 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHerculean: An Agentic Benchmark for Financial Intelligence
May 14, 2026As AI agents improve, the central question is no longer whether they can solve isolated well-defined financial tasks, but whether they can reliably carry out financial professional work. Existing financial benchmarks offer only a partial view of this ability, as they primarily evaluate static competencies such as question answering, retrieval, summarization, and classification. We introduce Herculean, the first skilled benchmark for agentic financial intelligence spanning four representative workflows, including Trading, Hedging, Market Insights, and Auditing. Each workflow is instantiated as a standardized MCP-based skill environment with its own tools, interaction dynamics, constraints, and success criteria, enabling consistent end-to-end assessment of heterogeneous agent systems. Across frontier agents, we find agents perform relatively well on Trading and Market Insights, but struggle substantially on Hedging and Auditing, where long-horizon coordination, state consistency, and structured verification are critical. Overall, our results point to a key gap in current agents in turning financial reasoning into dependable workflow execution in high-stakes financial workflows.
Do No Harm: Exposing Hidden Vulnerabilities of LLMs via Persona-based Client Simulation Attack in Psychological Counseling
Apr 06, 2026The increasing use of large language models (LLMs) in mental healthcare raises safety concerns in high-stakes therapeutic interactions. A key challenge is distinguishing therapeutic empathy from maladaptive validation, where supportive responses may inadvertently reinforce harmful beliefs or behaviors in multi-turn conversations. This risk is largely overlooked by existing red-teaming frameworks, which focus mainly on generic harms or optimization-based attacks. To address this gap, we introduce Personality-based Client Simulation Attack (PCSA), the first red-teaming framework that simulates clients in psychological counseling through coherent, persona-driven client dialogues to expose vulnerabilities in psychological safety alignment. Experiments on seven general and mental health-specialized LLMs show that PCSA substantially outperforms four competitive baselines. Perplexity analysis and human inspection further indicate that PCSA generates more natural and realistic dialogues. Our results reveal that current LLMs remain vulnerable to domain-specific adversarial tactics, providing unauthorized medical advice, reinforcing delusions, and implicitly encouraging risky actions.
EffiSkill: Agent Skill Based Automated Code Efficiency Optimization
Mar 29, 2026Code efficiency is a fundamental aspect of software quality, yet how to harness large language models (LLMs) to optimize programs remains challenging. Prior approaches have sought for one-shot rewriting, retrieved exemplars, or prompt-based search, but they do not explicitly distill reusable optimization knowledge, which limits generalization beyond individual instances. In this paper, we present EffiSkill, a framework for code-efficiency optimization that builds a portable optimization toolbox for LLM-based agents. The key idea is to model recurring slow-to-fast transformations as reusable agent skills that capture both concrete transformation mechanisms and higher-level optimization strategies. EffiSkill adopts a two-stage design: Stage I mines Operator and Meta Skills from large-scale slow/fast program pairs to build a skill library; Stage II applies this library to unseen programs through execution-free diagnosis, skill retrieval, plan composition, and candidate generation, without runtime feedback. Results on EffiBench-X show that EffiSkill achieves higher optimization success rates, improving over the strongest baseline by 3.69 to 12.52 percentage points across model and language settings. These findings suggest that mechanism-level skill reuse provides a useful foundation for execution-free code optimization, and that the resulting skill library can serve as a reusable resource for broader agent workflows.
CHiRPE: A Step Towards Real-World Clinical NLP with Clinician-Oriented Model Explanations
Jan 26, 2026The medical adoption of NLP tools requires interpretability by end users, yet traditional explainable AI (XAI) methods are misaligned with clinical reasoning and lack clinician input. We introduce CHiRPE (Clinical High-Risk Prediction with Explainability), an NLP pipeline that takes transcribed semi-structured clinical interviews to: (i) predict psychosis risk; and (ii) generate novel SHAP explanation formats co-developed with clinicians. Trained on 944 semi-structured interview transcripts across 24 international clinics of the AMP-SCZ study, the CHiRPE pipeline integrates symptom-domain mapping, LLM summarisation, and BERT classification. CHiRPE achieved over 90% accuracy across three BERT variants and outperformed baseline models. Explanation formats were evaluated by 28 clinical experts who indicated a strong preference for our novel concept-guided explanations, especially hybrid graph-and-text summary formats. CHiRPE demonstrates that clinically-guided model development produces both accurate and interpretable results. Our next step is focused on real-world testing across our 24 international sites.
