 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantizer-Aware Hierarchical Neural Codec Modeling for Speech Deepfake Detection
Mar 10, 2026Neural audio codecs discretize speech via residual vector quantization (RVQ), forming a coarse-to-fine hierarchy across quantizers. While codec models have been explored for representation learning, their discrete structure remains underutilized in speech deepfake detection. In particular, different quantization levels capture complementary acoustic cues, where early quantizers encode coarse structure and later quantizers refine residual details that reveal synthesis artifacts. Existing systems either rely on continuous encoder features or ignore this quantizer-level hierarchy. We propose a hierarchy-aware representation learning framework that models quantizer-level contributions through learnable global weighting, enabling structured codec representations aligned with forensic cues. Keeping the speech encoder backbone frozen and updating only 4.4% additional parameters, our method achieves relative EER reductions of 46.2% on ASVspoof 2019 and 13.9% on ASVspoof5 over strong baselines.
Analytic Incremental Learning For Sound Source Localization With Imbalance Rectification
Jan 26, 2026Sound source localization (SSL) demonstrates remarkable results in controlled settings but struggles in real-world deployment due to dual imbalance challenges: intra-task imbalance arising from long-tailed direction-of-arrival (DoA) distributions, and inter-task imbalance induced by cross-task skews and overlaps. These often lead to catastrophic forgetting, significantly degrading the localization accuracy. To mitigate these issues, we propose a unified framework with two key innovations. Specifically, we design a GCC-PHAT-based data augmentation (GDA) method that leverages peak characteristics to alleviate intra-task distribution skews. We also propose an Analytic dynamic imbalance rectifier (ADIR) with task-adaption regularization, which enables analytic updates that adapt to inter-task dynamics. On the SSLR benchmark, our proposal achieves state-of-the-art (SoTA) results of 89.0% accuracy, 5.3° mean absolute error, and 1.6 backward transfer, demonstrating robustness to evolving imbalances without exemplar storage.
Fun-Audio-Chat Technical Report
Dec 23, 2025Recent advancements in joint speech-text models show great potential for seamless voice interactions. However, existing models face critical challenges: temporal resolution mismatch between speech tokens (25Hz) and text tokens (~3Hz) dilutes semantic information, incurs high computational costs, and causes catastrophic forgetting of text LLM knowledge. We introduce Fun-Audio-Chat, a Large Audio Language Model addressing these limitations via two innovations from our previous work DrVoice. First, Dual-Resolution Speech Representations (DRSR): the Shared LLM processes audio at efficient 5Hz (via token grouping), while the Speech Refined Head generates high-quality tokens at 25Hz, balancing efficiency (~50% GPU reduction) and quality. Second, Core-Cocktail Training, a two-stage fine-tuning with intermediate merging that mitigates catastrophic forgetting. We then apply Multi-Task DPO Training to enhance robustness, audio understanding, instruction-following and voice empathy. This multi-stage post-training enables Fun-Audio-Chat to retain text LLM knowledge while gaining powerful audio understanding, reasoning, and generation. Unlike recent LALMs requiring large-scale audio-text pre-training, Fun-Audio-Chat leverages pre-trained models and extensive post-training. Fun-Audio-Chat 8B and MoE 30B-A3B achieve competitive performance on Speech-to-Text and Speech-to-Speech tasks, ranking top among similar-scale models on Spoken QA benchmarks. They also achieve competitive to superior performance on Audio Understanding, Speech Function Calling, Instruction-Following and Voice Empathy. We develop Fun-Audio-Chat-Duplex, a full-duplex variant with strong performance on Spoken QA and full-duplex interactions. We open-source Fun-Audio-Chat-8B with training and inference code, and provide an interactive demo.
