 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Oracle to Noisy Context: Mitigating Contextual Exposure Bias in Speech-LLMs
Mar 25, 2026Contextual automatic speech recognition (ASR) with Speech-LLMs is typically trained with oracle conversation history, but relies on error-prone history at inference, causing a train-test mismatch in the context channel that we term contextual exposure bias. We propose a unified training framework to improve robustness under realistic histories: (i) Teacher Error Knowledge by using Whisper large-v3 hypotheses as training-time history, (ii) Context Dropout to regularize over-reliance on history, and (iii) Direct Preference Optimization (DPO) on curated failure cases. Experiments on TED-LIUM 3 (in-domain) and zero-shot LibriSpeech (out-of-domain) show consistent gains under predicted-history decoding. With a two-utterance history as context, SFT with Whisper hypotheses reduce WER from 5.59% (oracle-history training) to 5.47%, and DPO further improves to 5.17%. Under irrelevant-context attacks, DPO yields the smallest degradation (5.17% -> 5.63%), indicating improved robustness to misleading context. Our code and models are published on https://github.com/XYGuo1996/Contextual_Speech_LLMs.
Internal Language Model Estimation based Adaptive Language Model Fusion for Domain Adaptation
Nov 02, 2022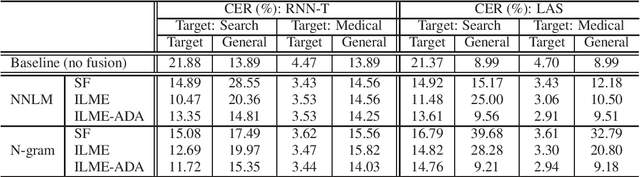
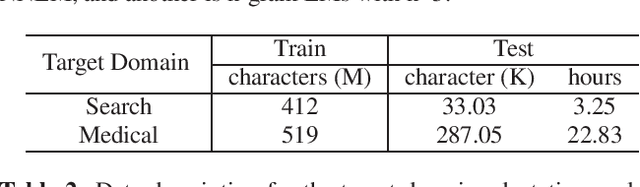
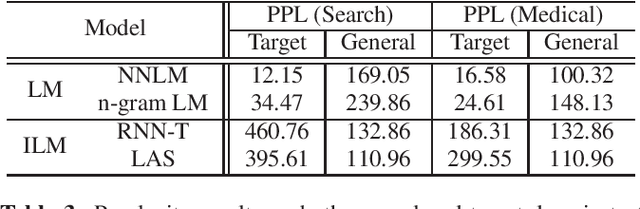
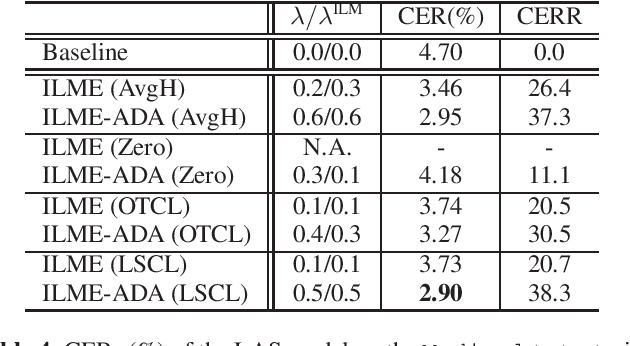
ASR model deployment environment is ever-changing, and the incoming speech can be switched across different domains during a session. This brings a challenge for effective domain adaptation when only target domain text data is available, and our objective is to obtain obviously improved performance on the target domain while the performance on the general domain is less undermined. In this paper, we propose an adaptive LM fusion approach called internal language model estimation based adaptive domain adaptation (ILME-ADA). To realize such an ILME-ADA, an interpolated log-likelihood score is calculated based on the maximum of the scores from the internal LM and the external LM (ELM) respectively. We demonstrate the efficacy of the proposed ILME-ADA method with both RNN-T and LAS modeling frameworks employing neural network and n-gram LMs as ELMs respectively on two domain specific (target) test sets. The proposed method can achieve significantly better performance on the target test sets while it gets minimal performance degradation on the general test set, compared with both shallow and ILME-based LM fusion methods.
