 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing HNSW Index for Real-Time Updates: Addressing Unreachable Points and Performance Degradation
Jul 10, 2024



The approximate nearest neighbor search (ANNS) is a fundamental and essential component in information retrieval, with graph-based methodologies demonstrating superior performance compared to alternative approaches. Extensive research efforts have been dedicated to improving search efficiency by developing various graph-based indices, such as HNSW (Hierarchical Navigable Small World). However, the performance of HNSW and most graph-based indices becomes unacceptable when faced with a large number of real-time deletions, insertions, and updates. Furthermore, during update operations, HNSW can result in some data points becoming unreachable, a situation we refer to as the `unreachable points phenomenon'. This phenomenon could significantly affect the search accuracy of the graph in certain situations. To address these issues, we present efficient measures to overcome the shortcomings of HNSW, specifically addressing poor performance over long periods of delete and update operations and resolving the issues caused by the unreachable points phenomenon. Our proposed MN-RU algorithm effectively improves update efficiency and suppresses the growth rate of unreachable points, ensuring better overall performance and maintaining the integrity of the graph. Our results demonstrate that our methods outperform existing approaches. Furthermore, since our methods are based on HNSW, they can be easily integrated with existing indices widely used in the industrial field, making them practical for future real-world applications. Code is available at https://github.com/xwt1/ICPADS-MN-RU.git
How Good are LLMs at Relation Extraction under Low-Resource Scenario? Comprehensive Evaluation
Jun 17, 2024



Relation Extraction (RE) serves as a crucial technology for transforming unstructured text into structured information, especially within the framework of Knowledge Graph development. Its importance is emphasized by its essential role in various downstream tasks. Besides the conventional RE methods which are based on neural networks and pre-trained language models, large language models (LLMs) are also utilized in the research field of RE. However, on low-resource languages (LRLs), both conventional RE methods and LLM-based methods perform poorly on RE due to the data scarcity issues. To this end, this paper constructs low-resource relation extraction datasets in 10 LRLs in three regions (Central Asia, Southeast Asia and Middle East). The corpora are constructed by translating the original publicly available English RE datasets (NYT10, FewRel and CrossRE) using an effective multilingual machine translation. Then, we use the language perplexity (PPL) to filter out the low-quality data from the translated datasets. Finally, we conduct an empirical study and validate the performance of several open-source LLMs on these generated LRL RE datasets.
Sequential Decision Fusion for Environmental Classification in Assistive Walking
Apr 25, 2019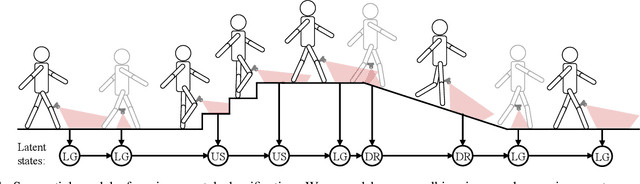
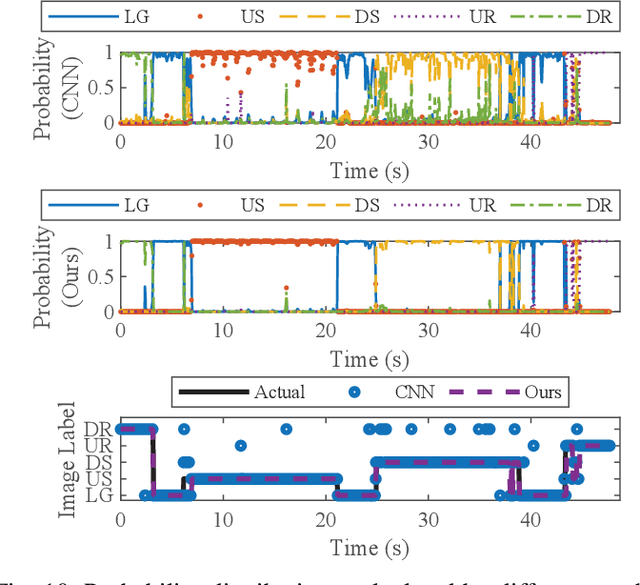
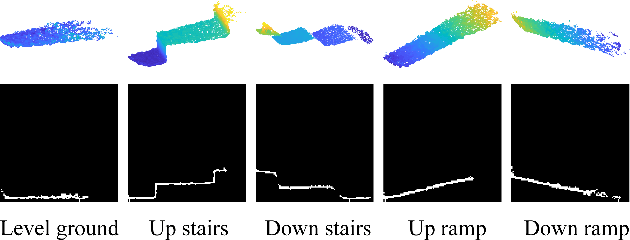
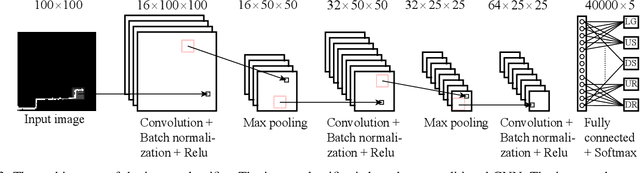
Powered prostheses are effective for helping amputees walk on level ground, but these devices are inconvenient to use in complex environments. Prostheses need to understand the motion intent of amputees to help them walk in complex environments. Recently, researchers have found that they can use vision sensors to classify environments and predict the motion intent of amputees. Previous researchers can classify environments accurately in the offline analysis, but they neglect to decrease the corresponding time delay. To increase the accuracy and decrease the time delay of environmental classification, we propose a new decision fusion method in this paper. We fuse sequential decisions of environmental classification by constructing a hidden Markov model and designing a transition probability matrix. We evaluate our method by inviting able-bodied subjects and amputees to implement indoor and outdoor experiments. Experimental results indicate that our method can classify environments more accurately and with less time delay than previous methods. Besides classifying environments, the proposed decision fusion method may also optimize sequential predictions of the human motion intent in the future.