 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Good are LLMs at Relation Extraction under Low-Resource Scenario? Comprehensive Evaluation
Jun 17, 2024



Relation Extraction (RE) serves as a crucial technology for transforming unstructured text into structured information, especially within the framework of Knowledge Graph development. Its importance is emphasized by its essential role in various downstream tasks. Besides the conventional RE methods which are based on neural networks and pre-trained language models, large language models (LLMs) are also utilized in the research field of RE. However, on low-resource languages (LRLs), both conventional RE methods and LLM-based methods perform poorly on RE due to the data scarcity issues. To this end, this paper constructs low-resource relation extraction datasets in 10 LRLs in three regions (Central Asia, Southeast Asia and Middle East). The corpora are constructed by translating the original publicly available English RE datasets (NYT10, FewRel and CrossRE) using an effective multilingual machine translation. Then, we use the language perplexity (PPL) to filter out the low-quality data from the translated datasets. Finally, we conduct an empirical study and validate the performance of several open-source LLMs on these generated LRL RE datasets.
Improving Cross-lingual Representation for Semantic Retrieval with Code-switching
Mar 03, 2024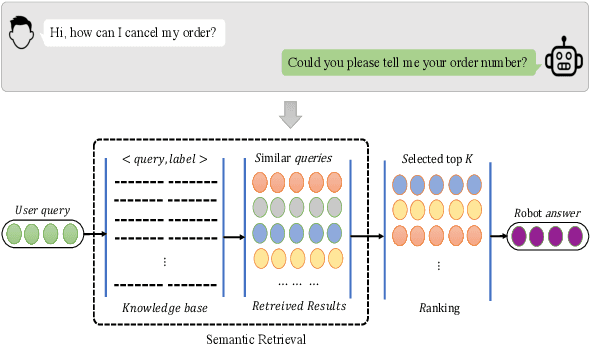



Semantic Retrieval (SR) has become an indispensable part of the FAQ system in the task-oriented question-answering (QA) dialogue scenario. The demands for a cross-lingual smart-customer-service system for an e-commerce platform or some particular business conditions have been increasing recently. Most previous studies exploit cross-lingual pre-trained models (PTMs) for multi-lingual knowledge retrieval directly, while some others also leverage the continual pre-training before fine-tuning PTMs on the downstream tasks. However, no matter which schema is used, the previous work ignores to inform PTMs of some features of the downstream task, i.e. train their PTMs without providing any signals related to SR. To this end, in this work, we propose an Alternative Cross-lingual PTM for SR via code-switching. We are the first to utilize the code-switching approach for cross-lingual SR. Besides, we introduce the novel code-switched continual pre-training instead of directly using the PTMs on the SR tasks. The experimental results show that our proposed approach consistently outperforms the previous SOTA methods on SR and semantic textual similarity (STS) tasks with three business corpora and four open datasets in 20+ languages.