Exploring Length Generalization For Transformer-based Speech Enhancement
Jun 07, 2025
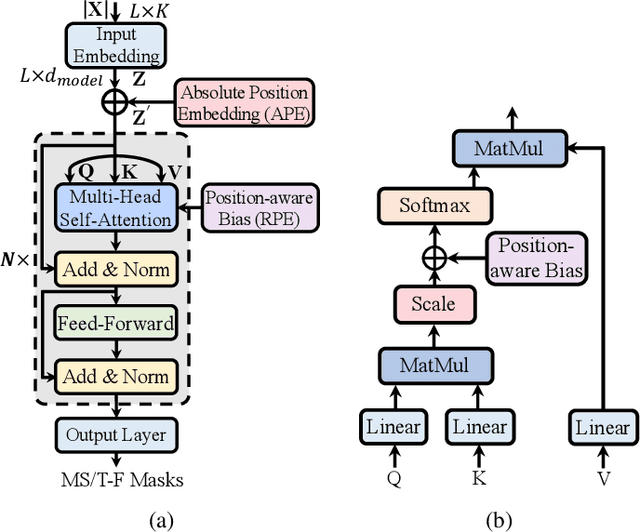
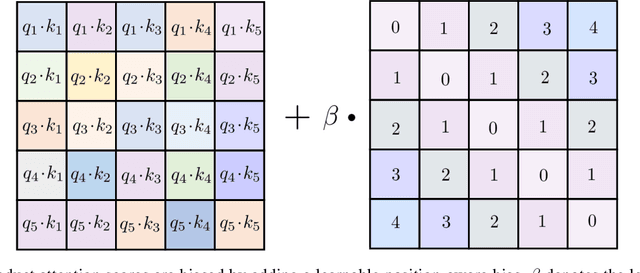
Transformer network architecture has proven effective in speech enhancement. However, as its core module, self-attention suffers from quadratic complexity, making it infeasible for training on long speech utterances. In practical scenarios, speech enhancement models are often required to perform on noisy speech at run-time that is substantially longer than the training utterances. It remains a challenge how a Transformer-based speech enhancement model can generalize to long speech utterances. In this paper, extensive empirical studies are conducted to explore the model's length generalization ability. In particular, we conduct speech enhancement experiments on four training objectives and evaluate with five metrics. Our studies establish that positional encoding is an effective instrument to dampen the effect of utterance length on speech enhancement. We first explore several existing positional encoding methods, and the results show that relative positional encoding methods exhibit a better length generalization property than absolute positional encoding methods. Additionally, we also explore a simpler and more effective positional encoding scheme, i.e. LearnLin, that uses only one trainable parameter for each attention head to scale the real relative position between time frames, which learns the different preferences on short- or long-term dependencies of these heads. The results demonstrate that our proposal exhibits excellent length generalization ability with comparable or superior performance than other state-of-the-art positional encoding strategies.
Should Audio Front-ends be Adaptive? Comparing Learnable and Adaptive Front-ends
Feb 05, 2025Hand-crafted features, such as Mel-filterbanks, have traditionally been the choice for many audio processing applications. Recently, there has been a growing interest in learnable front-ends that extract representations directly from the raw audio waveform. \textcolor{black}{However, both hand-crafted filterbanks and current learnable front-ends lead to fixed computation graphs at inference time, failing to dynamically adapt to varying acoustic environments, a key feature of human auditory systems.} To this end, we explore the question of whether audio front-ends should be adaptive by comparing the Ada-FE front-end (a recently developed adaptive front-end that employs a neural adaptive feedback controller to dynamically adjust the Q-factors of its spectral decomposition filters) to established learnable front-ends. Specifically, we systematically investigate learnable front-ends and Ada-FE across two commonly used back-end backbones and a wide range of audio benchmarks including speech, sound event, and music. The comprehensive results show that our Ada-FE outperforms advanced learnable front-ends, and more importantly, it exhibits impressive stability or robustness on test samples over various training epochs.
Time-Graph Frequency Representation with Singular Value Decomposition for Neural Speech Enhancement
Dec 24, 2024Time-frequency (T-F) domain methods for monaural speech enhancement have benefited from the success of deep learning. Recently, focus has been put on designing two-stream network models to predict amplitude mask and phase separately, or, coupling the amplitude and phase into Cartesian coordinates and constructing real and imaginary pairs. However, most methods suffer from the alignment modeling of amplitude and phase (real and imaginary pairs) in a two-stream network framework, which inevitably incurs performance restrictions. In this paper, we introduce a graph Fourier transform defined with the singular value decomposition (GFT-SVD), resulting in real-valued time-graph representation for neural speech enhancement. This real-valued representation-based GFT-SVD provides an ability to align the modeling of amplitude and phase, leading to avoiding recovering the target speech phase information. Our findings demonstrate the effects of real-valued time-graph representation based on GFT-SVD for neutral speech enhancement. The extensive speech enhancement experiments establish that the combination of GFT-SVD and DNN outperforms the combination of GFT with the eigenvector decomposition (GFT-EVD) and magnitude estimation UNet, and outperforms the short-time Fourier transform (STFT) and DNN, regarding objective intelligibility and perceptual quality. We release our source code at: https://github.com/Wangfighting0015/GFT\_project.
