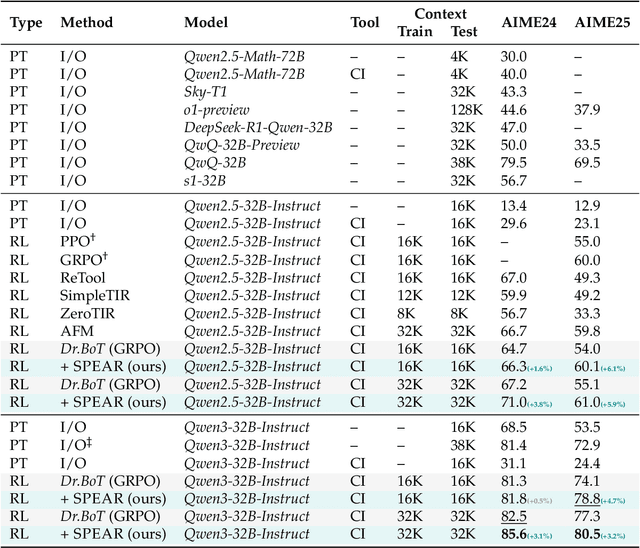
Reinforcement learning (RL) is the dominant paradigm for sharpening strategic tool use capabilities of LLMs on long-horizon, sparsely-rewarded agent tasks, yet it faces a fundamental challenge of exploration-exploitation trade-off. Existing studies stimulate exploration through the lens of policy entropy, but such mechanical entropy maximization is prone to RL training instability due to the multi-turn distribution shifting. In this paper, we target the progressive exploration-exploitation balance under the guidance of the agent own experiences without succumbing to either entropy collapsing or runaway divergence. We propose SPEAR, a curriculum-based self-imitation learning (SIL) recipe for training agentic LLMs. It extends the vanilla SIL framework, where a replay buffer stores self-generated promising trajectories for off-policy update, by gradually steering the policy evolution within a well-balanced range of entropy across stages. Specifically, our approach incorporates a curriculum to manage the exploration process, utilizing intrinsic rewards to foster skill-level exploration and facilitating action-level exploration through SIL. At first, the auxiliary tool call reward plays a critical role in the accumulation of tool-use skills, enabling broad exposure to the unfamiliar distributions of the environment feedback with an upward entropy trend. As training progresses, self-imitation gets strengthened to exploit existing successful patterns from replayed experiences for comparative action-level exploration, accelerating solution iteration without unbounded entropy growth. To further stabilize training, we recalibrate the advantages of experiences in the replay buffer to address the potential policy drift. Reugularizations such as the clipping of tokens with high covariance between probability and advantage are introduced to the trajectory-level entropy control to curb over-confidence.
S$^2$M-Former: Spiking Symmetric Mixing Branchformer for Brain Auditory Attention Detection
Aug 07, 2025



Auditory attention detection (AAD) aims to decode listeners' focus in complex auditory environments from electroencephalography (EEG) recordings, which is crucial for developing neuro-steered hearing devices. Despite recent advancements, EEG-based AAD remains hindered by the absence of synergistic frameworks that can fully leverage complementary EEG features under energy-efficiency constraints. We propose S$^2$M-Former, a novel spiking symmetric mixing framework to address this limitation through two key innovations: i) Presenting a spike-driven symmetric architecture composed of parallel spatial and frequency branches with mirrored modular design, leveraging biologically plausible token-channel mixers to enhance complementary learning across branches; ii) Introducing lightweight 1D token sequences to replace conventional 3D operations, reducing parameters by 14.7$\times$. The brain-inspired spiking architecture further reduces power consumption, achieving a 5.8$\times$ energy reduction compared to recent ANN methods, while also surpassing existing SNN baselines in terms of parameter efficiency and performance. Comprehensive experiments on three AAD benchmarks (KUL, DTU and AV-GC-AAD) across three settings (within-trial, cross-trial and cross-subject) demonstrate that S$^2$M-Former achieves comparable state-of-the-art (SOTA) decoding accuracy, making it a promising low-power, high-performance solution for AAD tasks.
FlowAgent: Achieving Compliance and Flexibility for Workflow Agents
Feb 20, 2025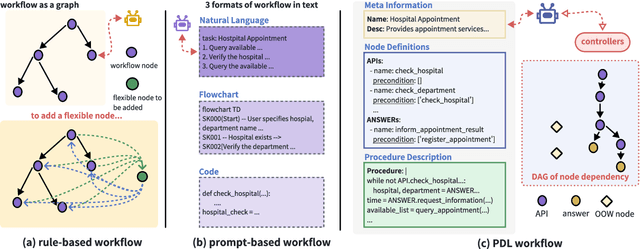