Speech-text based multi-modal training with bidirectional attention for improved speech recognition
Nov 01, 2022To let the state-of-the-art end-to-end ASR model enjoy data efficiency, as well as much more unpaired text data by multi-modal training, one needs to address two problems: 1) the synchronicity of feature sampling rates between speech and language (aka text data); 2) the homogeneity of the learned representations from two encoders. In this paper we propose to employ a novel bidirectional attention mechanism (BiAM) to jointly learn both ASR encoder (bottom layers) and text encoder with a multi-modal learning method. The BiAM is to facilitate feature sampling rate exchange, realizing the quality of the transformed features for the one kind to be measured in another space, with diversified objective functions. As a result, the speech representations are enriched with more linguistic information, while the representations generated by the text encoder are more similar to corresponding speech ones, and therefore the shared ASR models are more amenable for unpaired text data pretraining. To validate the efficacy of the proposed method, we perform two categories of experiments with or without extra unpaired text data. Experimental results on Librispeech corpus show it can achieve up to 6.15% word error rate reduction (WERR) with only paired data learning, while 9.23% WERR when more unpaired text data is employed.
Improving short-video speech recognition using random utterance concatenation
Oct 28, 2022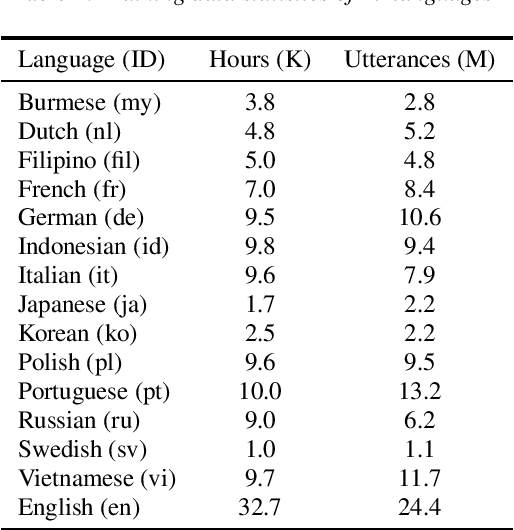
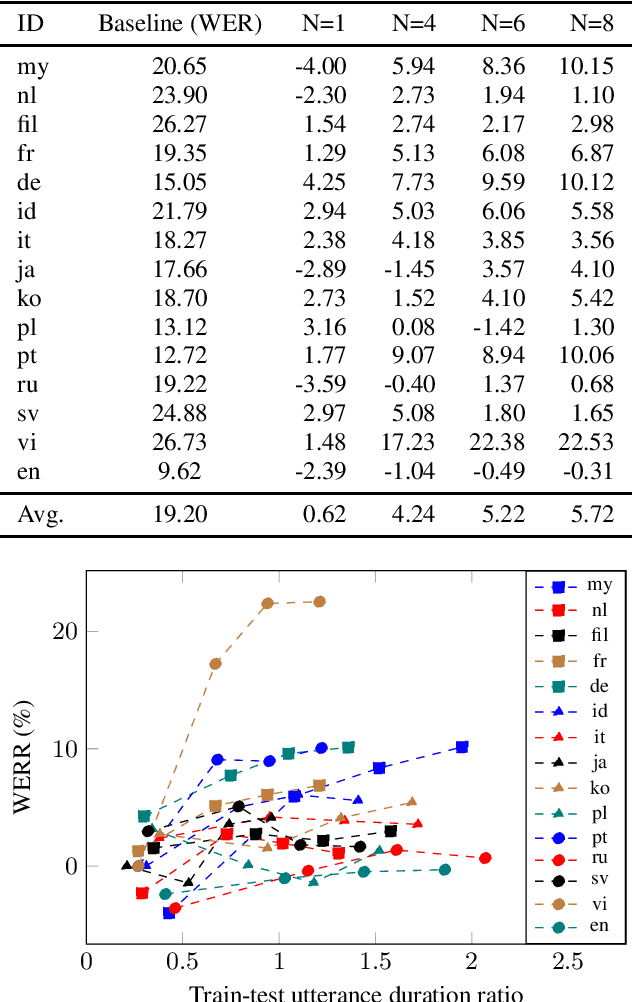
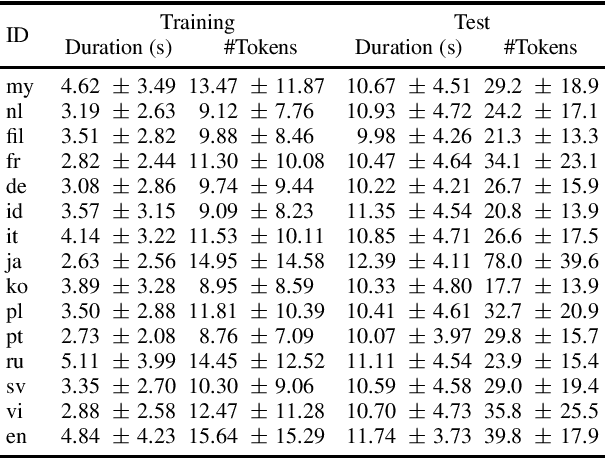
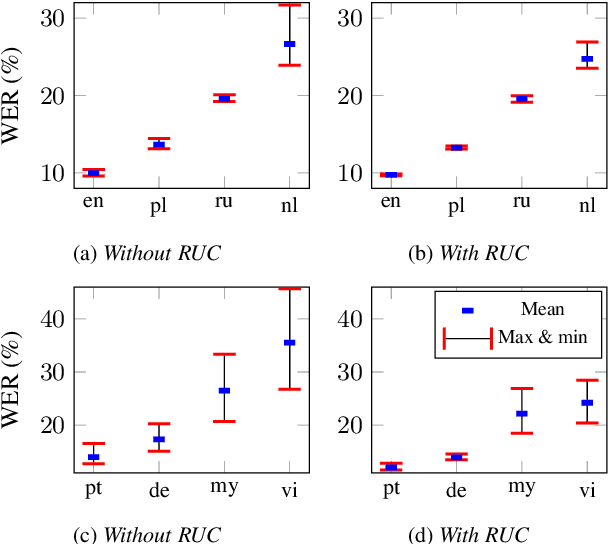
One of the limitations in end-to-end automatic speech recognition framework is its performance would be compromised if train-test utterance lengths are mismatched. In this paper, we propose a random utterance concatenation (RUC) method to alleviate train-test utterance length mismatch issue for short-video speech recognition task. Specifically, we are motivated by observations our human-transcribed training utterances tend to be much shorter for short-video spontaneous speech (~3 seconds on average), while our test utterance generated from voice activity detection front-end is much longer (~10 seconds on average). Such a mismatch can lead to sub-optimal performance. Experimentally, by using the proposed RUC method, the best word error rate reduction (WERR) can be achieved with around three fold training data size increase as well as two utterance concatenation for each. In practice, the proposed method consistently outperforms the strong baseline models, where 3.64% average WERR is achieved on 14 languages.