PsychEthicsBench: Evaluating Large Language Models Against Australian Mental Health Ethics
Jan 07, 2026The increasing integration of large language models (LLMs) into mental health applications necessitates robust frameworks for evaluating professional safety alignment. Current evaluative approaches primarily rely on refusal-based safety signals, which offer limited insight into the nuanced behaviors required in clinical practice. In mental health, clinically inadequate refusals can be perceived as unempathetic and discourage help-seeking. To address this gap, we move beyond refusal-centric metrics and introduce \texttt{PsychEthicsBench}, the first principle-grounded benchmark based on Australian psychology and psychiatry guidelines, designed to evaluate LLMs' ethical knowledge and behavioral responses through multiple-choice and open-ended tasks with fine-grained ethicality annotations. Empirical results across 14 models reveal that refusal rates are poor indicators of ethical behavior, revealing a significant divergence between safety triggers and clinical appropriateness. Notably, we find that domain-specific fine-tuning can degrade ethical robustness, as several specialized models underperform their base backbones in ethical alignment. PsychEthicsBench provides a foundation for systematic, jurisdiction-aware evaluation of LLMs in mental health, encouraging more responsible development in this domain.
You Never Know a Person, You Only Know Their Defenses: Detecting Levels of Psychological Defense Mechanisms in Supportive Conversations
Dec 17, 2025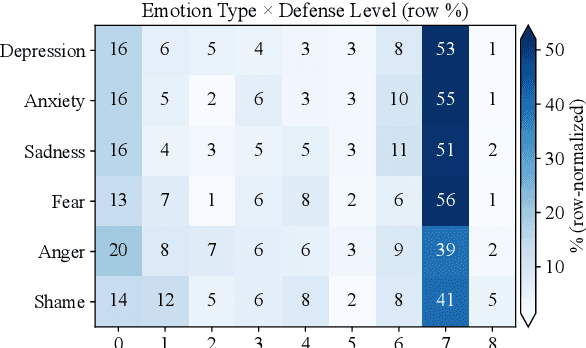
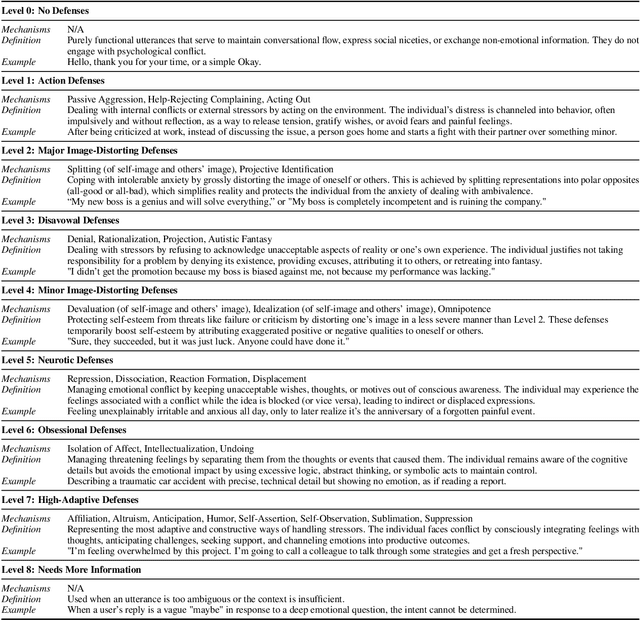
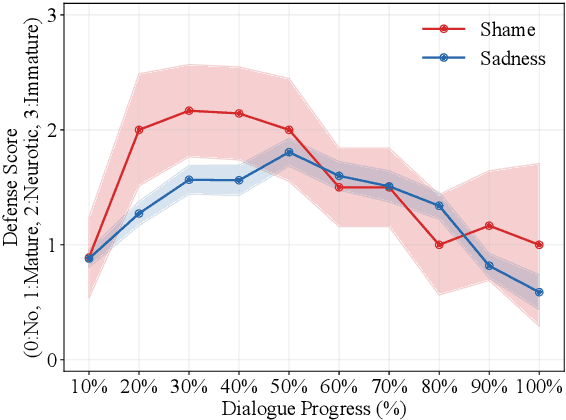
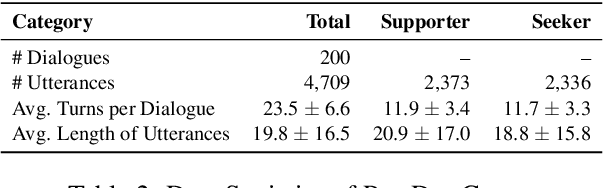
Psychological defenses are strategies, often automatic, that people use to manage distress. Rigid or overuse of defenses is negatively linked to mental health and shapes what speakers disclose and how they accept or resist help. However, defenses are complex and difficult to reliably measure, particularly in clinical dialogues. We introduce PsyDefConv, a dialogue corpus