 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWST: Weakly Supervised Transducer for Automatic Speech Recognition
Nov 06, 2025The Recurrent Neural Network-Transducer (RNN-T) is widely adopted in end-to-end (E2E) automatic speech recognition (ASR) tasks but depends heavily on large-scale, high-quality annotated data, which are often costly and difficult to obtain. To mitigate this reliance, we propose a Weakly Supervised Transducer (WST), which integrates a flexible training graph designed to robustly handle errors in the transcripts without requiring additional confidence estimation or auxiliary pre-trained models. Empirical evaluations on synthetic and industrial datasets reveal that WST effectively maintains performance even with transcription error rates of up to 70%, consistently outperforming existing Connectionist Temporal Classification (CTC)-based weakly supervised approaches, such as Bypass Temporal Classification (BTC) and Omni-Temporal Classification (OTC). These results demonstrate the practical utility and robustness of WST in realistic ASR settings. The implementation will be publicly available.
SAV-SE: Scene-aware Audio-Visual Speech Enhancement with Selective State Space Model
Nov 12, 2024
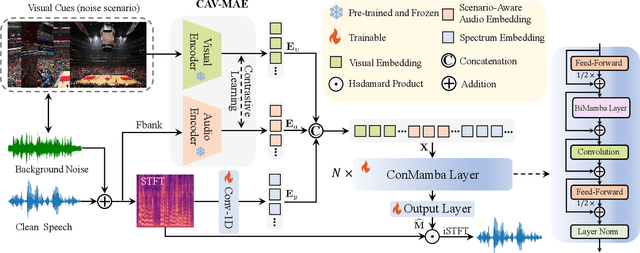

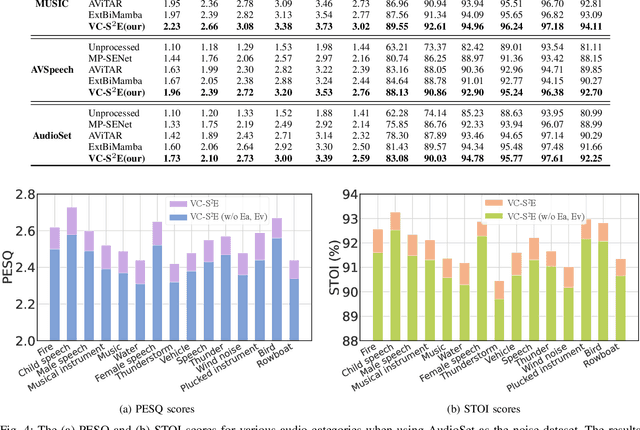
Speech enhancement plays an essential role in various applications, and the integration of visual information has been demonstrated to bring substantial advantages. However, the majority of current research concentrates on the examination of facial and lip movements, which can be compromised or entirely inaccessible in scenarios where occlusions occur or when the camera view is distant. Whereas contextual visual cues from the surrounding environment have been overlooked: for example, when we see a dog bark, our brain has the innate ability to discern and filter out the barking noise. To this end, in this paper, we introduce a novel task, i.e. SAV-SE. To our best knowledge, this is the first proposal to use rich contextual information from synchronized video as auxiliary cues to indicate the type of noise, which eventually improves the speech enhancement performance. Specifically, we propose the VC-S$^2$E method, which incorporates the Conformer and Mamba modules for their complementary strengths. Extensive experiments are conducted on public MUSIC, AVSpeech and AudioSet datasets, where the results demonstrate the superiority of VC-S$^2$E over other competitive methods. We will make the source code publicly available. Project demo page: https://AVSEPage.github.io/
Aligning Speech to Languages to Enhance Code-switching Speech Recognition
Mar 09, 2024



Code-switching (CS) refers to the switching of languages within a speech signal and results in language confusion for automatic speech recognition (ASR). To address language confusion, we propose the language alignment loss that performs frame-level language identification using pseudo language labels learned from the ASR decoder. This eliminates the need for frame-level language annotations. To further tackle the complex token alternatives for language modeling in bilingual scenarios, we propose to employ large language models via a generative error correction method. A linguistic hint that incorporates language information (derived from the proposed language alignment loss and decoded hypotheses) is introduced to guide the prompting of large language models. The proposed methods are evaluated on the SEAME dataset and data from the ASRU 2019 Mandarin-English code-switching speech recognition challenge. The incorporation of the proposed language alignment loss demonstrates a higher CS-ASR performance with only a negligible increase in the number of parameters on both datasets compared to the baseline model. This work also highlights the efficacy of language alignment loss in balancing primary-language-dominant bilingual data during training, with an 8.6% relative improvement on the ASRU dataset compared to the baseline model. Performance evaluation using large language models reveals the advantage of the linguistic hint by achieving 14.1% and 5.5% relative improvement on test sets of the ASRU and SEAME datasets, respectively.