Reducing Language confusion for Code-switching Speech Recognition with Token-level Language Diarization
Oct 26, 2022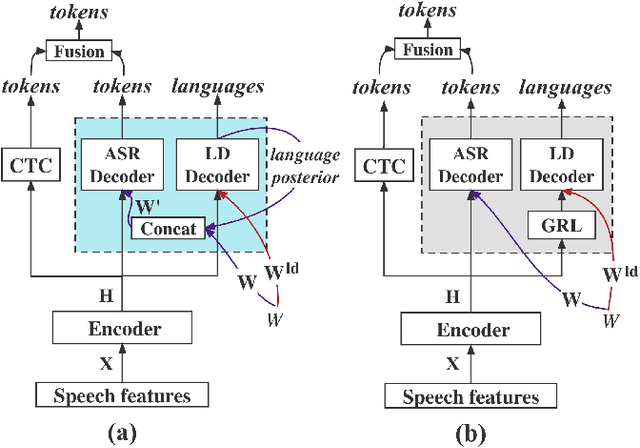
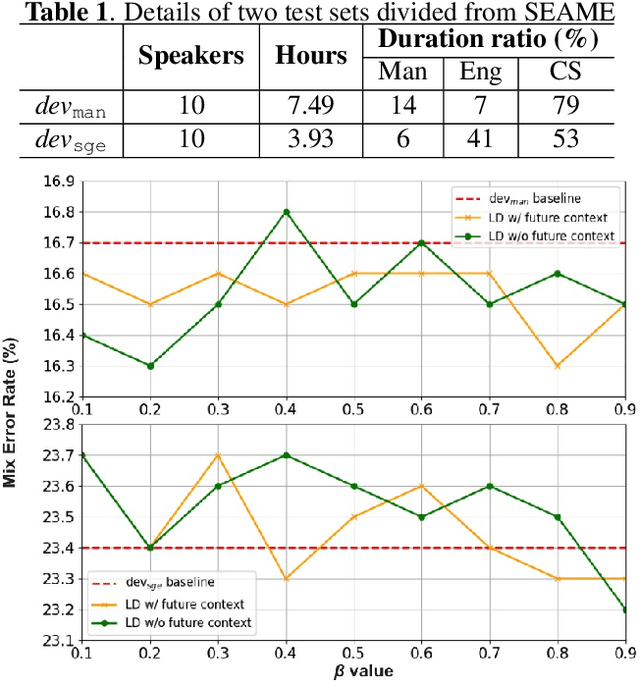
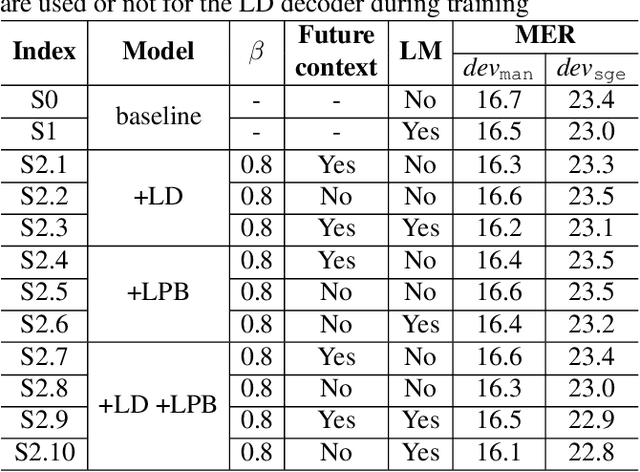
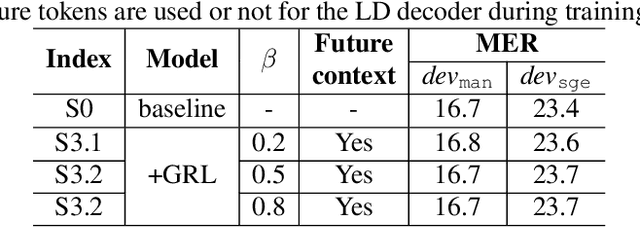
Code-switching (CS) refers to the phenomenon that languages switch within a speech signal and leads to language confusion for automatic speech recognition (ASR). This paper aims to address language confusion for improving CS-ASR from two perspectives: incorporating and disentangling language information. We incorporate language information in the CS-ASR model by dynamically biasing the model with token-level language posteriors which are outputs of a sequence-to-sequence auxiliary language diarization module. In contrast, the disentangling process reduces the difference between languages via adversarial training so as to normalize two languages. We conduct the experiments on the SEAME dataset. Compared to the baseline model, both the joint optimization with LD and the language posterior bias achieve performance improvement. The comparison of the proposed methods indicates that incorporating language information is more effective than disentangling for reducing language confusion in CS speech.