Rethinking Human-like Translation Strategy: Integrating Drift-Diffusion Model with Large Language Models for Machine Translation
Feb 16, 2024
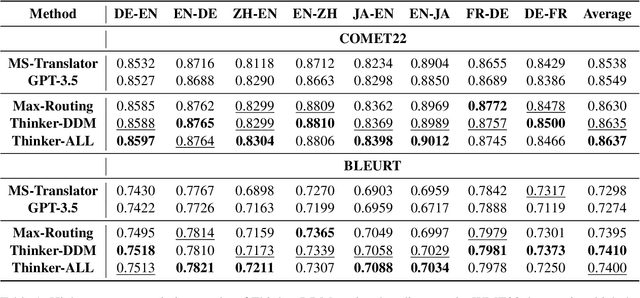
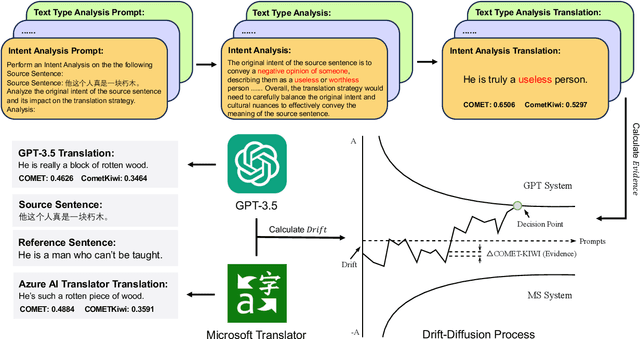
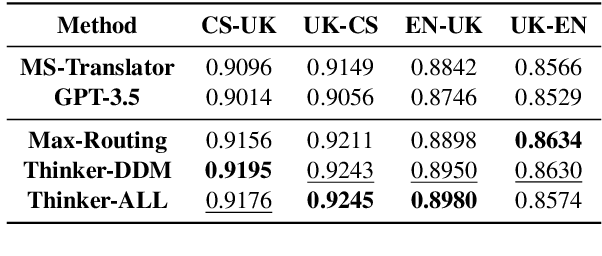
Large language models (LLMs) have demonstrated promising potential in various downstream tasks, including machine translation. However, prior work on LLM-based machine translation has mainly focused on better utilizing training data, demonstrations, or pre-defined and universal knowledge to improve performance, with a lack of consideration of decision-making like human translators. In this paper, we incorporate Thinker with the Drift-Diffusion Model (Thinker-DDM) to address this issue. We then redefine the Drift-Diffusion process to emulate human translators' dynamic decision-making under constrained resources. We conduct extensive experiments under the high-resource, low-resource, and commonsense translation settings using the WMT22 and CommonMT datasets, in which Thinker-DDM outperforms baselines in the first two scenarios. We also perform additional analysis and evaluation on commonsense translation to illustrate the high effectiveness and efficacy of the proposed method.
Generating Persuasive Responses to Customer Reviews with Multi-Source Prior Knowledge in E-commerce
Sep 20, 2022
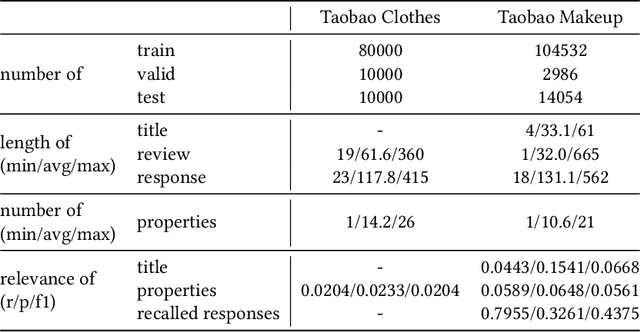


Customer reviews usually contain much information about one's online shopping experience. While positive reviews are beneficial to the stores, negative ones will largely influence consumers' decision and may lead to a decline in sales. Therefore, it is of vital importance to carefully and persuasively reply to each negative review and minimize its disadvantageous effect. Recent studies consider leveraging generation models to help the sellers respond. However, this problem is not well-addressed as the reviews may contain multiple aspects of issues which should be resolved accordingly and persuasively. In this work, we propose a Multi-Source Multi-Aspect Attentive Generation model for persuasive response generation. Various sources of information are appropriately obtained and leveraged by the proposed model for generating more informative and persuasive responses. A multi-aspect attentive network is proposed to automatically attend to different aspects in a review and ensure most of the issues are tackled. Extensive experiments on two real-world datasets, demonstrate that our approach outperforms the state-of-the-art methods and online tests prove that our deployed system significantly enhances the efficiency of the stores' dealing with negative reviews.
