 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting SAM to Nuclei Instance Segmentation and Classification via Cooperative Fine-Grained Refinement
Mar 30, 2026Nuclei instance segmentation is critical in computational pathology for cancer diagnosis and prognosis. Recently, the Segment Anything Model has demonstrated exceptional performance in various segmentation tasks, leveraging its rich priors and powerful global context modeling capabilities derived from large-scale pre-training on natural images. However, directly applying SAM to the medical imaging domain faces significant limitations: it lacks sufficient perception of the local structural features that are crucial for nuclei segmentation, and full fine-tuning for downstream tasks requires substantial computational costs. To efficiently transfer SAM's robust prior knowledge to nuclei instance segmentation while supplementing its task-aware local perception, we propose a parameter-efficient fine-tuning framework, named Cooperative Fine-Grained Refinement of SAM, consisting of three core components: 1) a Multi-scale Adaptive Local-aware Adapter, which enables effective capability transfer by augmenting the frozen SAM backbone with minimal parameters and instilling a powerful perception of local structures through dynamically generated, multi-scale convolutional kernels; 2) a Hierarchical Modulated Fusion Module, which dynamically aggregates multi-level encoder features to preserve fine-grained spatial details; and 3) a Boundary-Guided Mask Refinement, which integrates multi-context boundary cues with semantic features through explicit supervision, producing a boundary-focused signal to refine initial mask predictions for sharper delineation. These three components work cooperatively to enhance local perception, preserve spatial details, and refine boundaries, enabling SAM to perform accurate nuclei instance segmentation directly.
$\mathbf{S^2LM}$: Towards Semantic Steganography via Large Language Models
Nov 07, 2025Although steganography has made significant advancements in recent years, it still struggles to embed semantically rich, sentence-level information into carriers. However, in the era of AIGC, the capacity of steganography is more critical than ever. In this work, we present Sentence-to-Image Steganography, an instance of Semantic Steganography, a novel task that enables the hiding of arbitrary sentence-level messages within a cover image. Furthermore, we establish a benchmark named Invisible Text (IVT), comprising a diverse set of sentence-level texts as secret messages for evaluation. Finally, we present $\mathbf{S^2LM}$: Semantic Steganographic Language Model, which utilizes large language models (LLMs) to embed high-level textual information, such as sentences or even paragraphs, into images. Unlike traditional bit-level counterparts, $\mathrm{S^2LM}$ enables the integration of semantically rich content through a newly designed pipeline in which the LLM is involved throughout the entire process. Both quantitative and qualitative experiments demonstrate that our method effectively unlocks new semantic steganographic capabilities for LLMs. The source code will be released soon.
Multi-Center Study on Deep Learning-Assisted Detection and Classification of Fetal Central Nervous System Anomalies Using Ultrasound Imaging
Jan 01, 2025



Prenatal ultrasound evaluates fetal growth and detects congenital abnormalities during pregnancy, but the examination of ultrasound images by radiologists requires expertise and sophisticated equipment, which would otherwise fail to improve the rate of identifying specific types of fetal central nervous system (CNS) abnormalities and result in unnecessary patient examinations. We construct a deep learning model to improve the overall accuracy of the diagnosis of fetal cranial anomalies to aid prenatal diagnosis. In our collected multi-center dataset of fetal craniocerebral anomalies covering four typical anomalies of the fetal central nervous system (CNS): anencephaly, encephalocele (including meningocele), holoprosencephaly, and rachischisis, patient-level prediction accuracy reaches 94.5%, with an AUROC value of 99.3%. In the subgroup analyzes, our model is applicable to the entire gestational period, with good identification of fetal anomaly types for any gestational period. Heatmaps superimposed on the ultrasound images not only provide a visual interpretation for the algorithm but also provide an intuitive visual aid to the physician by highlighting key areas that need to be reviewed, helping the physician to quickly identify and validate key areas. Finally, the retrospective reader study demonstrates that by combining the automatic prediction of the DL system with the professional judgment of the radiologist, the diagnostic accuracy and efficiency can be effectively improved and the misdiagnosis rate can be reduced, which has an important clinical application prospect.