Intermediate-layer output Regularization for Attention-based Speech Recognition with Shared Decoder
Jul 09, 2022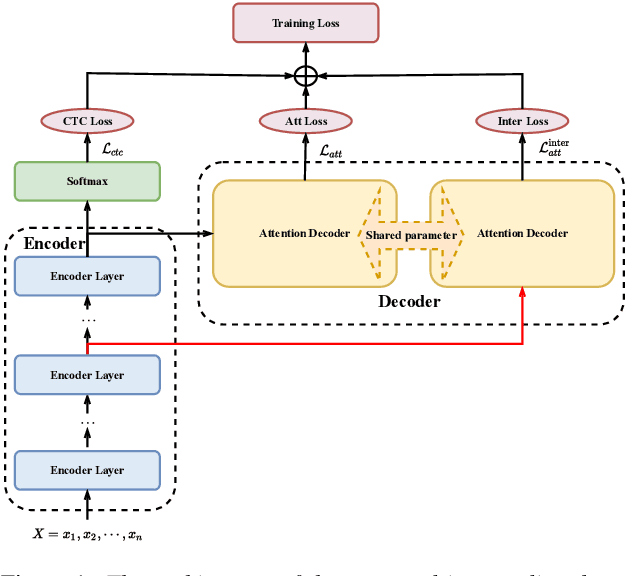
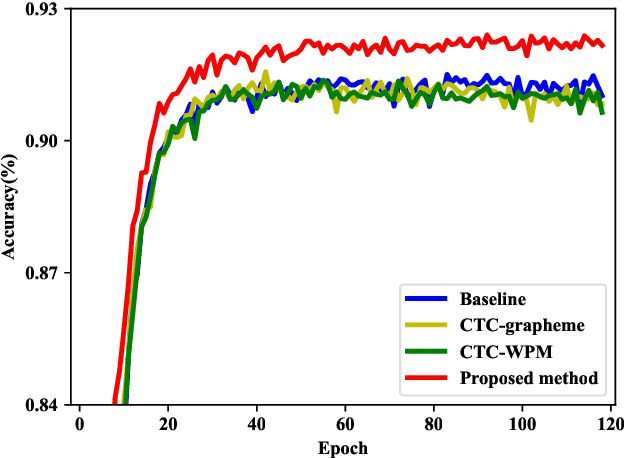
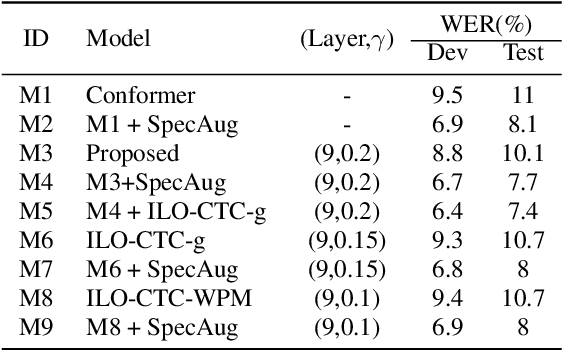
Intermediate layer output (ILO) regularization by means of multitask training on encoder side has been shown to be an effective approach to yielding improved results on a wide range of end-to-end ASR frameworks. In this paper, we propose a novel method to do ILO regularized training differently. Instead of using conventional multitask methods that entail more training overhead, we directly make the intermediate layer output as input to the decoder, that is, our decoder not only accepts the output of the final encoder layer as input, it also takes the output of the encoder ILO as input during training. With the proposed method, as both encoder and decoder are simultaneously "regularized", the network is more sufficiently trained, consistently leading to improved results, over the ILO-based CTC method, as well as over the original attention-based modeling method without the proposed method employed.
Internal Language Model Estimation based Language Model Fusion for Cross-Domain Code-Switching Speech Recognition
Jul 09, 2022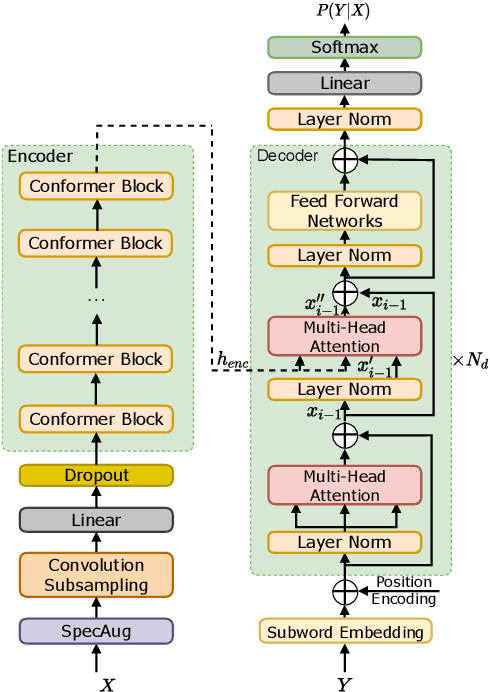
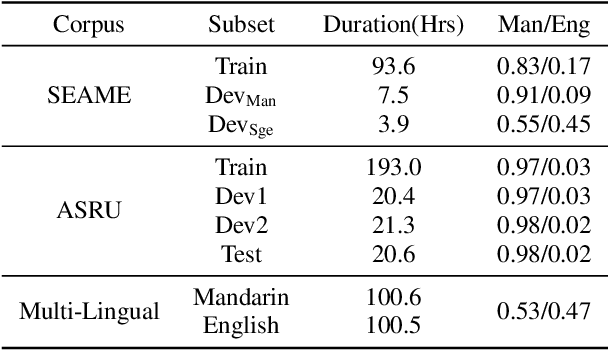
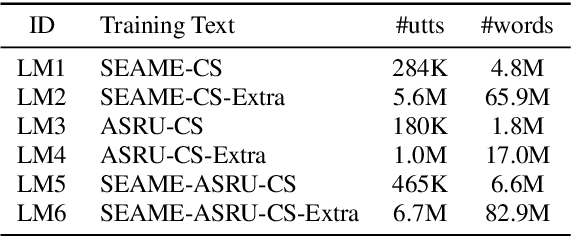
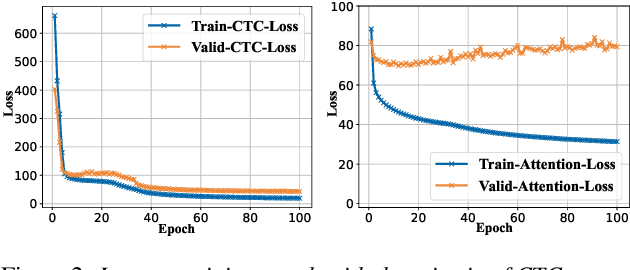
Internal Language Model Estimation (ILME) based language model (LM) fusion has been shown significantly improved recognition results over conventional shallow fusion in both intra-domain and cross-domain speech recognition tasks. In this paper, we attempt to apply our ILME method to cross-domain code-switching speech recognition (CSSR) work. Specifically, our curiosity comes from several aspects. First, we are curious about