MGIMN: Multi-Grained Interactive Matching Network for Few-shot Text Classification
Apr 18, 2022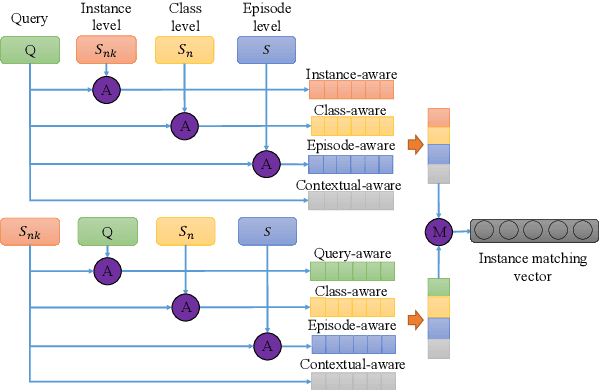
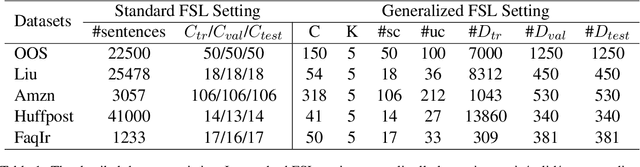
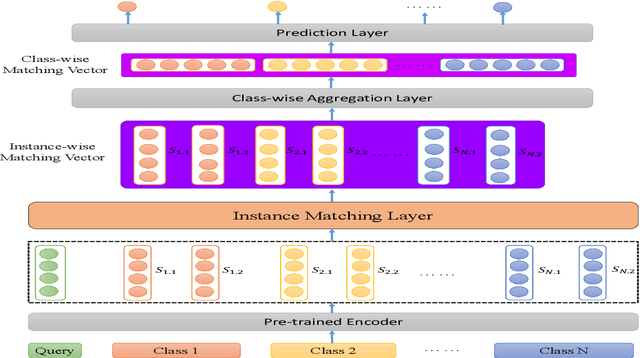
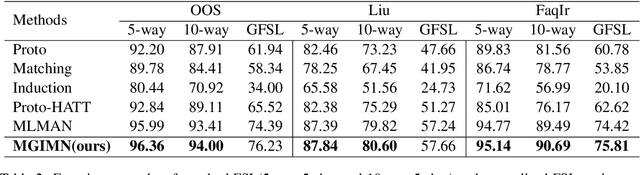
Text classification struggles to generalize to unseen classes with very few labeled text instances per class. In such a few-shot learning (FSL) setting, metric-based meta-learning approaches have shown promising results. Previous studies mainly aim to derive a prototype representation for each class. However, they neglect that it is challenging-yet-unnecessary to construct a compact representation which expresses the entire meaning for each class. They also ignore the importance to capture the inter-dependency between query and the support set for few-shot text classification. To deal with these issues, we propose a meta-learning based method MGIMN which performs instance-wise comparison followed by aggregation to generate class-wise matching vectors instead of prototype learning. The key of instance-wise comparison is the interactive matching within the class-specific context and episode-specific context. Extensive experiments demonstrate that the proposed method significantly outperforms the existing state-of-the-art approaches, under both the standard FSL and generalized FSL settings.
Auto-MLM: Improved Contrastive Learning for Self-supervised Multi-lingual Knowledge Retrieval
Mar 30, 2022

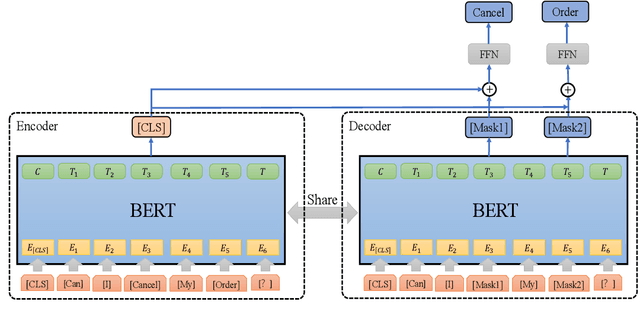
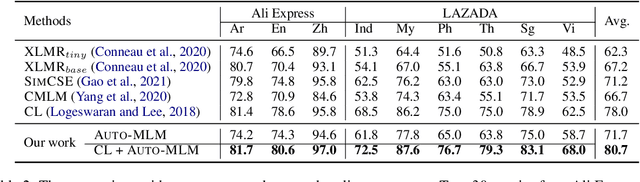
Contrastive learning (CL) has become a ubiquitous approach for several natural language processing (NLP) downstream tasks, especially for question answering (QA). However, the major challenge, how to efficiently train the knowledge retrieval model in an unsupervised manner, is still unresolved. Recently the commonly used methods are composed of CL and masked language model (MLM). Unexpectedly, MLM ignores the sentence-level training, and CL also neglects extraction of the internal info from the query. To optimize the CL hardly obtain internal information from the original query, we introduce a joint training method by combining CL and Auto-MLM for self-supervised multi-lingual knowledge retrieval. First, we acquire the fixed dimensional sentence vector. Then, mask some words among the original sentences with random strategy. Finally, we generate a new token representation for predicting the masked tokens. Experimental results show that our proposed approach consistently outperforms all the previous SOTA methods on both AliExpress $\&$ LAZADA service corpus and openly available corpora in 8 languages.