Speaking in Wavelet Domain: A Simple and Efficient Approach to Speed up Speech Diffusion Model
Feb 16, 2024



Recently, Denoising Diffusion Probabilistic Models (DDPMs) have attained leading performances across a diverse range of generative tasks. However, in the field of speech synthesis, although DDPMs exhibit impressive performance, their long training duration and substantial inference costs hinder practical deployment. Existing approaches primarily focus on enhancing inference speed, while approaches to accelerate training a key factor in the costs associated with adding or customizing voices often necessitate complex modifications to the model, compromising their universal applicability. To address the aforementioned challenges, we propose an inquiry: is it possible to enhance the training/inference speed and performance of DDPMs by modifying the speech signal itself? In this paper, we double the training and inference speed of Speech DDPMs by simply redirecting the generative target to the wavelet domain. This method not only achieves comparable or superior performance to the original model in speech synthesis tasks but also demonstrates its versatility. By investigating and utilizing different wavelet bases, our approach proves effective not just in speech synthesis, but also in speech enhancement.
A Quantitative Approach to Understand Self-Supervised Models as Cross-lingual Feature Extractors
Nov 27, 2023



In this work, we study the features extracted by English self-supervised learning (SSL) models in cross-lingual contexts and propose a new metric to predict the quality of feature representations. Using automatic speech recognition (ASR) as a downstream task, we analyze the effect of model size, training objectives, and model architecture on the models' performance as a feature extractor for a set of topologically diverse corpora. We develop a novel metric, the Phonetic-Syntax Ratio (PSR), to measure the phonetic and synthetic information in the extracted representations using deep generalized canonical correlation analysis. Results show the contrastive loss in the wav2vec2.0 objective facilitates more effective cross-lingual feature extraction. There is a positive correlation between PSR scores and ASR performance, suggesting that phonetic information extracted by monolingual SSL models can be used for downstream tasks in cross-lingual settings. The proposed metric is an effective indicator of the quality of the representations and can be useful for model selection.
Enhancing Code-switching Speech Recognition with Interactive Language Biases
Sep 29, 2023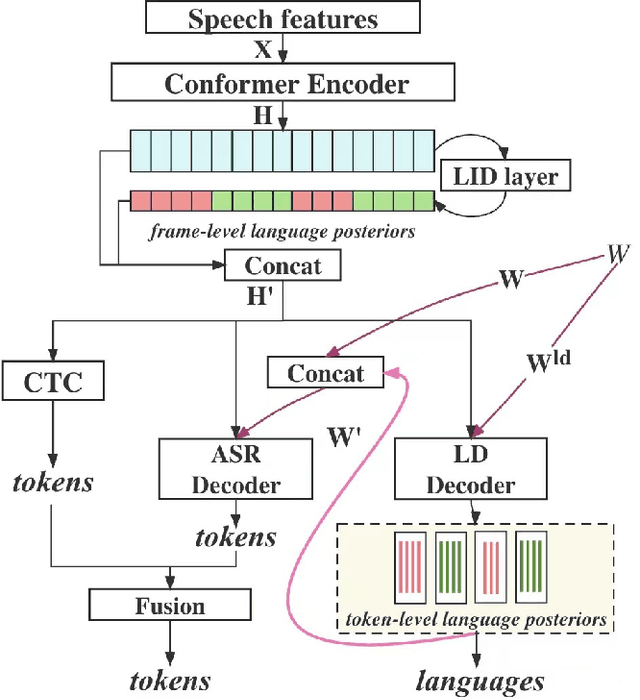

