 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling High-Probability Generalization in Decentralized SGD
May 11, 2026Decentralized stochastic gradient descent (D-SGD) is an efficient method for large-scale distributed learning. Existing generalization studies mainly address expected results, achieving rates limited to $\mathcal{O}\left(\frac{1}{δ\sqrt{mn}}\right)$, where $δ$ is the confidence parameter, $m$ the number of workers, and $n$ the sample size. When $m=1$, D-SGD reduces to traditional SGD, whose optimal high-probability generalization bound is $\mathcal{O}\left(\frac{1}{\sqrt{n}}\log (1/δ)\right)$. This discrepancy reveals a gap between high-probability guarantees for SGD and those for D-SGD. To close this, we develop a high-probability learning theory for D-SGD, aiming for the optimal $\mathcal{O}\left(\frac{1}{\sqrt{mn}}\log (1/δ)\right)$ rate. We refine bounds for D-SGD using pointwise uniform stability in distributed learning-a weaker notion than uniform stability-and analyze them across convex, strongly convex, and non-convex settings. We also provide high-probability results for gradient-based measures in non-convex cases where only local minima exist, and derive optimization error and excess risk bounds. Finally, accounting for communication overhead, we analyze generalization bounds for local models within time-varying frameworks.
Revealing Modular Gradient Noise Imbalance in LLMs: Calibrating Adam via Signal-to-Noise Ratio
May 07, 2026The impressive performance of large language models (LLMs) arises from their massive scale and heterogeneous module composition. However, this structural heterogeneity introduces additional optimization challenges. While adaptive optimizers such as Adam(W) provide per-parameter adaptivity, they do not explicitly account for module-level gradient heterogeneity, resulting in slower convergence, suboptimal performance, or training instability. Existing approaches typically rely on manually tuned module-specific learning rates or specific optimization strategies, which are computationally costly and difficult to generalize across tasks or models. To establish a more principled approach, we first analyze the noise-damping behavior of Adam in high-noise modules and introduce \textbf{Module-wise Learning Rate Scaling via SNR (MoLS)}. MoLS estimates module-level SNRs to scale Adam updates, allowing automated module-wise learning rate allocation without manual tuning. Empirical results through multiple LLM training benchmarks demonstrate that MoLS improves convergence speed and generalization, achieving performance comparable to carefully tuned module-specific learning rates, while remaining compatible with memory-efficient training algorithms.
Stability and Generalization for Decentralized Markov SGD
May 03, 2026Stochastic gradient methods are central to large-scale learning, yet their generalization theory typically relies on independent sampling assumptions. In many practical applications, data are generated by Markov chains and learning is performed in a decentralized manner, which introduces significant analytical challenges. In this work, we investigate the stability and generalization of decentralized stochastic gradient descent (SGD) and stochastic gradient descent ascent (SGDA) under Markov chain sampling. Leveraging a stability-based framework, we characterize how Markovian dependence and decentralized communication jointly influence generalization behavior. Our analysis captures the effects of network topology, Markov chain mixing properties, and primal-dual dynamics. We establish non-asymptotic generalization bounds for both algorithms, extending existing results on Markov stochastic gradient methods to decentralized and minimax settings.
Generative Refinement Networks for Visual Synthesis
Apr 14, 2026While diffusion models dominate the field of visual generation, they are computationally inefficient, applying a uniform computational effort regardless of different complexity. In contrast, autoregressive (AR) models are inherently complexity-aware, as evidenced by their variable likelihoods, but are often hindered by lossy discrete tokenization and error accumulation. In this work, we introduce Generative Refinement Networks (GRN), a next-generation visual synthesis paradigm to address these issues. At its core, GRN addresses the discrete tokenization bottleneck through a theoretically near-lossless Hierarchical Binary Quantization (HBQ), achieving a reconstruction quality comparable to continuous counterparts. Built upon HBQ's latent space, GRN fundamentally upgrades AR generation with a global refinement mechanism that progressively perfects and corrects artworks -- like a human artist painting. Besides, GRN integrates an entropy-guided sampling strategy, enabling complexity-aware, adaptive-step generation without compromising visual quality. On the ImageNet benchmark, GRN establishes new records in image reconstruction (0.56 rFID) and class-conditional image generation (1.81 gFID). We also scale GRN to more challenging text-to-image and text-to-video generation, delivering superior performance on an equivalent scale. We release all models and code to foster further research on GRN.