how effective the ILME-based LM fusion is for both intra-domain and cross-domain CSSR tasks. We verify this with or without merging two code-switching domains. More importantly, we train an end-to-end (E2E) speech recognition model by means of merging two monolingual data sets and observe the efficacy of the proposed ILME-based LM fusion for CSSR. Experimental results on SEAME that is from Southeast Asian and another Chinese Mainland CS data set demonstrate the effectiveness of the proposed ILME-based LM fusion method.
Internal language model estimation through explicit context vector learning for attention-based encoder-decoder ASR
Jan 26, 2022
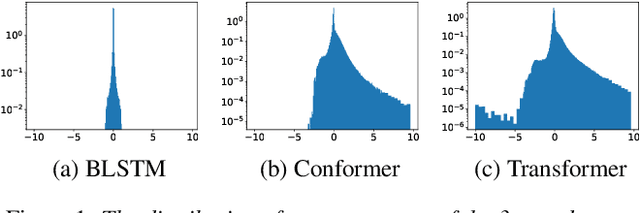
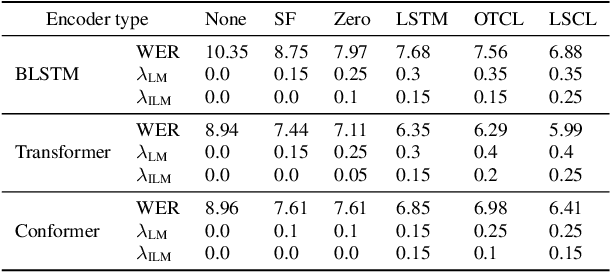

An end-to-end (E2E) speech recognition model implicitly learns a biased internal language model (ILM) during training. To fused an external LM during inference, the scores produced by the biased ILM need to be estimated and subtracted. In this paper we propose two novel approaches to estimate the biased ILM based on Listen-Attend-Spell (LAS) models. The simpler method is to replace the context vector of the LAS decoder at every time step with a learnable vector. The other more advanced method is to use a simple feed-forward network to directly map query vectors to context vectors, making the generation of the context vectors independent of the LAS encoder. Both the learnable vector and the mapping network are trained on the transcriptions of the training data to minimize the perplexity while all the other parameters of the LAS model is fixed. Experiments show that the ILMs estimated by the proposed methods achieve the lowest perplexity. In addition, they also significantly outperform the shallow fusion method and two previously proposed Internal Language Model Estimation (ILME) approaches on multiple datasets.
