 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReLE: A Scalable System and Structured Benchmark for Diagnosing Capability Anisotropy in Chinese LLMs
Jan 24, 2026Large Language Models (LLMs) have achieved rapid progress in Chinese language understanding, yet accurately evaluating their capabilities remains challenged by benchmark saturation and prohibitive computational costs. While static leaderboards provide snapshot rankings, they often mask the structural trade-offs between capabilities. In this work, we present ReLE (Robust Efficient Live Evaluation), a scalable system designed to diagnose Capability Anisotropy, the non-uniformity of model performance across domains. Using ReLE, we evaluate 304 models (189 commercial, 115 open-source) across a Domain $\times$ Capability orthogonal matrix comprising 207,843 samples. We introduce two methodological contributions to address current evaluation pitfalls: (1) A Symbolic-Grounded Hybrid Scoring Mechanism that eliminates embedding-based false positives in reasoning tasks; (2) A Dynamic Variance-Aware Scheduler based on Neyman allocation with noise correction, which reduces compute costs by 70\% compared to full-pass evaluations while maintaining a ranking correlation of $ρ=0.96$. Our analysis reveals that aggregate rankings are highly sensitive to weighting schemes: models exhibit a Rank Stability Amplitude (RSA) of 11.4 in ReLE versus $\sim$5.0 in traditional benchmarks, confirming that modern models are highly specialized rather than generally superior. We position ReLE not as a replacement for comprehensive static benchmarks, but as a high-frequency diagnostic monitor for the evolving model landscape.
Science Consultant Agent
Dec 18, 2025The Science Consultant Agent is a web-based Artificial Intelligence (AI) tool that helps practitioners select and implement the most effective modeling strategy for AI-based solutions. It operates through four core components: Questionnaire, Smart Fill, Research-Guided Recommendation, and Prototype Builder. By combining structured questionnaires, literature-backed solution recommendations, and prototype generation, the Science Consultant Agent accelerates development for everyone from Product Managers and Software Developers to Researchers. The full pipeline is illustrated in Figure 1.
ECVL-ROUTER: Scenario-Aware Routing for Vision-Language Models
Oct 31, 2025Vision-Language Models (VLMs) excel in diverse multimodal tasks. However, user requirements vary across scenarios, which can be categorized into fast response, high-quality output, and low energy consumption. Relying solely on large models deployed in the cloud for all queries often leads to high latency and energy cost, while small models deployed on edge devices are capable of handling simpler tasks with low latency and energy cost. To fully leverage the strengths of both large and small models, we propose ECVL-ROUTER, the first scenario-aware routing framework for VLMs. Our approach introduces a new routing strategy and evaluation metrics that dynamically select the appropriate model for each query based on user requirements, maximizing overall utility. We also construct a multimodal response-quality dataset tailored for router training and validate the approach through extensive experiments. Results show that our approach successfully routes over 80\% of queries to the small model while incurring less than 10\% drop in problem solving probability.
Task Assignment and Exploration Optimization for Low Altitude UAV Rescue via Generative AI Enhanced Multi-agent Reinforcement Learning
Apr 18, 2025Artificial Intelligence (AI)-driven convolutional neural networks enhance rescue, inspection, and surveillance tasks performed by low-altitude uncrewed aerial vehicles (UAVs) and ground computing nodes (GCNs) in unknown environments. However, their high computational demands often exceed a single UAV's capacity, leading to system instability, further exacerbated by the limited and dynamic resources of GCNs. To address these challenges, this paper proposes a novel cooperation framework involving UAVs, ground-embedded robots (GERs), and high-altitude platforms (HAPs), which enable resource pooling through UAV-to-GER (U2G) and UAV-to-HAP (U2H) communications to provide computing services for UAV offloaded tasks. Specifically, we formulate the multi-objective optimization problem of task assignment and exploration optimization in UAVs as a dynamic long-term optimization problem. Our objective is to minimize task completion time and energy consumption while ensuring system stability over time. To achieve this, we first employ the Lyapunov optimization technique to transform the original problem, with stability constraints, into a per-slot deterministic problem. We then propose an algorithm named HG-MADDPG, which combines the Hungarian algorithm with a generative diffusion model (GDM)-based multi-agent deep deterministic policy gradient (MADDPG) approach. We first introduce the Hungarian algorithm as a method for exploration area selection, enhancing UAV efficiency in interacting with the environment. We then innovatively integrate the GDM and multi-agent deep deterministic policy gradient (MADDPG) to optimize task assignment decisions, such as task offloading and resource allocation. Simulation results demonstrate the effectiveness of the proposed approach, with significant improvements in task offloading efficiency, latency reduction, and system stability compared to baseline methods.