CovidLLM: A Robust Large Language Model with Missing Value Adaptation and Multi-Objective Learning Strategy for Predicting Disease Severity and Clinical Outcomes in COVID-19 Patients
Nov 28, 2024



Coronavirus Disease 2019 (COVID-19), which emerged in 2019, has caused millions of deaths worldwide. Although effective vaccines have been developed to mitigate severe symptoms, certain populations, particularly the elderly and those with comorbidities, remain at high risk for severe outcomes and increased mortality. Consequently, early identification of the severity and clinical outcomes of the disease in these patients is vital to prevent adverse prognoses. Although traditional machine learning and deep learning models have been widely employed in this area, the potential of large language models (LLMs) remains largely unexplored. Our research focuses primarily on constructing specialized prompts and adopting multi-objective learning strategies. We started by selecting serological indicators that significantly correlate with clinical outcomes and disease severity to serve as input data for the model. Blood test samples often contain numerous missing values, and traditional models generally rely on imputation to handle these gaps in the data. In contrast, LLMs offer the advantage of robust semantic understanding. By setting prompts, we can explicitly inform the model when a feature's value is missing, without the need for imputation. For the multi-objective learning strategy, the model is designed to first predict disease severity and then predict clinical outcomes. Given that LLMs utilize both the input text and the generated tokens as input for generating the next token, the predicted severity is used as a basis for generating the clinical outcome. During the fine-tuning of the LLM, the two objectives influence and improve each other. Our experiments were implemented based on the ChatGLM model. The results demonstrate the effectiveness of LLMs in this task, suggesting promising potential for further development.
Memory-Constrained Semantic Segmentation for Ultra-High Resolution UAV Imagery
Oct 07, 2023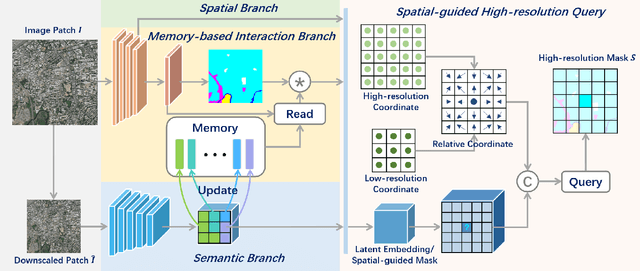
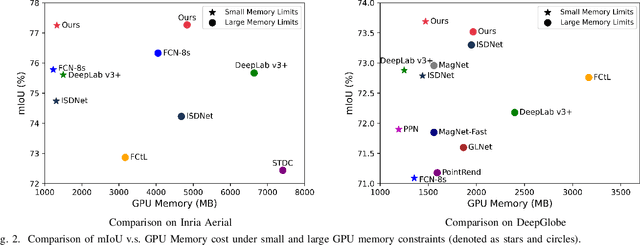
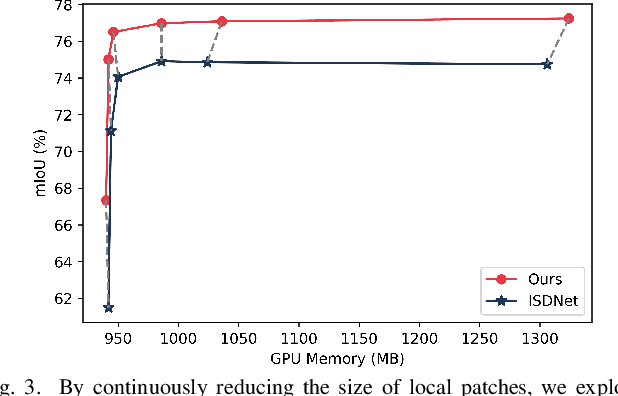

Amidst the swift advancements in photography and sensor technologies, high-definition cameras have become commonplace in the deployment of Unmanned Aerial Vehicles (UAVs) for diverse operational purposes. Within the domain of UAV imagery analysis, the segmentation of ultra-high resolution images emerges as a substantial and intricate challenge, especially when grappling with the constraints imposed by GPU memory-restricted computational devices. This paper delves into the intricate problem of achieving efficient and effective segmentation of ultra-high resolution UAV imagery, while operating under stringent GPU memory limitation. The strategy of existing approaches is to downscale the images to achieve computationally efficient segmentation. However, this strategy tends to overlook smaller, thinner, and curvilinear regions. To address this problem, we propose a GPU memory-efficient and effective framework for local inference without accessing the context beyond local patches. In particular, we introduce a novel spatial-guided high-resolution query module, which predicts pixel-wise segmentation results with high quality only by querying nearest latent embeddings with the guidance of high-resolution information. Additionally, we present an efficient memory-based interaction scheme to correct potential semantic bias of the underlying high-resolution information by associating cross-image contextual semantics. For evaluation of our approach, we perform comprehensive experiments over public benchmarks and achieve superior performance under both conditions of small and large GPU memory usage limitations. We will release the model and codes in the future.