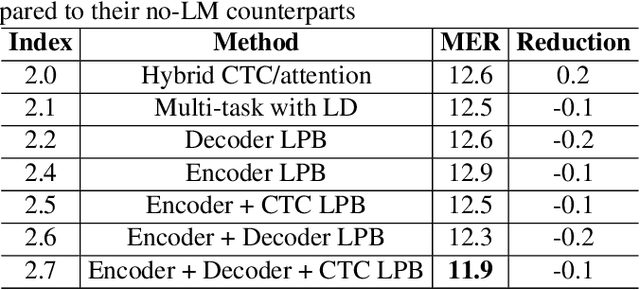
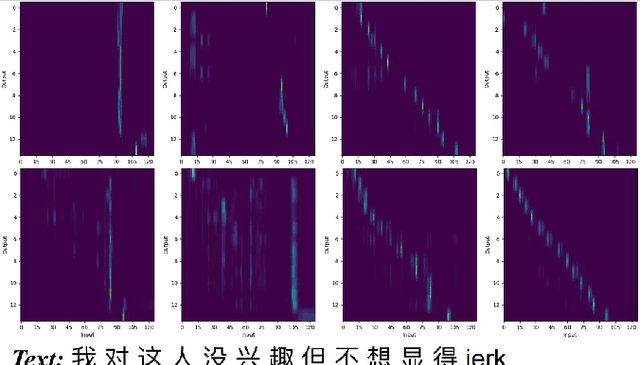
Languages usually switch within a multilingual speech signal, especially in a bilingual society. This phenomenon is referred to as code-switching (CS), making automatic speech recognition (ASR) challenging under a multilingual scenario. We propose to improve CS-ASR by biasing the hybrid CTC/attention ASR model with multi-level language information comprising frame- and token-level language posteriors. The interaction between various resolutions of language biases is subsequently explored in this work. We conducted experiments on datasets from the ASRU 2019 code-switching challenge. Compared to the baseline, the proposed interactive language biases (ILB) method achieves higher performance and ablation studies highlight the effects of different language biases and their interactions. In addition, the results presented indicate that language bias implicitly enhances internal language modeling, leading to performance degradation after employing an external language model.
Unidirectional brain-computer interface: Artificial neural network encoding natural images to fMRI response in the visual cortex
Sep 26, 2023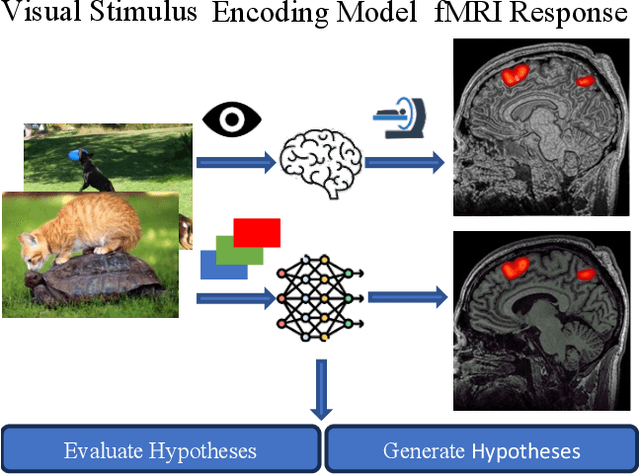

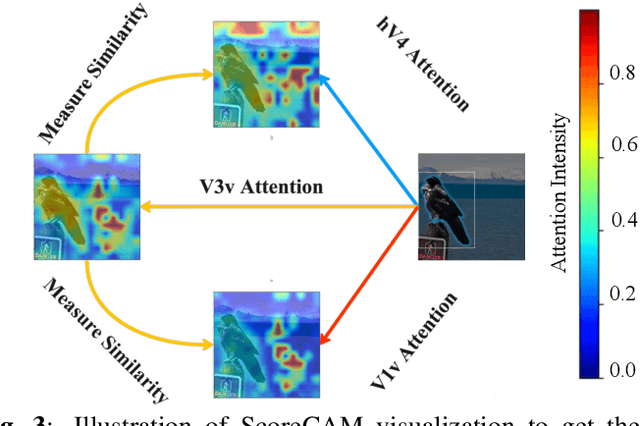
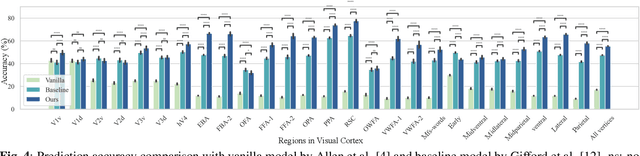
While significant advancements in artificial intelligence (AI) have catalyzed progress across various domains, its full potential in understanding visual perception remains underexplored. We propose an artificial neural network dubbed VISION, an acronym for "Visual Interface System for Imaging Output of Neural activity," to mimic the human brain and show how it can foster neuroscientific inquiries. Using visual and contextual inputs, this multimodal model predicts the brain's functional magnetic resonance imaging (fMRI) scan response to natural images. VISION successfully predicts human hemodynamic responses as fMRI voxel values to visual inputs with an accuracy exceeding state-of-the-art performance by 45%. We further probe the trained networks to reveal representational biases in different visual areas, generate experimentally testable hypotheses, and formulate an interpretable metric to associate these hypotheses with cortical functions. With both a model and evaluation metric, the cost and time burdens associated with designing and implementing functional analysis on the visual cortex could be reduced. Our work suggests that the evolution of computational models may shed light on our fundamental understanding of the visual cortex and provide a viable approach toward reliable brain-machine interfaces.