Satisfaction-Aware Incentive Scheme for Federated Learning in Industrial Metaverse: DRL-Based Stackbelberg Game Approach
Feb 10, 2025Industrial Metaverse leverages the Industrial Internet of Things (IIoT) to integrate data from diverse devices, employing federated learning and meta-computing to train models in a distributed manner while ensuring data privacy. Achieving an immersive experience for industrial Metaverse necessitates maintaining a balance between model quality and training latency. Consequently, a primary challenge in federated learning tasks is optimizing overall system performance by balancing model quality and training latency. This paper designs a satisfaction function that accounts for data size, Age of Information (AoI), and training latency. Additionally, the satisfaction function is incorporated into the utility functions to incentivize node participation in model training. We model the utility functions of servers and nodes as a two-stage Stackelberg game and employ a deep reinforcement learning approach to learn the Stackelberg equilibrium. This approach ensures balanced rewards and enhances the applicability of the incentive scheme for industrial Metaverse. Simulation results demonstrate that, under the same budget constraints, the proposed incentive scheme improves at least 23.7% utility compared to existing schemes without compromising model accuracy.
DNN Task Assignment in UAV Networks: A Generative AI Enhanced Multi-Agent Reinforcement Learning Approach
Nov 13, 2024



Unmanned Aerial Vehicles (UAVs) possess high mobility and flexible deployment capabilities, prompting the development of UAVs for various application scenarios within the Internet of Things (IoT). The unique capabilities of UAVs give rise to increasingly critical and complex tasks in uncertain and potentially harsh environments. The substantial amount of data generated from these applications necessitates processing and analysis through deep neural networks (DNNs). However, UAVs encounter challenges due to their limited computing resources when managing DNN models. This paper presents a joint approach that combines multiple-agent reinforcement learning (MARL) and generative diffusion models (GDM) for assigning DNN tasks to a UAV swarm, aimed at reducing latency from task capture to result output. To address these challenges, we first consider the task size of the target area to be inspected and the shortest flying path as optimization constraints, employing a greedy algorithm to resolve the subproblem with a focus on minimizing the UAV's flying path and the overall system cost. In the second stage, we introduce a novel DNN task assignment algorithm, termed GDM-MADDPG, which utilizes the reverse denoising process of GDM to replace the actor network in multi-agent deep deterministic policy gradient (MADDPG). This approach generates specific DNN task assignment actions based on agents' observations in a dynamic environment. Simulation results indicate that our algorithm performs favorably compared to benchmarks in terms of path planning, Age of Information (AoI), energy consumption, and task load balancing.
In-sensor Computing ANN Capacitive Sensors
May 27, 2024



This letter proposes an in-sensor computing multiply-and-accumulate (MAC) circuit based on capacitance. The MAC circuits can constitute an artificial neural network(ANN) layer and be operated as ANN classifiers and autoencoders. The proposed circuit is a promising scheme for capacitive ANN image sensors, showing competitively high efficiency and lower power.
Filter Pruning via Filters Similarity in Consecutive Layers
Apr 26, 2023Filter pruning is widely adopted to compress and accelerate the Convolutional Neural Networks (CNNs), but most previous works ignore the relationship between filters and channels in different layers. Processing each layer independently fails to utilize the collaborative relationship across layers. In this paper, we intuitively propose a novel pruning method by explicitly leveraging the Filters Similarity in Consecutive Layers (FSCL). FSCL compresses models by pruning filters whose corresponding features are more worthless in the model. The extensive experiments demonstrate the effectiveness of FSCL, and it yields remarkable improvement over state-of-the-art on accuracy, FLOPs and parameter reduction on several benchmark models and datasets.