Local Gradient Regulation Stabilizes Federated Learning under Client Heterogeneity
Jan 07, 2026Federated learning (FL) enables collaborative model training across distributed clients without sharing raw data, yet its stability is fundamentally challenged by statistical heterogeneity in realistic deployments. Here, we show that client heterogeneity destabilizes FL primarily by distorting local gradient dynamics during client-side optimization, causing systematic drift that accumulates across communication rounds and impedes global convergence. This observation highlights local gradients as a key regulatory lever for stabilizing heterogeneous FL systems. Building on this insight, we develop a general client-side perspective that regulates local gradient contributions without incurring additional communication overhead. Inspired by swarm intelligence, we instantiate this perspective through Exploratory--Convergent Gradient Re-aggregation (ECGR), which balances well-aligned and misaligned gradient components to preserve informative updates while suppressing destabilizing effects. Theoretical analysis and extensive experiments, including evaluations on the LC25000 medical imaging dataset, demonstrate that regulating local gradient dynamics consistently stabilizes federated learning across state-of-the-art methods under heterogeneous data distributions.
Low-PAPR OFDM-ISAC Waveform Design Based on Frequency-Domain Phase Differences
Mar 17, 2025

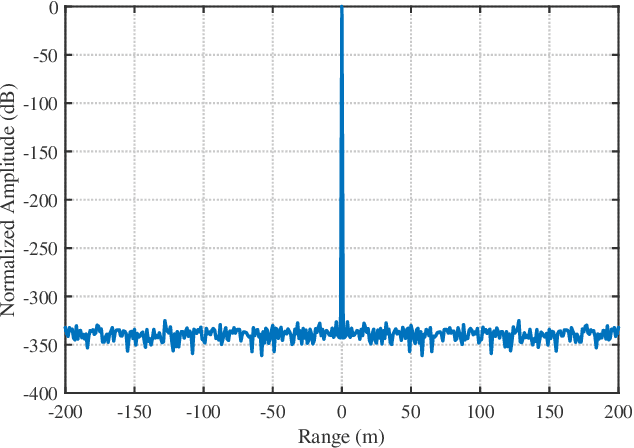

Low peak-to-average power ratio (PAPR) orthogonal frequency division multiplexing (OFDM) waveform design is a crucial issue in integrated sensing and communications (ISAC). This paper introduces an OFDM-ISAC waveform design that utilizes the entire spectrum simultaneously for both communication and sensing by leveraging a novel degree of freedom (DoF): the frequency-domain phase difference (PD). Based on this concept, we develop a novel PD-based OFDM-ISAC waveform structure and utilize it to design a PD-based Low-PAPR OFDM-ISAC (PLPOI) waveform. The design is formulated as an optimization problem incorporating four key constraints: the time-frequency relationship equation, frequency-domain unimodular constraints, PD constraints, and time-domain low PAPR requirements. To solve this challenging non-convex problem, we develop an efficient algorithm, ADMM-PLPOI, based on the alternating direction method of multipliers (ADMM) framework. Extensive simulation results demonstrate that the proposed PLPOI waveform achieves significant improvements in both PAPR and bit error rate (BER) performance compared to conventional OFDM-ISAC waveforms.