Bypass Temporal Classification: Weakly Supervised Automatic Speech Recognition with Imperfect Transcripts
Jun 01, 2023
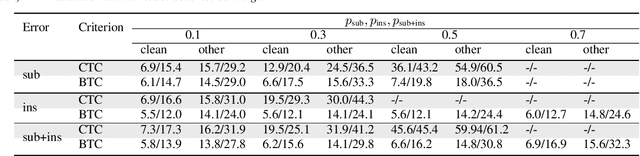
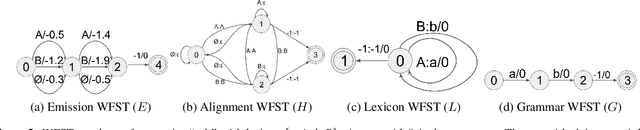
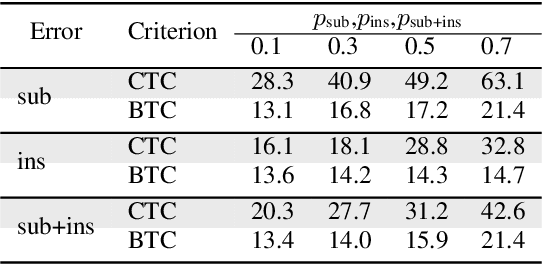
This paper presents a novel algorithm for building an automatic speech recognition (ASR) model with imperfect training data. Imperfectly transcribed speech is a prevalent issue in human-annotated speech corpora, which degrades the performance of ASR models. To address this problem, we propose Bypass Temporal Classification (BTC) as an expansion of the Connectionist Temporal Classification (CTC) criterion. BTC explicitly encodes the uncertainties associated with transcripts during training. This is accomplished by enhancing the flexibility of the training graph, which is implemented as a weighted finite-state transducer (WFST) composition. The proposed algorithm improves the robustness and accuracy of ASR systems, particularly when working with imprecisely transcribed speech corpora. Our implementation will be open-sourced.
EURO: ESPnet Unsupervised ASR Open-source Toolkit
Dec 01, 2022



This paper describes the ESPnet Unsupervised ASR Open-source Toolkit (EURO), an end-to-end open-source toolkit for unsupervised automatic speech recognition (UASR). EURO adopts the state-of-the-art UASR learning method introduced by the Wav2vec-U, originally implemented at FAIRSEQ, which leverages self-supervised speech representations and adversarial training. In addition to wav2vec2, EURO extends the functionality and promotes reproducibility for UASR tasks by integrating S3PRL and k2, resulting in flexible frontends from 27 self-supervised models and various graph-based decoding strategies. EURO is implemented in ESPnet and follows its unified pipeline to provide UASR recipes with a complete setup. This improves the pipeline's efficiency and allows EURO to be easily applied to existing datasets in ESPnet. Extensive experiments on three mainstream self-supervised models demonstrate the toolkit's effectiveness and achieve state-of-the-art UASR performance on TIMIT and LibriSpeech datasets. EURO will be publicly available at https://github.com/espnet/espnet, aiming to promote this exciting and emerging research area based on UASR through open-source activity.