Stability-based Generalization Analysis for Mixtures of Pointwise and Pairwise Learning
Feb 20, 2023
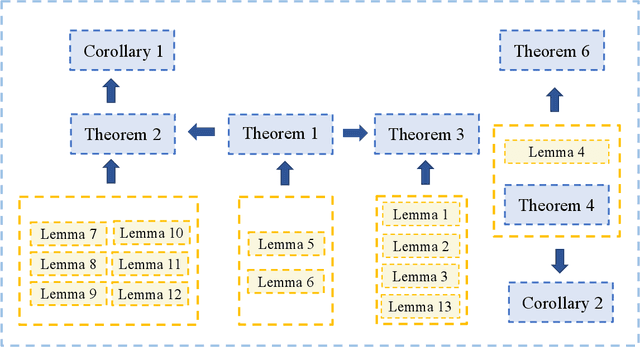
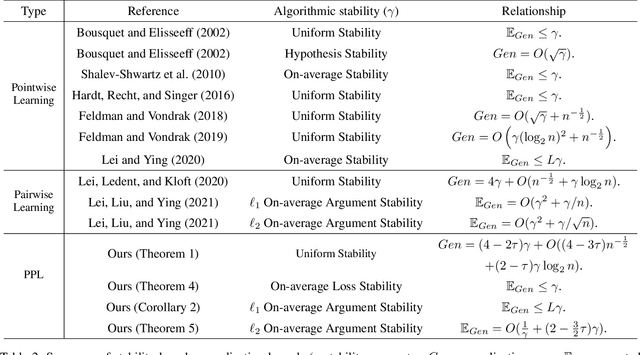
Recently, some mixture algorithms of pointwise and pairwise learning (PPL) have been formulated by employing the hybrid error metric of "pointwise loss + pairwise loss" and have shown empirical effectiveness on feature selection, ranking and recommendation tasks. However, to the best of our knowledge, the learning theory foundation of PPL has not been touched in the existing works. In this paper, we try to fill this theoretical gap by investigating the generalization properties of PPL. After extending the definitions of algorithmic stability to the PPL setting, we establish the high-probability generalization bounds for uniformly stable PPL algorithms. Moreover, explicit convergence rates of stochastic gradient descent (SGD) and regularized risk minimization (RRM) for PPL are stated by developing the stability analysis technique of pairwise learning. In addition, the refined generalization bounds of PPL are obtained by replacing uniform stability with on-average stability.
Auto-MLM: Improved Contrastive Learning for Self-supervised Multi-lingual Knowledge Retrieval
Mar 30, 2022

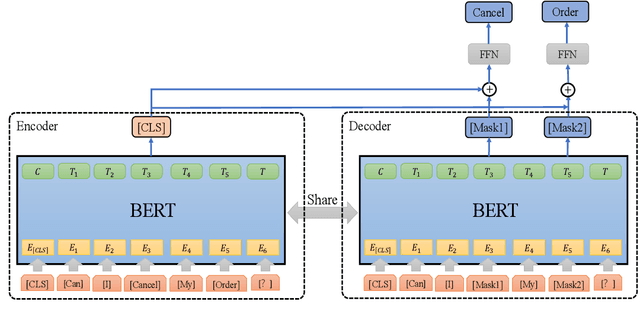
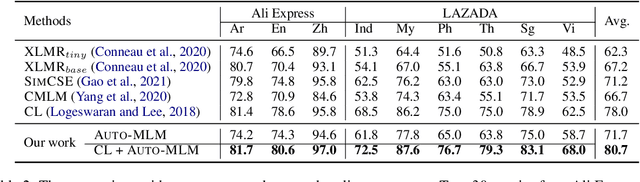
Contrastive learning (CL) has become a ubiquitous approach for several natural language processing (NLP) downstream tasks, especially for question answering (QA). However, the major challenge, how to efficiently train the knowledge retrieval model in an unsupervised manner, is still unresolved. Recently the commonly used methods are composed of CL and masked language model (MLM). Unexpectedly, MLM ignores the sentence-level training, and CL also neglects extraction of the internal info from the query. To optimize the CL hardly obtain internal information from the original query, we introduce a joint training method by combining CL and Auto-MLM for self-supervised multi-lingual knowledge retrieval. First, we acquire the fixed dimensional sentence vector. Then, mask some words among the original sentences with random strategy. Finally, we generate a new token representation for predicting the masked tokens. Experimental results show that our proposed approach consistently outperforms all the previous SOTA methods on both AliExpress $\&$ LAZADA service corpus and openly available corpora in 8 languages.