SAV-SE: Scene-aware Audio-Visual Speech Enhancement with Selective State Space Model
Nov 12, 2024
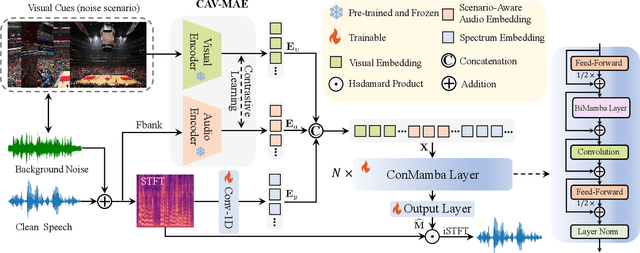

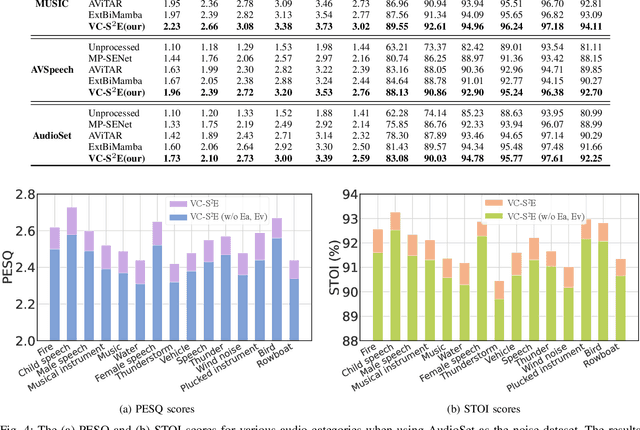
Speech enhancement plays an essential role in various applications, and the integration of visual information has been demonstrated to bring substantial advantages. However, the majority of current research concentrates on the examination of facial and lip movements, which can be compromised or entirely inaccessible in scenarios where occlusions occur or when the camera view is distant. Whereas contextual visual cues from the surrounding environment have been overlooked: for example, when we see a dog bark, our brain has the innate ability to discern and filter out the barking noise. To this end, in this paper, we introduce a novel task, i.e. SAV-SE. To our best knowledge, this is the first proposal to use rich contextual information from synchronized video as auxiliary cues to indicate the type of noise, which eventually improves the speech enhancement performance. Specifically, we propose the VC-S$^2$E method, which incorporates the Conformer and Mamba modules for their complementary strengths. Extensive experiments are conducted on public MUSIC, AVSpeech and AudioSet datasets, where the results demonstrate the superiority of VC-S$^2$E over other competitive methods. We will make the source code publicly available. Project demo page: https://AVSEPage.github.io/
Selective State Space Model for Monaural Speech Enhancement
Nov 09, 2024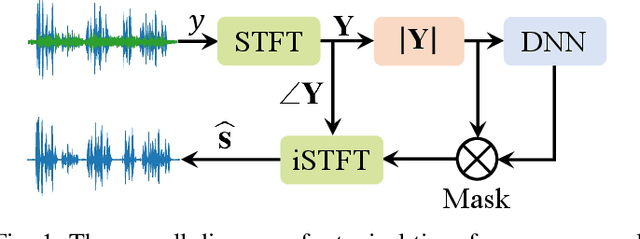
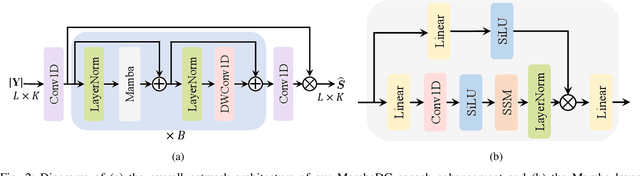
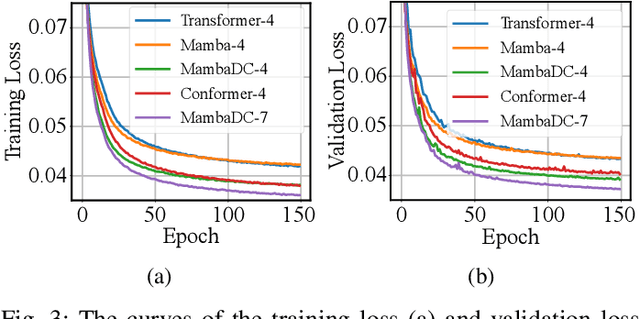
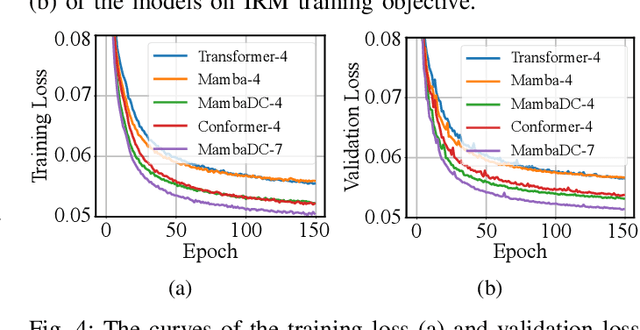
Voice user interfaces (VUIs) have facilitated the efficient interactions between humans and machines through spoken commands. Since real-word acoustic scenes are complex, speech enhancement plays a critical role for robust VUI. Transformer and its variants, such as Conformer, have demonstrated cutting-edge results in speech enhancement. However, both of them suffers from the quadratic computational complexity with respect to the sequence length, which hampers their ability to handle long sequences. Recently a novel State Space Model called Mamba, which shows strong capability to handle long sequences with linear complexity, offers a solution to address this challenge. In this paper, we propose a novel hybrid convolution-Mamba backbone, denoted as MambaDC, for speech enhancement. Our MambaDC marries the benefits of convolutional networks to model the local interactions and