Monocular BEV Perception of Road Scenes via Front-to-Top View Projection
Nov 15, 2022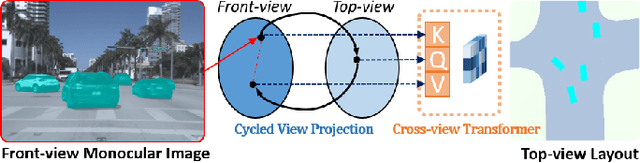



HD map reconstruction is crucial for autonomous driving. LiDAR-based methods are limited due to expensive sensors and time-consuming computation. Camera-based methods usually need to perform road segmentation and view transformation separately, which often causes distortion and missing content. To push the limits of the technology, we present a novel framework that reconstructs a local map formed by road layout and vehicle occupancy in the bird's-eye view given a front-view monocular image only. We propose a front-to-top view projection (FTVP) module, which takes the constraint of cycle consistency between views into account and makes full use of their correlation to strengthen the view transformation and scene understanding. In addition, we also apply multi-scale FTVP modules to propagate the rich spatial information of low-level features to mitigate spatial deviation of the predicted object location. Experiments on public benchmarks show that our method achieves the state-of-the-art performance in the tasks of road layout estimation, vehicle occupancy estimation, and multi-class semantic estimation. For multi-class semantic estimation, in particular, our model outperforms all competitors by a large margin. Furthermore, our model runs at 25 FPS on a single GPU, which is efficient and applicable for real-time panorama HD map reconstruction.
Lung image segmentation by generative adversarial networks
Jul 30, 2019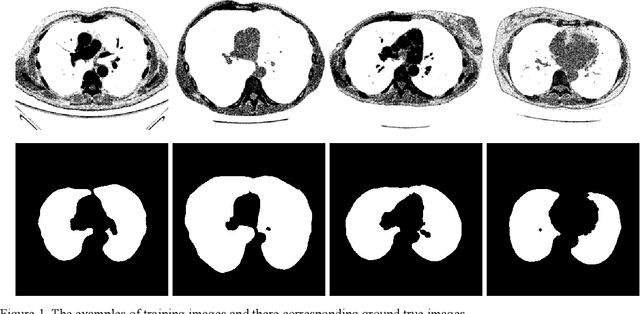
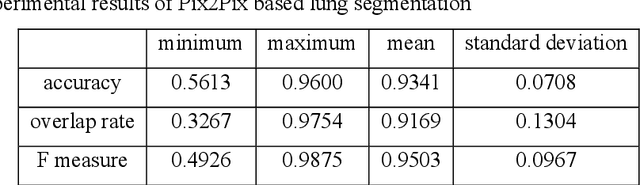
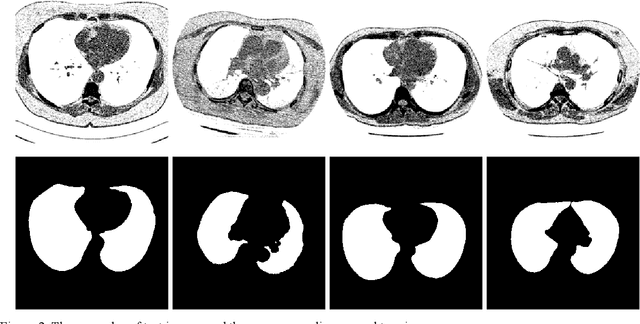

Lung image segmentation plays an important role in computer-aid pulmonary diseases diagnosis and treatment. This paper proposed a lung image segmentation method by generative adversarial networks. We employed a variety of generative adversarial networks and use its capability of image translation to perform image segmentation. The generative adversarial networks was employed to translate the original lung image to the segmented image. The generative adversarial networks based segmentation method was test on real lung image data set. Experimental results shows that the proposed method is effective and outperform state-of-the art method.