Breaking Memory Limits: Gradient Wavelet Transform Enhances LLMs Training
Jan 13, 2025



Large language models (LLMs) have shown impressive performance across a range of natural language processing tasks. However, their vast number of parameters introduces significant memory challenges during training, particularly when using memory-intensive optimizers like Adam. Existing memory-efficient algorithms often rely on techniques such as singular value decomposition projection or weight freezing. While these approaches help alleviate memory constraints, they generally produce suboptimal results compared to full-rank updates. In this paper, we investigate the memory-efficient method beyond low-rank training, proposing a novel solution called Gradient Wavelet Transform (GWT), which applies wavelet transforms to gradients in order to significantly reduce the memory requirements for maintaining optimizer states. We demonstrate that GWT can be seamlessly integrated with memory-intensive optimizers, enabling efficient training without sacrificing performance. Through extensive experiments on both pre-training and fine-tuning tasks, we show that GWT achieves state-of-the-art performance compared with advanced memory-efficient optimizers and full-rank approaches in terms of both memory usage and training performance.
Stability-based Generalization Analysis for Mixtures of Pointwise and Pairwise Learning
Feb 20, 2023
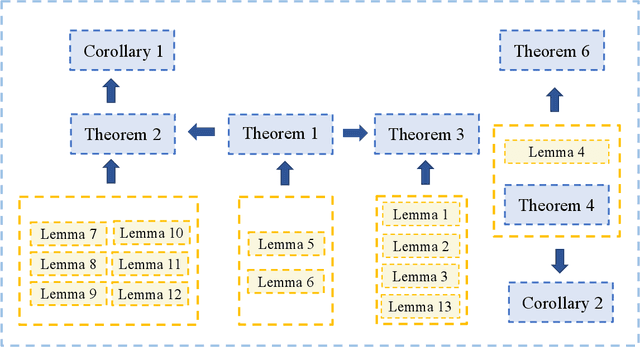
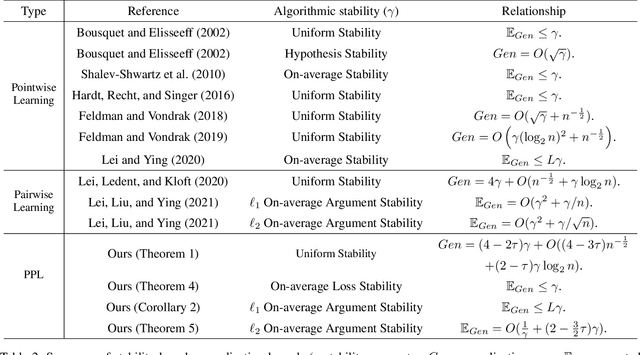
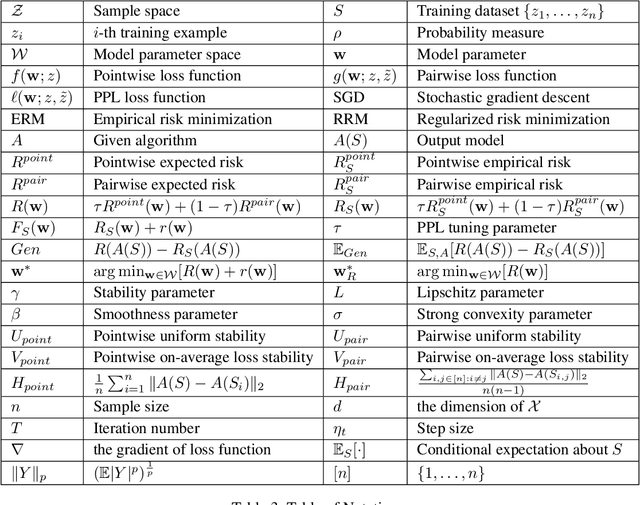
Recently, some mixture algorithms of pointwise and pairwise learning (PPL) have been formulated by employing the hybrid error metric of "pointwise loss + pairwise loss" and have shown empirical effectiveness on feature selection, ranking and recommendation tasks. However, to the best of our knowledge, the learning theory foundation of PPL has not been touched in the existing works. In this paper, we try to fill this theoretical gap by investigating the generalization properties of PPL. After extending the definitions of algorithmic stability to the PPL setting, we establish the high-probability generalization bounds for uniformly stable PPL algorithms. Moreover, explicit convergence rates of stochastic gradient descent (SGD) and regularized risk minimization (RRM) for PPL are stated by developing the stability analysis technique of pairwise learning. In addition, the refined generalization bounds of PPL are obtained by replacing uniform stability with on-average stability.