Mamba's ability for modeling long-range global dependencies. We conduct comprehensive experiments within both basic and state-of-the-art (SoTA) speech enhancement frameworks, on two commonly used training targets. The results demonstrate that MambaDC outperforms Transformer, Conformer, and the standard Mamba across all training targets. Built upon the current advanced framework, the use of MambaDC backbone showcases superior results compared to existing \textcolor{black}{SoTA} systems. This sets the stage for efficient long-range global modeling in speech enhancement.
Binaural Selective Attention Model for Target Speaker Extraction
Jun 18, 2024



The remarkable ability of humans to selectively focus on a target speaker in cocktail party scenarios is facilitated by binaural audio processing. In this paper, we present a binaural time-domain Target Speaker Extraction model based on the Filter-and-Sum Network (FaSNet). Inspired by human selective hearing, our proposed model introduces target speaker embedding into separators using a multi-head attention-based selective attention block. We also compared two binaural interaction approaches -- the cosine similarity of time-domain signals and inter-channel correlation in learned spectral representations. Our experimental results show that our proposed model outperforms monaural configurations and state-of-the-art multi-channel target speaker extraction models, achieving best-in-class performance with 18.52 dB SI-SDR, 19.12 dB SDR, and 3.05 PESQ scores under anechoic two-speaker test configurations.
An Exploration of Length Generalization in Transformer-Based Speech Enhancement
Jun 17, 2024



The use of Transformer architectures has facilitated remarkable progress in speech enhancement. Training Transformers using substantially long speech utterances is often infeasible as self-attention suffers from quadratic complexity. It is a critical and unexplored challenge for a Transformer-based speech enhancement model to learn from short speech utterances and generalize to longer ones. In this paper, we conduct comprehensive experiments to explore the length generalization problem in speech enhancement with Transformer. Our findings first establish that position embedding provides an effective instrument to alleviate the impact of utterance length on Transformer-based speech enhancement. Specifically, we explore four different position embedding schemes to enable length generalization. The results confirm the superiority of relative position embeddings (RPEs) over absolute PE (APEs) in length generalization.