 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Center Study on Deep Learning-Assisted Detection and Classification of Fetal Central Nervous System Anomalies Using Ultrasound Imaging
Jan 01, 2025



Prenatal ultrasound evaluates fetal growth and detects congenital abnormalities during pregnancy, but the examination of ultrasound images by radiologists requires expertise and sophisticated equipment, which would otherwise fail to improve the rate of identifying specific types of fetal central nervous system (CNS) abnormalities and result in unnecessary patient examinations. We construct a deep learning model to improve the overall accuracy of the diagnosis of fetal cranial anomalies to aid prenatal diagnosis. In our collected multi-center dataset of fetal craniocerebral anomalies covering four typical anomalies of the fetal central nervous system (CNS): anencephaly, encephalocele (including meningocele), holoprosencephaly, and rachischisis, patient-level prediction accuracy reaches 94.5%, with an AUROC value of 99.3%. In the subgroup analyzes, our model is applicable to the entire gestational period, with good identification of fetal anomaly types for any gestational period. Heatmaps superimposed on the ultrasound images not only provide a visual interpretation for the algorithm but also provide an intuitive visual aid to the physician by highlighting key areas that need to be reviewed, helping the physician to quickly identify and validate key areas. Finally, the retrospective reader study demonstrates that by combining the automatic prediction of the DL system with the professional judgment of the radiologist, the diagnostic accuracy and efficiency can be effectively improved and the misdiagnosis rate can be reduced, which has an important clinical application prospect.
Text-guided HuBERT: Self-Supervised Speech Pre-training via Generative Adversarial Networks
Feb 28, 2024



Human language can be expressed in either written or spoken form, i.e. text or speech. Humans can acquire knowledge from text to improve speaking and listening. However, the quest for speech pre-trained models to leverage unpaired text has just started. In this paper, we investigate a new way to pre-train such a joint speech-text model to learn enhanced speech representations and benefit various speech-related downstream tasks. Specifically, we propose a novel pre-training method, text-guided HuBERT, or T-HuBERT, which performs self-supervised learning over speech to derive phoneme-like discrete representations. And these phoneme-like pseudo-label sequences are firstly derived from speech via the generative adversarial networks (GAN) to be statistically similar to those from additional unpaired textual data. In this way, we build a bridge between unpaired speech and text in an unsupervised manner. Extensive experiments demonstrate the significant superiority of our proposed method over various strong baselines, which achieves up to 15.3% relative Word Error Rate (WER) reduction on the LibriSpeech dataset.
Multitask-Based Joint Learning Approach To Robust ASR For Radio Communication Speech
Jul 22, 2021
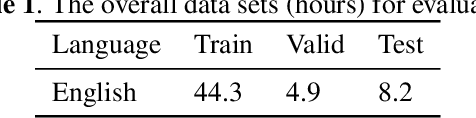


To realize robust end-to-end Automatic Speech Recognition(E2E ASR) under radio communication condition, we propose a multitask-based method to joint train a Speech Enhancement (SE) module as the front-end and an E2E ASR model as the back-end in this paper. One of the advantage of the proposed method is that the entire system can be trained from scratch. Different from prior works, either component here doesn't need to perform pre-training and fine-tuning processes separately. Through analysis, we found that the success of the proposed method lies in the following aspects. Firstly, multitask learning is essential, that is the SE network is not only learning to produce more Intelligent speech, it is also aimed to generate speech that is beneficial to recognition. Secondly, we also found speech phase preserved from noisy speech is critical for improving ASR performance. Thirdly, we propose a dual channel data augmentation training method to obtain further improvement.Specifically, we combine the clean and enhanced speech to train the whole system. We evaluate the proposed method on the RATS English data set, achieving a relative WER reduction of 4.6% with the joint training method, and up to a relative WER reduction of 11.2% with the proposed data augmentation method.