 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphWalker: Graph-Guided In-Context Learning for Clinical Reasoning on Electronic Health Records
Apr 08, 2026Clinical Reasoning on Electronic Health Records (EHRs) is a fundamental yet challenging task in modern healthcare. While in-context learning (ICL) offers a promising inference-time adaptation paradigm for large language models (LLMs) in EHR reasoning, existing methods face three fundamental challenges: (1) Perspective Limitation, where data-driven similarity fails to align with LLM reasoning needs and model-driven signals are constrained by limited clinical competence; (2) Cohort Awareness, as demonstrations are selected independently without modeling population-level structure; and (3) Information Aggregation, where redundancy and interaction effects among demonstrations are ignored, leading to diminishing marginal gains. To address these challenges, we propose GraphWalker, a principled demonstration selection framework for EHR-oriented ICL. GraphWalker (i) jointly models patient clinical information and LLM-estimated information gain by integrating data-driven and model-driven perspectives, (ii) incorporates Cohort Discovery to avoid noisy local optima, and (iii) employs a Lazy Greedy Search with Frontier Expansion algorithm to mitigate diminishing marginal returns in information aggregation. Extensive experiments on multiple real-world EHR benchmarks demonstrate that GraphWalker consistently outperforms state-of-the-art ICL baselines, yielding substantial improvements in clinical reasoning performance. Our code is open-sourced at https://github.com/PuppyKnightUniversity/GraphWalker
StackPlanner: A Centralized Hierarchical Multi-Agent System with Task-Experience Memory Management
Jan 09, 2026Multi-agent systems based on large language models, particularly centralized architectures, have recently shown strong potential for complex and knowledge-intensive tasks. However, central agents often suffer from unstable long-horizon collaboration due to the lack of memory management, leading to context bloat, error accumulation, and poor cross-task generalization. To address both task-level memory inefficiency and the inability to reuse coordination experience, we propose StackPlanner, a hierarchical multi-agent framework with explicit memory control. StackPlanner addresses these challenges by decoupling high-level coordination from subtask execution with active task-level memory control, and by learning to retrieve and exploit reusable coordination experience via structured experience memory and reinforcement learning. Experiments on multiple deep-search and agent system benchmarks demonstrate the effectiveness of our approach in enabling reliable long-horizon multi-agent collaboration.
PALM-Bench: A Comprehensive Benchmark for Personalized Audio-Language Models
Jan 07, 2026Large Audio-Language Models (LALMs) have demonstrated strong performance in audio understanding and generation. Yet, our extensive benchmarking reveals that their behavior is largely generic (e.g., summarizing spoken content) and fails to adequately support personalized question answering (e.g., summarizing what my best friend says). In contrast, human conditions their interpretation and decision-making on each individual's personal context. To bridge this gap, we formalize the task of Personalized LALMs (PALM) for recognizing personal concepts and reasoning within personal context. Moreover, we create the first benchmark (PALM-Bench) to foster the methodological advances in PALM and enable structured evaluation on several tasks across multi-speaker scenarios. Our extensive experiments on representative open-source LALMs, show that existing training-free prompting and supervised fine-tuning strategies, while yield improvements, remains limited in modeling personalized knowledge and transferring them across tasks robustly. Data and code will be released.