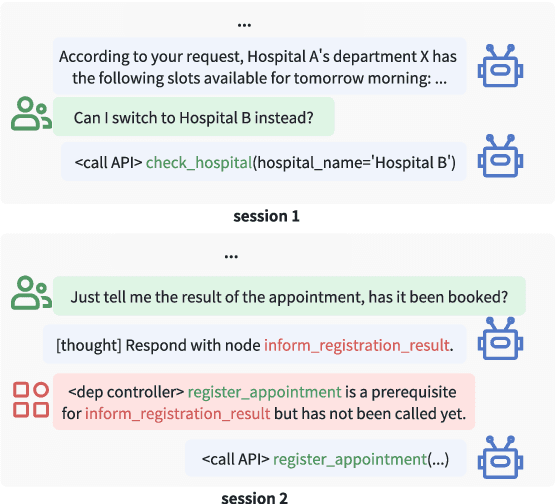
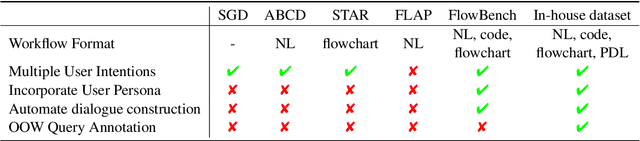
The integration of workflows with large language models (LLMs) enables LLM-based agents to execute predefined procedures, enhancing automation in real-world applications. Traditional rule-based methods tend to limit the inherent flexibility of LLMs, as their predefined execution paths restrict the models' action space, particularly when the unexpected, out-of-workflow (OOW) queries are encountered. Conversely, prompt-based methods allow LLMs to fully control the flow, which can lead to diminished enforcement of procedural compliance. To address these challenges, we introduce FlowAgent, a novel agent framework designed to maintain both compliance and flexibility. We propose the Procedure Description Language (PDL), which combines the adaptability of natural language with the precision of code to formulate workflows. Building on PDL, we develop a comprehensive framework that empowers LLMs to manage OOW queries effectively, while keeping the execution path under the supervision of a set of controllers. Additionally, we present a new evaluation methodology to rigorously assess an LLM agent's ability to handle OOW scenarios, going beyond routine flow compliance tested in existing benchmarks. Experiments on three datasets demonstrate that FlowAgent not only adheres to workflows but also effectively manages OOW queries, highlighting its dual strengths in compliance and flexibility. The code is available at https://github.com/Lightblues/FlowAgent.
LUCY: Linguistic Understanding and Control Yielding Early Stage of Her
Jan 27, 2025



The film Her features Samantha, a sophisticated AI audio agent who is capable of understanding both linguistic and paralinguistic information in human speech and delivering real-time responses that are natural, informative and sensitive to emotional subtleties. Moving one step toward more sophisticated audio agent from recent advancement in end-to-end (E2E) speech systems, we propose LUCY, a E2E speech model that (1) senses and responds to user's emotion, (2) deliver responses in a succinct and natural style, and (3) use external tool to answer real-time inquiries. Experiment results show that LUCY is better at emotion control than peer models, generating emotional responses based on linguistic emotional instructions and responding to paralinguistic emotional cues. Lucy is also able to generate responses in a more natural style, as judged by external language models, without sacrificing much performance on general question answering. Finally, LUCY can leverage function calls to answer questions that are out of its knowledge scope.
STAND-Guard: A Small Task-Adaptive Content Moderation Model
Nov 07, 2024