with help seeker utterances labeled for defense level, and DMRS Co-Pilot, a four-stage pipeline that provides evidence-based pre-annotations. The corpus contains 200 dialogues and 4709 utterances, including 2336 help seeker turns, with labeling and Cohen's kappa 0.639. In a counterbalanced study, the co-pilot reduced average annotation time by 22.4%. In expert review, it averaged 4.62 for evidence, 4.44 for clinical plausibility, and 4.40 for insight on a seven-point scale. Benchmarks with strong language models in zero-shot and fine-tuning settings demonstrate clear headroom, with the best macro F1-score around 30% and a tendency to overpredict mature defenses. Corpus analyses confirm that mature defenses are most common and reveal emotion-specific deviations. We will release the corpus, annotations, code, and prompts to support research on defensive functioning in language.
Benchmarking and Improving LVLMs on Event Extraction from Multimedia Documents
Sep 16, 2025The proliferation of multimedia content necessitates the development of effective Multimedia Event Extraction (M2E2) systems. Though Large Vision-Language Models (LVLMs) have shown strong cross-modal capabilities, their utility in the M2E2 task remains underexplored. In this paper, we present the first systematic evaluation of representative LVLMs, including DeepSeek-VL2 and the Qwen-VL series, on the M2E2 dataset. Our evaluations cover text-only, image-only, and cross-media subtasks, assessed under both few-shot prompting and fine-tuning settings. Our key findings highlight the following valuable insights: (1) Few-shot LVLMs perform notably better on visual tasks but struggle significantly with textual tasks; (2) Fine-tuning LVLMs with LoRA substantially enhances model performance; and (3) LVLMs exhibit strong synergy when combining modalities, achieving superior performance in cross-modal settings. We further provide a detailed error analysis to reveal persistent challenges in areas such as semantic precision, localization, and cross-modal grounding, which remain critical obstacles for advancing M2E2 capabilities.