Minimum word error training for non-autoregressive Transformer-based code-switching ASR
Oct 07, 2021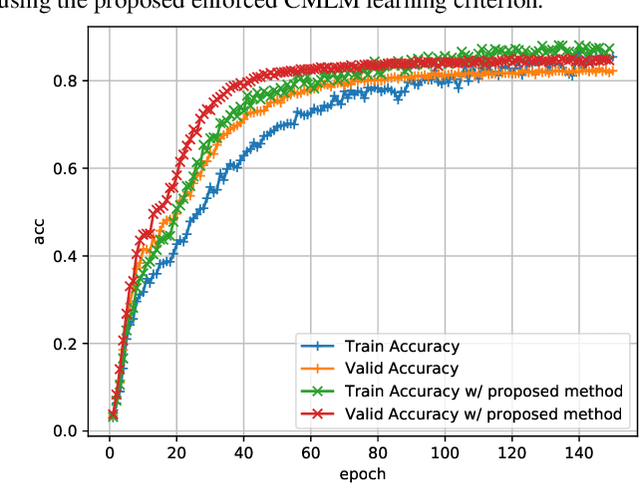
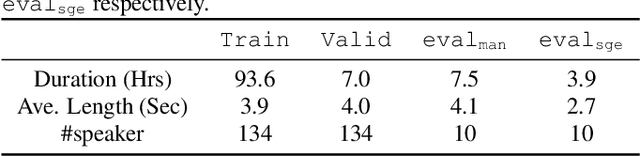

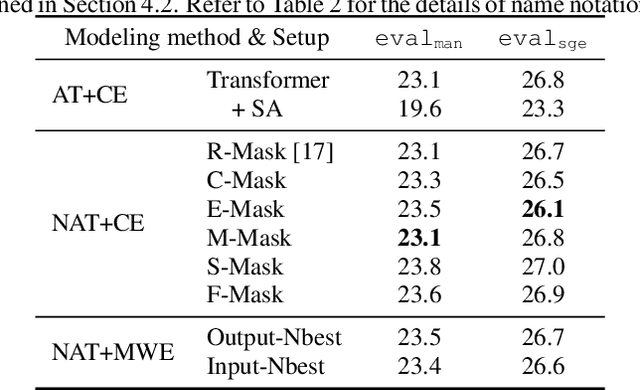
Non-autoregressive end-to-end ASR framework might be potentially appropriate for code-switching recognition task thanks to its inherent property that present output token being independent of historical ones. However, it still under-performs the state-of-the-art autoregressive ASR frameworks. In this paper, we propose various approaches to boosting the performance of a CTC-mask-based nonautoregressive Transformer under code-switching ASR scenario. To begin with, we attempt diversified masking method that are closely related with code-switching point, yielding an improved baseline model. More importantly, we employ MinimumWord Error (MWE) criterion to train the model. One of the challenges is how to generate a diversified hypothetical space, so as to obtain the average loss for a given ground truth. To address such a challenge, we explore different approaches to yielding desired N-best-based hypothetical space. We demonstrate the efficacy of the proposed methods on SEAME corpus, a challenging English-Mandarin code-switching corpus for Southeast Asia community. Compared with the crossentropy-trained strong baseline, the proposed MWE training method achieves consistent performance improvement on the test sets.
Multitask-Based Joint Learning Approach To Robust ASR For Radio Communication Speech
Jul 22, 2021
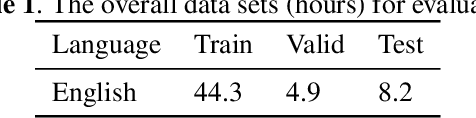


To realize robust end-to-end Automatic Speech Recognition(E2E ASR) under radio communication condition, we propose a multitask-based method to joint train a Speech Enhancement (SE) module as the front-end and an E2E ASR model as the back-end in this paper. One of the advantage of the proposed method is that the entire system can be trained from scratch. Different from prior works, either component here doesn't need to perform pre-training and fine-tuning processes separately. Through analysis, we found that the success of the proposed method lies in the following aspects. Firstly, multitask learning is essential, that is the SE network is not only learning to produce more Intelligent speech, it is also aimed to generate speech that is beneficial to recognition. Secondly, we also found speech phase preserved from noisy speech is critical for improving ASR performance. Thirdly, we propose a dual channel data augmentation training method to obtain further improvement.Specifically, we combine the clean and enhanced speech to train the whole system. We evaluate the proposed method on the RATS English data set, achieving a relative WER reduction of 4.6% with the joint training method, and up to a relative WER reduction of 11.2% with the proposed data augmentation method.