 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Language confusion for Code-switching Speech Recognition with Token-level Language Diarization
Paper and Code
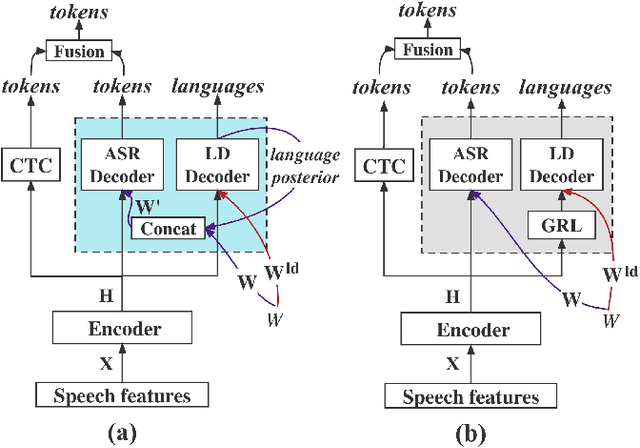
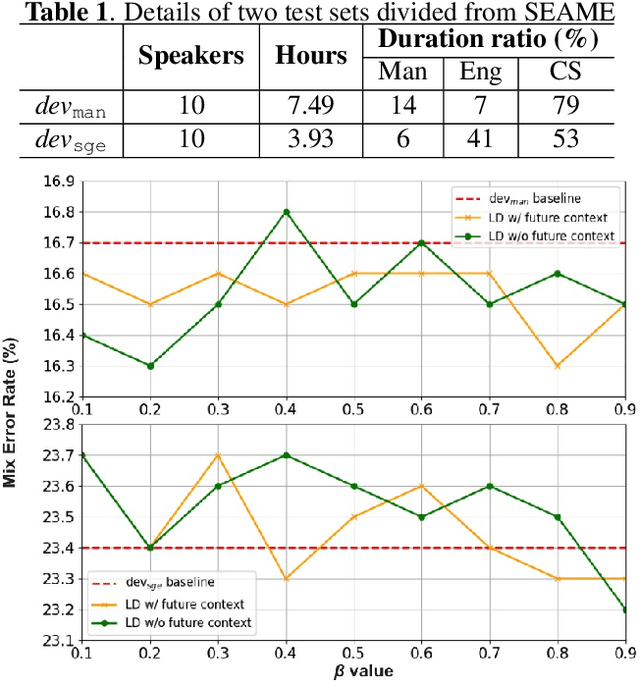
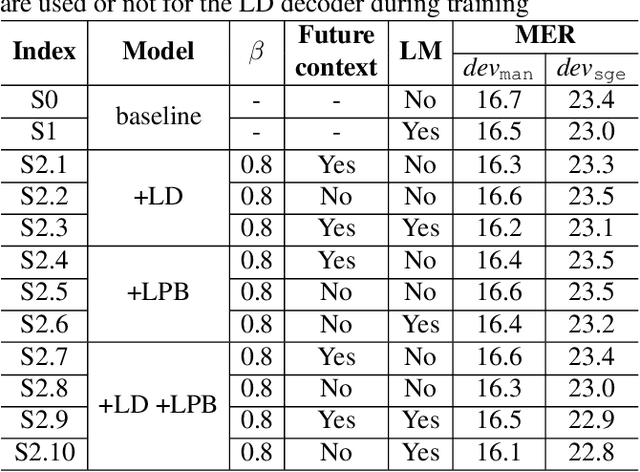
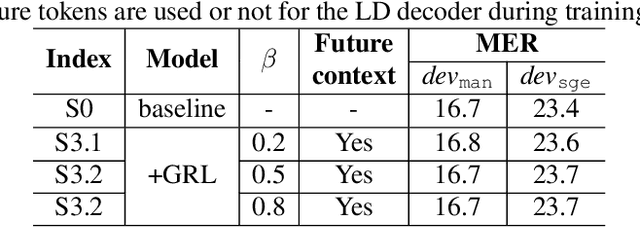
Code-switching (CS) refers to the phenomenon that languages switch within a speech signal and leads to language confusion for automatic speech recognition (ASR). This paper aims to address language confusion for improving CS-ASR from two perspectives: incorporating and disentangling language information. We incorporate language information in the CS-ASR model by dynamically biasing the model with token-level language posteriors which are outputs of a sequence-to-sequence auxiliary language diarization module. In contrast, the disentangling process reduces the difference between languages via adversarial training so as to normalize two languages. We conduct the experiments on the SEAME dataset. Compared to the baseline model, both the joint optimization with LD and the language posterior bias achieve performance improvement. The comparison of the proposed methods indicates that incorporating language information is more effective than disentangling for reducing language confusion in CS speech.