RGB Video Based Tennis Action Recognition Using a Deep Historical Long Short-Term Memory
Sep 25, 2018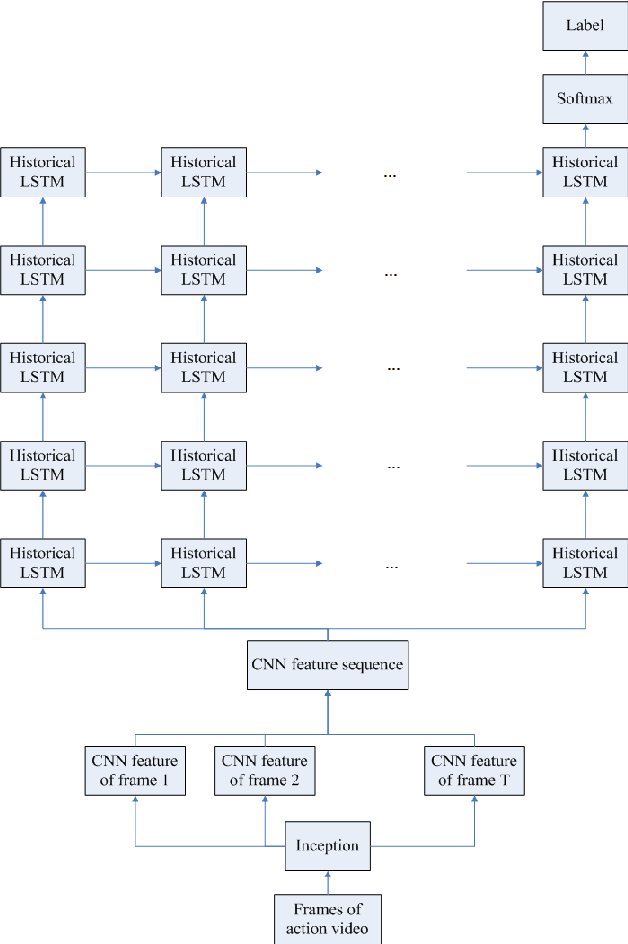



Action recognition has attracted increasing attention from RGB input in computer vision partially due to potential applications on somatic simulation and statistics of sport such as virtual tennis game and tennis techniques and tactics analysis by video. Recently, deep learning based methods have achieved promising performance for action recognition. In this paper, we propose weighted Long Short-Term Memory adopted with convolutional neural network representations for three dimensional tennis shots recognition. First, the local two-dimensional convolutional neural network spatial representations are extracted from each video frame individually using a pre-trained Inception network. Then, a weighted Long Short-Term Memory decoder is introduced to take the output state at time t and the historical embedding feature at time t-1 to generate feature vector using a score weighting scheme. Finally, we use the adopted CNN and weighted LSTM to map the original visual features into a vector space to generate the spatial-temporal semantical description of visual sequences and classify the action video content. Experiments on the benchmark demonstrate that our method using only simple raw RGB video can achieve better performance than the state-of-the-art baselines for tennis shot recognition.