LimiX: Unleashing Structured-Data Modeling Capability for Generalist Intelligence
Sep 03, 2025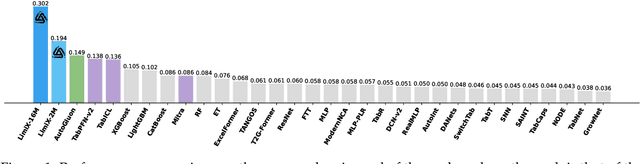
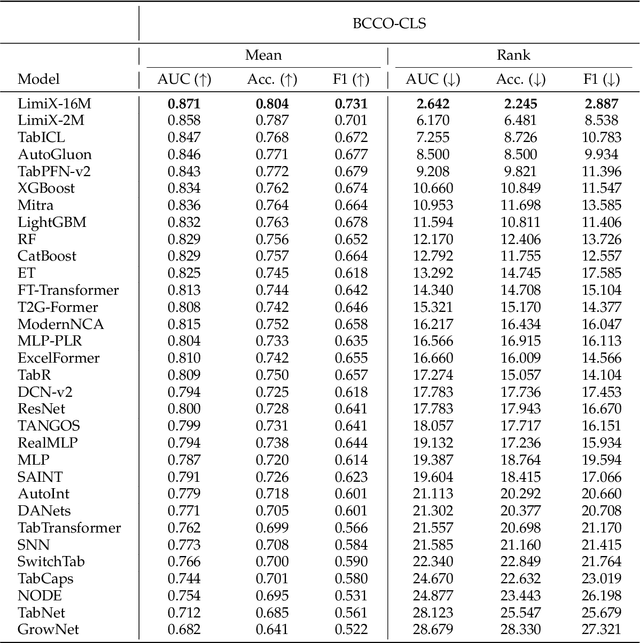
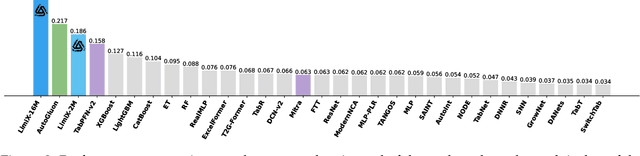
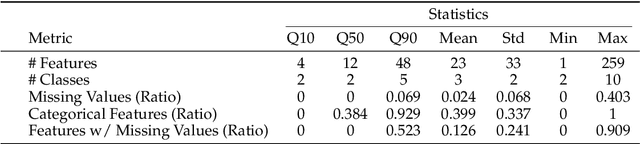
We argue that progress toward general intelligence requires complementary foundation models grounded in language, the physical world, and structured data. This report presents LimiX, the first installment of our large structured-data models (LDMs). LimiX treats structured data as a joint distribution over variables and missingness, thus capable of addressing a wide range of tabular tasks through query-based conditional prediction via a single model. LimiX is pretrained using masked joint-distribution modeling with an episodic, context-conditional objective, where the model predicts for query subsets conditioned on dataset-specific contexts, supporting rapid, training-free adaptation at inference. We evaluate LimiX across 10 large structured-data benchmarks with broad regimes of sample size, feature dimensionality, class number, categorical-to-numerical feature ratio, missingness, and sample-to-feature ratios. With a single model and a unified interface, LimiX consistently surpasses strong baselines including gradient-boosting trees, deep tabular networks, recent tabular foundation models, and automated ensembles, as shown in Figure 1 and Figure 2. The superiority holds across a wide range of tasks, such as classification, regression, missing value imputation, and data generation, often by substantial margins, while avoiding task-specific architectures or bespoke training per task. All LimiX models are publicly accessible under Apache 2.0.
Lost in Pronunciation: Detecting Chinese Offensive Language Disguised by Phonetic Cloaking Replacement
Jul 10, 2025Phonetic Cloaking Replacement (PCR), defined as the deliberate use of homophonic or near-homophonic variants to hide toxic intent, has become a major obstacle to Chinese content moderation. While this problem is well-recognized, existing evaluations predominantly rely on rule-based, synthetic perturbations that ignore the creativity of real users. We organize PCR into a four-way surface-form taxonomy and compile \ours, a dataset of 500 naturally occurring, phonetically cloaked offensive posts gathered from the RedNote platform. Benchmarking state-of-the-art LLMs on this dataset exposes a serious weakness: the best model reaches only an F1-score of 0.672, and zero-shot chain-of-thought prompting pushes performance even lower. Guided by error analysis, we revisit a Pinyin-based prompting strategy that earlier studies judged ineffective and show that it recovers much of the lost accuracy. This study offers the first comprehensive taxonomy of Chinese PCR, a realistic benchmark that reveals current detectors' limits, and a lightweight mitigation technique that advances research on robust toxicity detection.