ChiseLLM: Unleashing the Power of Reasoning LLMs for Chisel Agile Hardware Development
Apr 27, 2025The growing demand for Domain-Specific Architecture (DSA) has driven the development of Agile Hardware Development Methodology (AHDM). Hardware Construction Language (HCL) like Chisel offers high-level abstraction features, making it an ideal language for HCL-Based AHDM. While Large Language Models (LLMs) excel in code generation tasks, they still face challenges with Chisel generation, particularly regarding syntax correctness and design variability. Recent reasoning models have significantly enhanced code generation capabilities through test-time scaling techniques. However, we found that reasoning models without domain adaptation cannot bring substantial benefits to Chisel code generation tasks. This paper presents ChiseLLM, a solution comprising data processing and transformation, prompt-guided reasoning trace synthesis, and domain-adapted model training. We constructed high-quality datasets from public RTL code resources and guided the model to adopt structured thinking patterns through prompt enhancement methods. Experiments demonstrate that our ChiseLLM-7B and ChiseLLM-32B models improved syntax correctness by 18.85% and 26.32% respectively over base models, while increasing variability design ability by 47.58% compared to baseline reasoning models. Our datasets and models are publicly available, providing high-performance, cost-effective models for HCL-Based AHDM, and offering an effective baseline for future research. Github repository: https://github.com/observerw/ChiseLLM
I2TTS: Image-indicated Immersive Text-to-speech Synthesis with Spatial Perception
Nov 20, 2024Controlling the style and characteristics of speech synthesis is crucial for adapting the output to specific contexts and user requirements. Previous Text-to-speech (TTS) works have focused primarily on the technical aspects of producing natural-sounding speech, such as intonation, rhythm, and clarity. However, they overlook the fact that there is a growing emphasis on spatial perception of synthesized speech, which may provide immersive experience in gaming and virtual reality. To solve this issue, in this paper, we present a novel multi-modal TTS approach, namely Image-indicated Immersive Text-to-speech Synthesis (I2TTS). Specifically, we introduce a scene prompt encoder that integrates visual scene prompts directly into the synthesis pipeline to control the speech generation process. Additionally, we propose a reverberation classification and refinement technique that adjusts the synthesized mel-spectrogram to enhance the immersive experience, ensuring that the involved reverberation condition matches the scene accurately. Experimental results demonstrate that our model achieves high-quality scene and spatial matching without compromising speech naturalness, marking a significant advancement in the field of context-aware speech synthesis. Project demo page: https://spatialTTS.github.io/ Index Terms-Speech synthesis, scene prompt, spatial perception
SAV-SE: Scene-aware Audio-Visual Speech Enhancement with Selective State Space Model
Nov 12, 2024
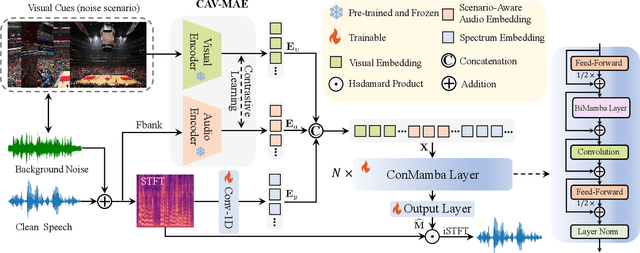

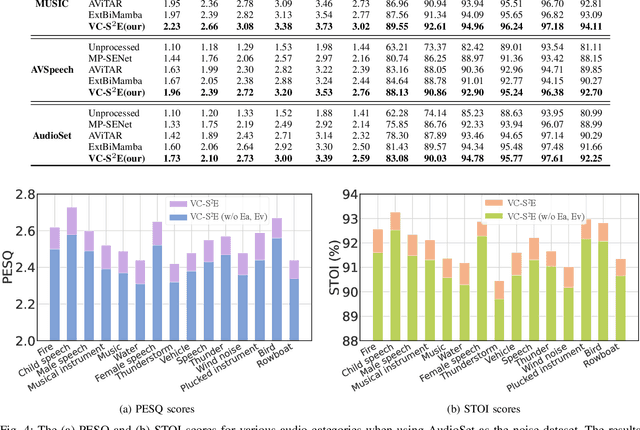
Speech enhancement plays an essential role in various applications, and the integration of visual information has been demonstrated to bring substantial advantages. However, the majority of current research concentrates on the examination of facial and lip movements, which can be compromised or entirely inaccessible in scenarios where occlusions occur or when the camera view is distant. Whereas contextual visual cues from the surrounding environment have been overlooked: for example, when we see a dog bark, our brain has the innate ability to discern and filter out the barking noise. To this end, in this paper, we introduce a novel task, i.e. SAV-SE. To our best knowledge, this is the first proposal to use rich contextual information from synchronized video as auxiliary cues to indicate the type of noise, which eventually improves the speech enhancement performance. Specifically, we propose the VC-S$^2$E method, which incorporates the Conformer and Mamba modules for their complementary strengths. Extensive experiments are conducted on public MUSIC, AVSpeech and AudioSet datasets, where the results demonstrate the superiority of VC-S$^2$E over other competitive methods. We will make the source code publicly available. Project demo page: https://AVSEPage.github.io/