 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-MLM: Improved Contrastive Learning for Self-supervised Multi-lingual Knowledge Retrieval
Paper and Code
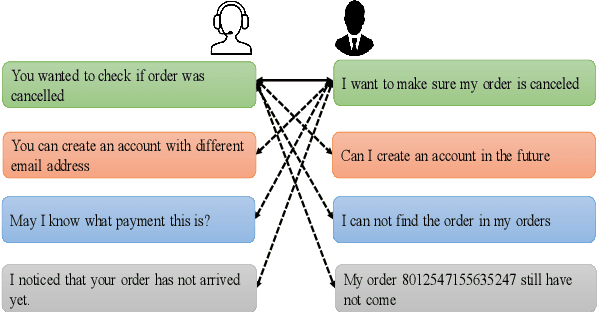

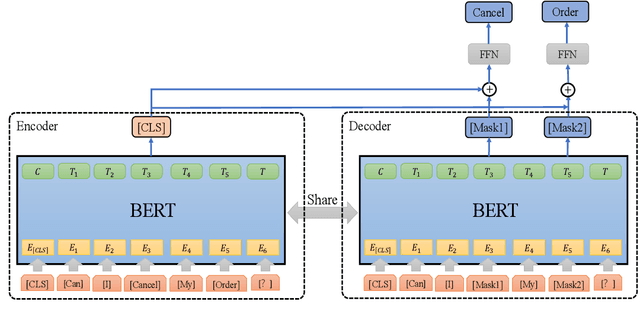
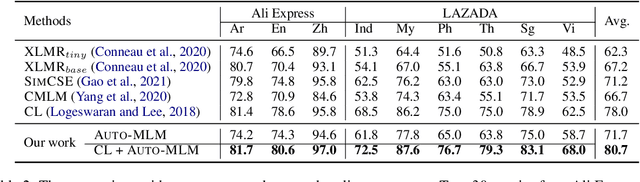
Contrastive learning (CL) has become a ubiquitous approach for several natural language processing (NLP) downstream tasks, especially for question answering (QA). However, the major challenge, how to efficiently train the knowledge retrieval model in an unsupervised manner, is still unresolved. Recently the commonly used methods are composed of CL and masked language model (MLM). Unexpectedly, MLM ignores the sentence-level training, and CL also neglects extraction of the internal info from the query. To optimize the CL hardly obtain internal information from the original query, we introduce a joint training method by combining CL and Auto-MLM for self-supervised multi-lingual knowledge retrieval. First, we acquire the fixed dimensional sentence vector. Then, mask some words among the original sentences with random strategy. Finally, we generate a new token representation for predicting the masked tokens. Experimental results show that our proposed approach consistently outperforms all the previous SOTA methods on both AliExpress $\&$ LAZADA service corpus and openly available corpora in 8 languages.