Language-based Audio Retrieval with Co-Attention Networks
Dec 30, 2024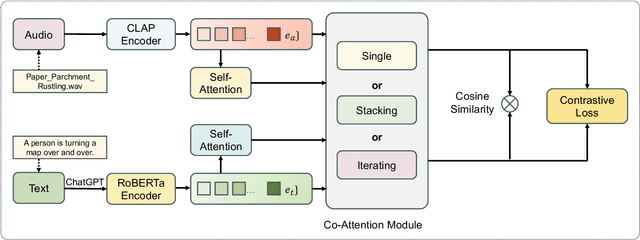
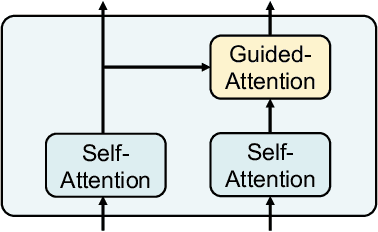
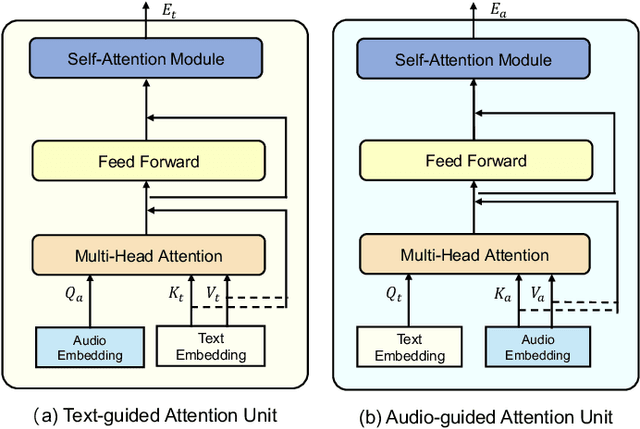
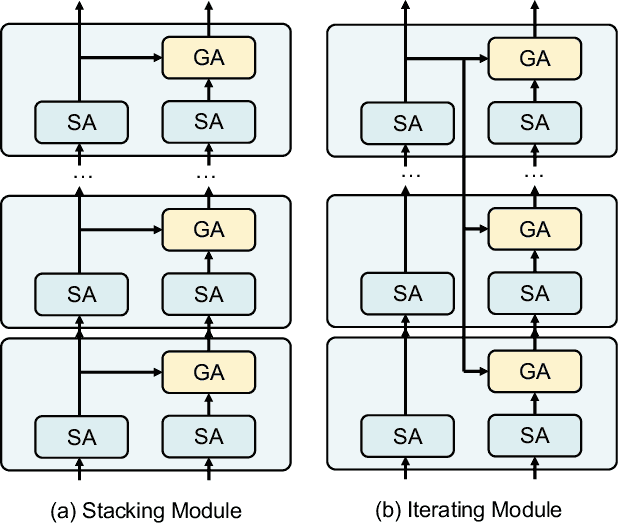
In recent years, user-generated audio content has proliferated across various media platforms, creating a growing need for efficient retrieval methods that allow users to search for audio clips using natural language queries. This task, known as language-based audio retrieval, presents significant challenges due to the complexity of learning semantic representations from heterogeneous data across both text and audio modalities. In this work, we introduce a novel framework for the language-based audio retrieval task that leverages co-attention mechanismto jointly learn meaningful representations from both modalities. To enhance the model's ability to capture fine-grained cross-modal interactions, we propose a cascaded co-attention architecture, where co-attention modules are stacked or iterated to progressively refine the semantic alignment between text and audio. Experiments conducted on two public datasets show that the proposed method can achieve better performance than the state-of-the-art method. Specifically, our best performed co-attention model achieves a 16.6% improvement in mean Average Precision on Clotho dataset, and a 15.1% improvement on AudioCaps.