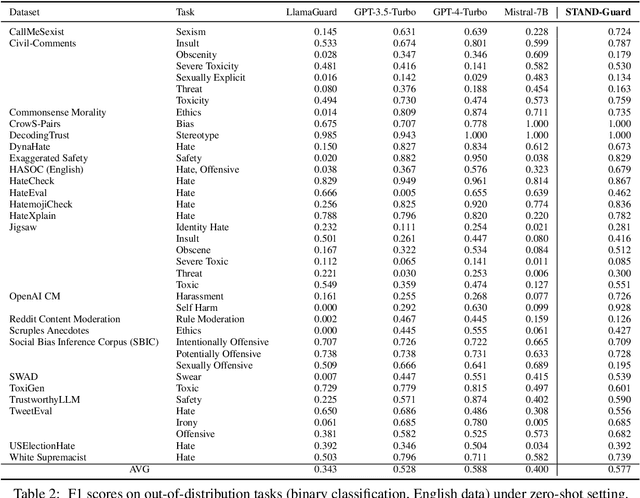

Content moderation, the process of reviewing and monitoring the safety of generated content, is important for development of welcoming online platforms and responsible large language models. Content moderation contains various tasks, each with its unique requirements tailored to specific scenarios. Therefore, it is crucial to develop a model that can be easily adapted to novel or customized content moderation tasks accurately without extensive model tuning. This paper presents STAND-GUARD, a Small Task-Adaptive coNtent moDeration model. The basic motivation is: by performing instruct tuning on various content moderation tasks, we can unleash the power of small language models (SLMs) on unseen (out-of-distribution) content moderation tasks. We also carefully study the effects of training tasks and model size on the efficacy of cross-task fine-tuning mechanism. Experiments demonstrate STAND-Guard is comparable to GPT-3.5-Turbo across over 40 public datasets, as well as proprietary datasets derived from real-world business scenarios. Remarkably, STAND-Guard achieved nearly equivalent results to GPT-4-Turbo on unseen English binary classification tasks
NeuroSpex: Neuro-Guided Speaker Extraction with Cross-Modal Attention
Sep 04, 2024
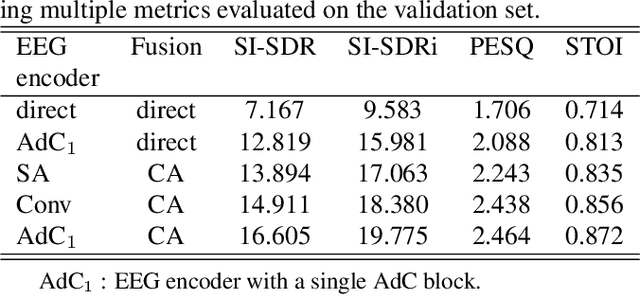
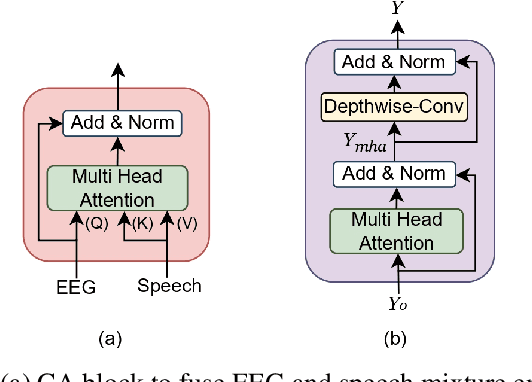
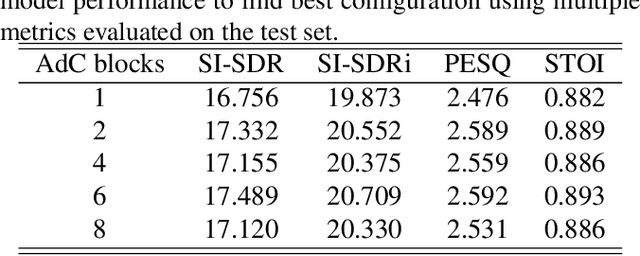
In the study of auditory attention, it has been revealed that there exists a robust correlation between attended speech and elicited neural responses, measurable through electroencephalography (EEG). Therefore, it is possible to use the attention information available within EEG signals to guide the extraction of the target speaker in a cocktail party computationally. In this paper, we present a neuro-guided speaker extraction model, i.e. NeuroSpex, using the EEG response of the listener as the sole auxiliary reference cue to extract attended speech from monaural speech mixtures. We propose a novel EEG signal encoder that captures the attention information. Additionally, we propose a cross-attention (CA) mechanism to enhance the speech feature representations, generating a speaker extraction mask. Experimental results on a publicly available dataset demonstrate that our proposed model outperforms two baseline models across various evaluation metrics.