Reducing Language confusion for Code-switching Speech Recognition with Token-level Language Diarization
Oct 26, 2022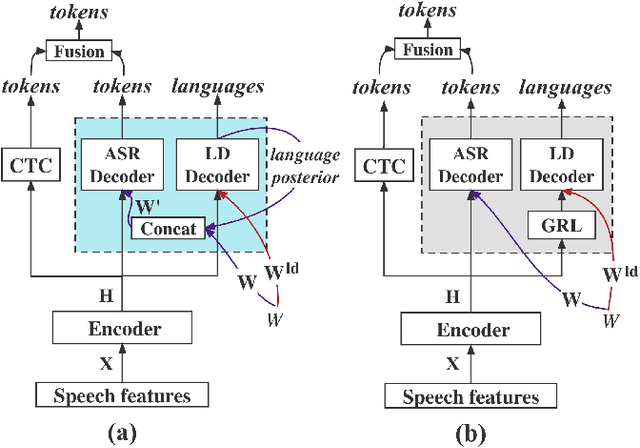
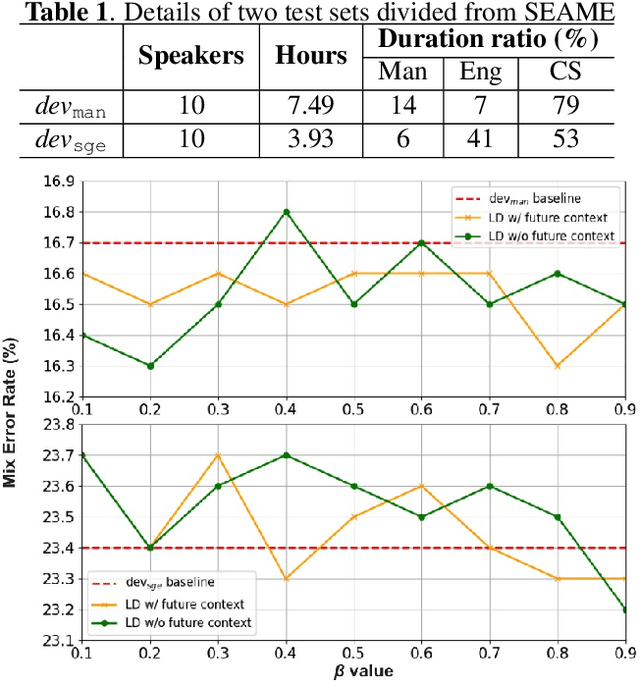
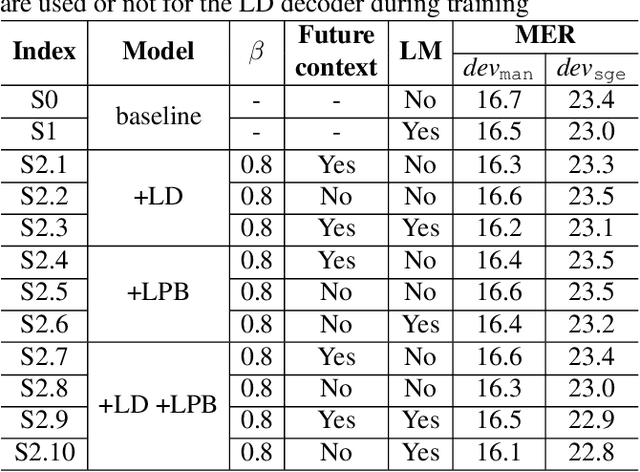
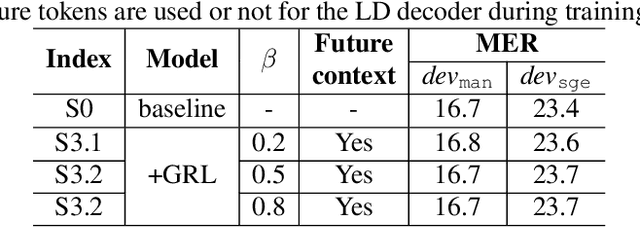
Code-switching (CS) refers to the phenomenon that languages switch within a speech signal and leads to language confusion for automatic speech recognition (ASR). This paper aims to address language confusion for improving CS-ASR from two perspectives: incorporating and disentangling language information. We incorporate language information in the CS-ASR model by dynamically biasing the model with token-level language posteriors which are outputs of a sequence-to-sequence auxiliary language diarization module. In contrast, the disentangling process reduces the difference between languages via adversarial training so as to normalize two languages. We conduct the experiments on the SEAME dataset. Compared to the baseline model, both the joint optimization with LD and the language posterior bias achieve performance improvement. The comparison of the proposed methods indicates that incorporating language information is more effective than disentangling for reducing language confusion in CS speech.